最近一位名为 Bookworm Engineer 的技术分析师在一篇长文中详细拆解了 DeepSeek 的战略意图——这不仅是一家前沿 AI 实验室,更在悄然构建一个足以撬动 10 万亿美元硬件生态的宏大体系。文中披露的诸多技术细节,揭示了 DeepSeek 如何通过算法创新重新定义 AI 硬件的竞争规则。

大模型落地面临的核心瓶颈之一,是推理阶段的海量 KV 缓存开销。当上下文窗口扩展到百万 token 量级时,主流模型的显存占用急剧攀升:GLM5 需要 60GB,Qwen3 更是达到 89GB,而 DeepSeek V4 仅仅需要 5.48GB——不到前两者的十分之一。这一数量级的差距,并非来自硬件升级,而是来自一系列精密的算法优化。
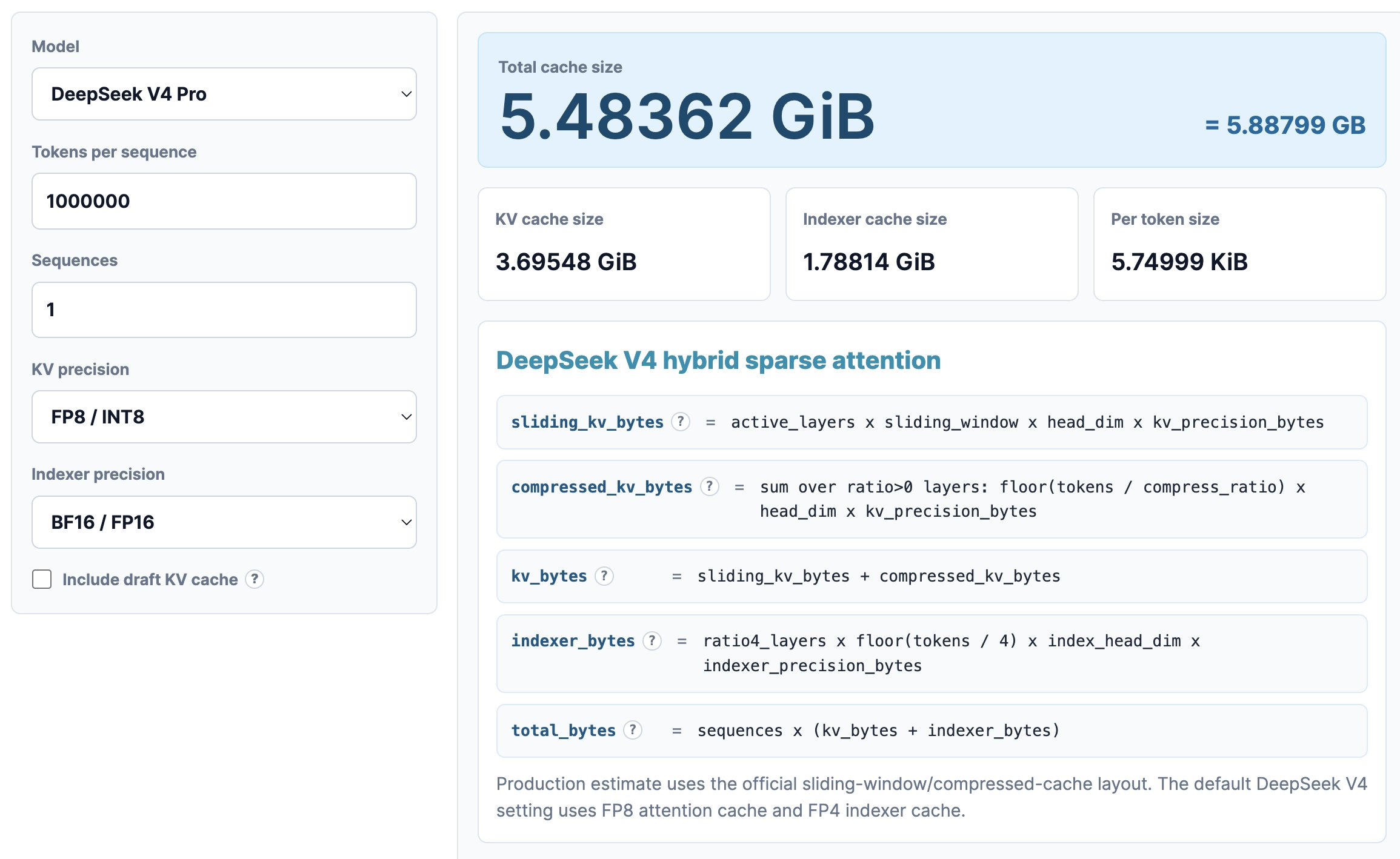
MLA(多头潜在注意力机制)是 DeepSeek 的核心技术之一。它通过低秩分解将键值矩阵压缩到潜在空间,大幅降低推理时的显存占用。DSA(疏散注意力)则进一步优化了注意力计算的稀疏性,避免了全连接注意力带来的冗余计算。CSA(因果注意力)等改进则确保了压缩过程中的信息完整性不被破坏。这些技术并非孤立存在,而是共同构成了一套协同优化的系统架构。
特别值得关注的是 HCA(混合压缩注意力)机制。传统观点认为,KV 缓存的压缩必然带来精度损失,但 HCA 通过混合多层次的压缩策略,在压缩率与模型性能之间找到了新的平衡点。这一设计思路的根本创新在于:不是用更多的硬件去弥补效率不足,而是用更聪明的算法去压榨硬件的每一分潜力。
