小米大模型应用团队发布 ControlFoley 开源模型,面向视频同步音效生成中的“可控性”难题,统一支持文本引导视频配音、文本控制视频配音和参考音频控制视频配音三类任务。
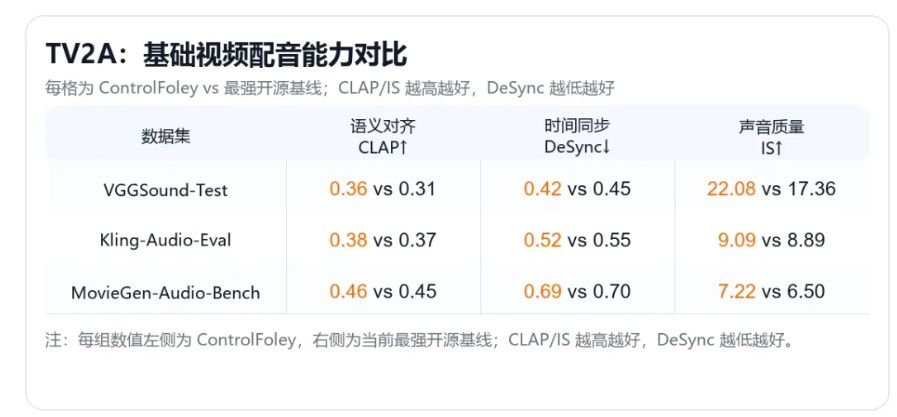
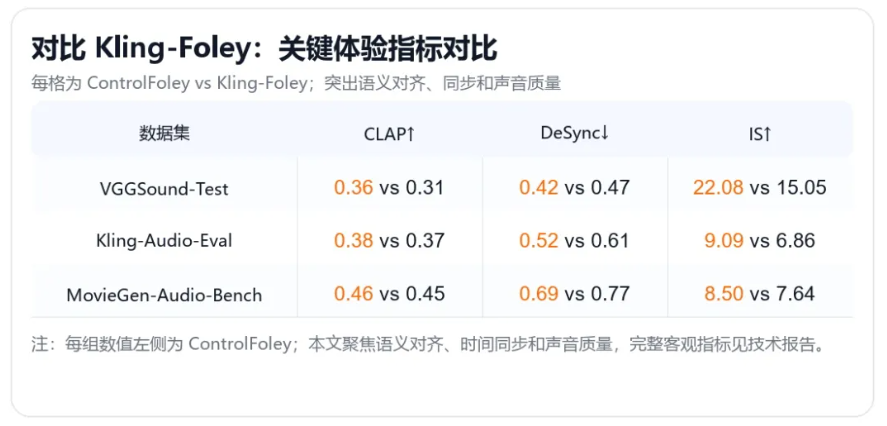
根据介绍,ControlFoley 在多个视频音效生成任务上达到开源 SOTA 表现,在语义对齐、时间同步、声音质量以及多模态控制能力上取得全面提升。代码、模型权重、技术报告、在线 Demo 和开箱即用 Skill 均已开放。
ControlFoley 的核心目标,是构建一个统一的可控视频音效生成框架,让模型同时具备三类能力:
- TV2A:文本引导视频配音。根据视频和文本提示生成同步音效,文本用于补充和细化画面中的声音语义。
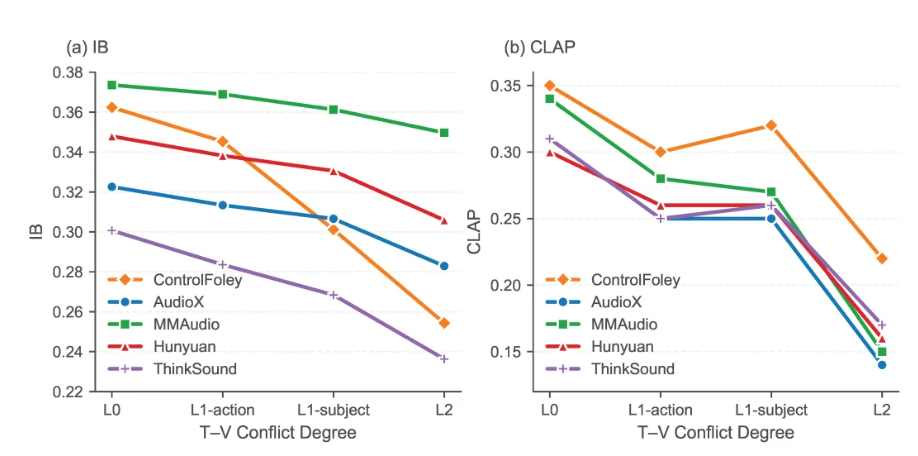
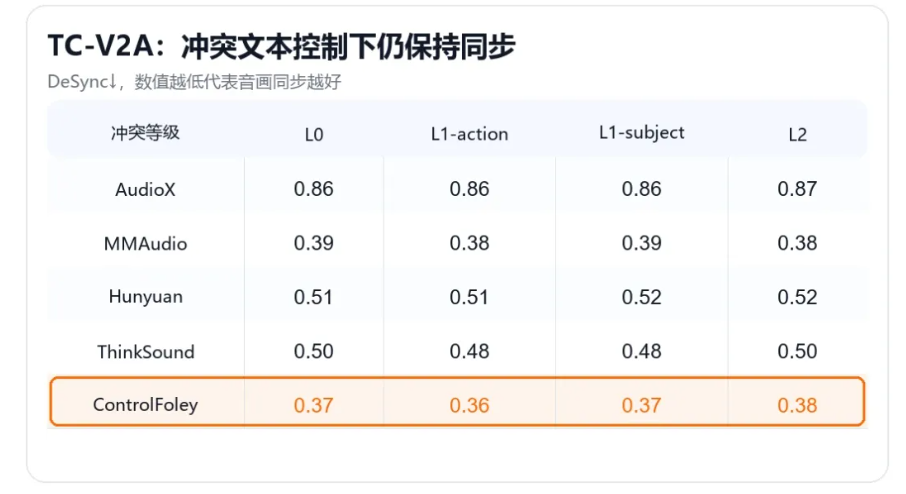
- TC-V2A:文本控制视频配音。当文本和视频语义发生冲突时,模型仍能遵循文本意图生成目标声音,同时保持和视频动作的时间同步。
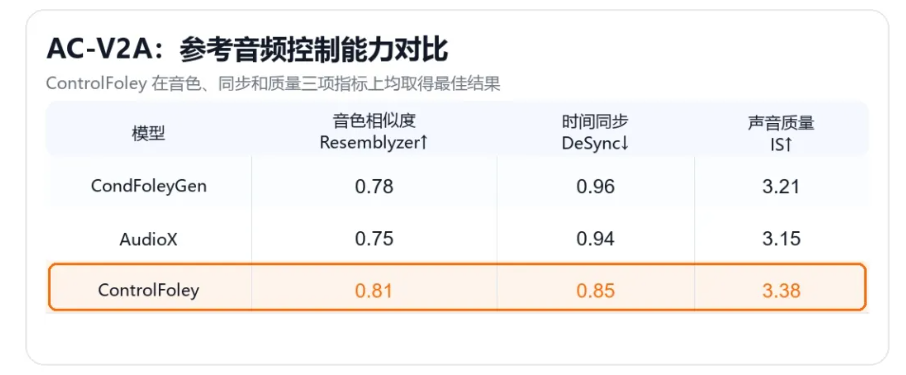
- AC-V2A:参考音频控制视频配音。根据视频和参考音频生成同步音效,让输出声音在音色和风格上贴近参考音频,同时不破坏视频节奏。
这意味着,ControlFoley 不只是一个“视频生音频”模型,而是一个面向创作控制的多模态音频生成模型。
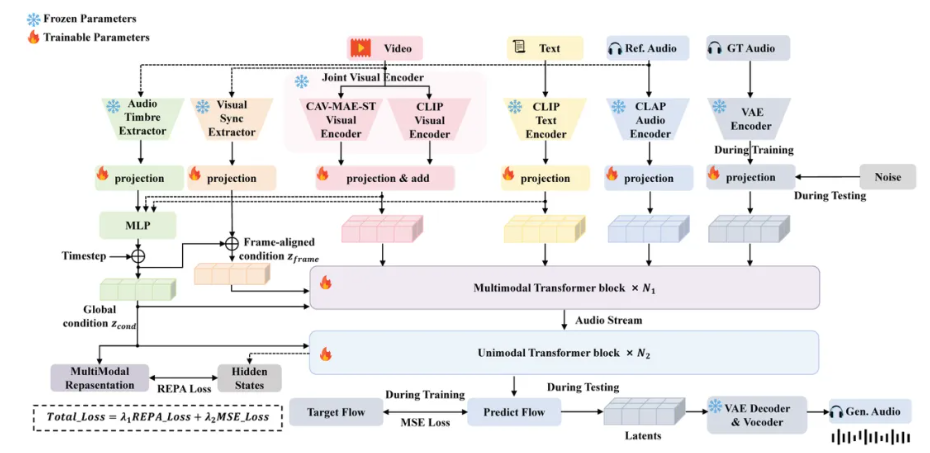
团队新提出并自训练了时空音视频编码器 CAV-MAE-ST,用来增强模型对音视频事件、动作节奏和时间同步关系的理解。
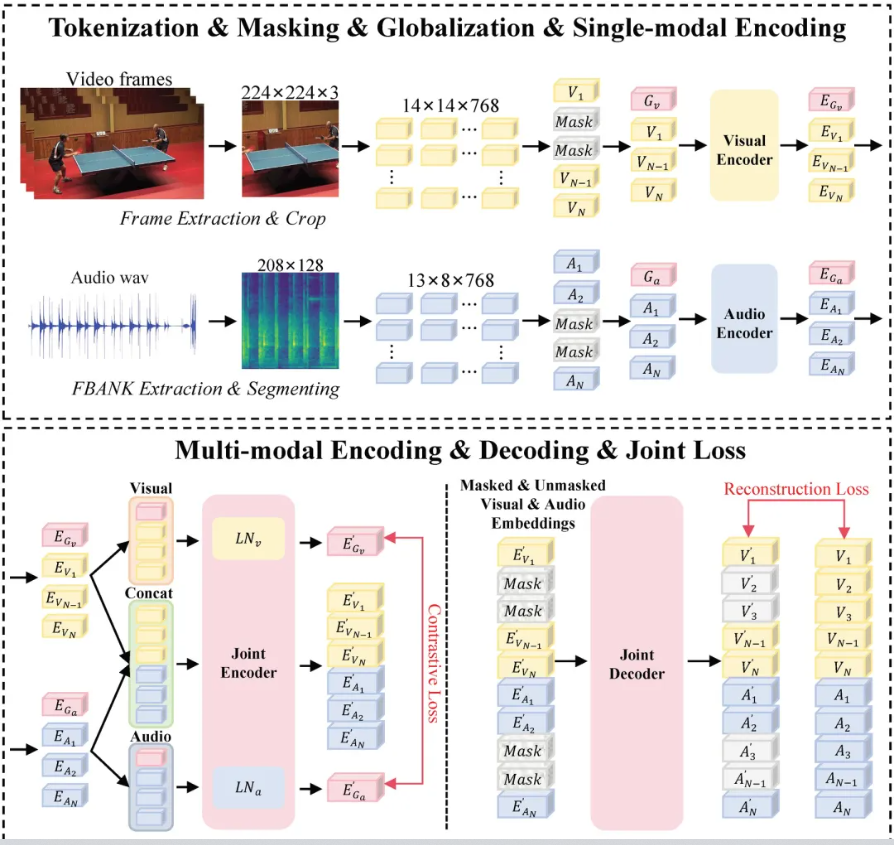
CLIP 更擅长理解视觉与文本之间的通用语义关系;CAV-MAE-ST 则面向视频配音任务重新设计和训练,更关注“动作什么时候发生、声音应该什么时候出现”这类音视频时空对应关系。它通过视频帧与音频特征的联合建模,帮助模型捕捉动作节奏、音频事件和时间同步线索。
二者结合后,ControlFoley 既能保留强音画同步能力,又能在文本与视觉发生冲突时更好地响应文本控制。这让模型在“画面是一回事,用户想要另一种声音”的场景下,不再只是被画面牵着走。
同时,ControlFoley 采用时间-音色解耦策略,抑制参考音频中冗余的时间信息,保留更关键的全局音色特征。这样一来,参考音频主要负责控制“声音听起来像什么”,视频则继续负责控制“声音什么时候发生”。
ControlFoley 还采用随机模态 dropout 和统一多模态表示对齐训练,让模型在不同条件组合下都能保持稳定。同时,模型通过统一 REPA 对齐目标,将生成音频的内部表示与聚合后的多模态条件对齐,提升语义一致性和控制鲁棒性。换句话说,ControlFoley 不是为某一个单点任务“特化”出来的模型,而是一个统一覆盖 TV2A、TC-V2A、AC-V2A 的多任务框架。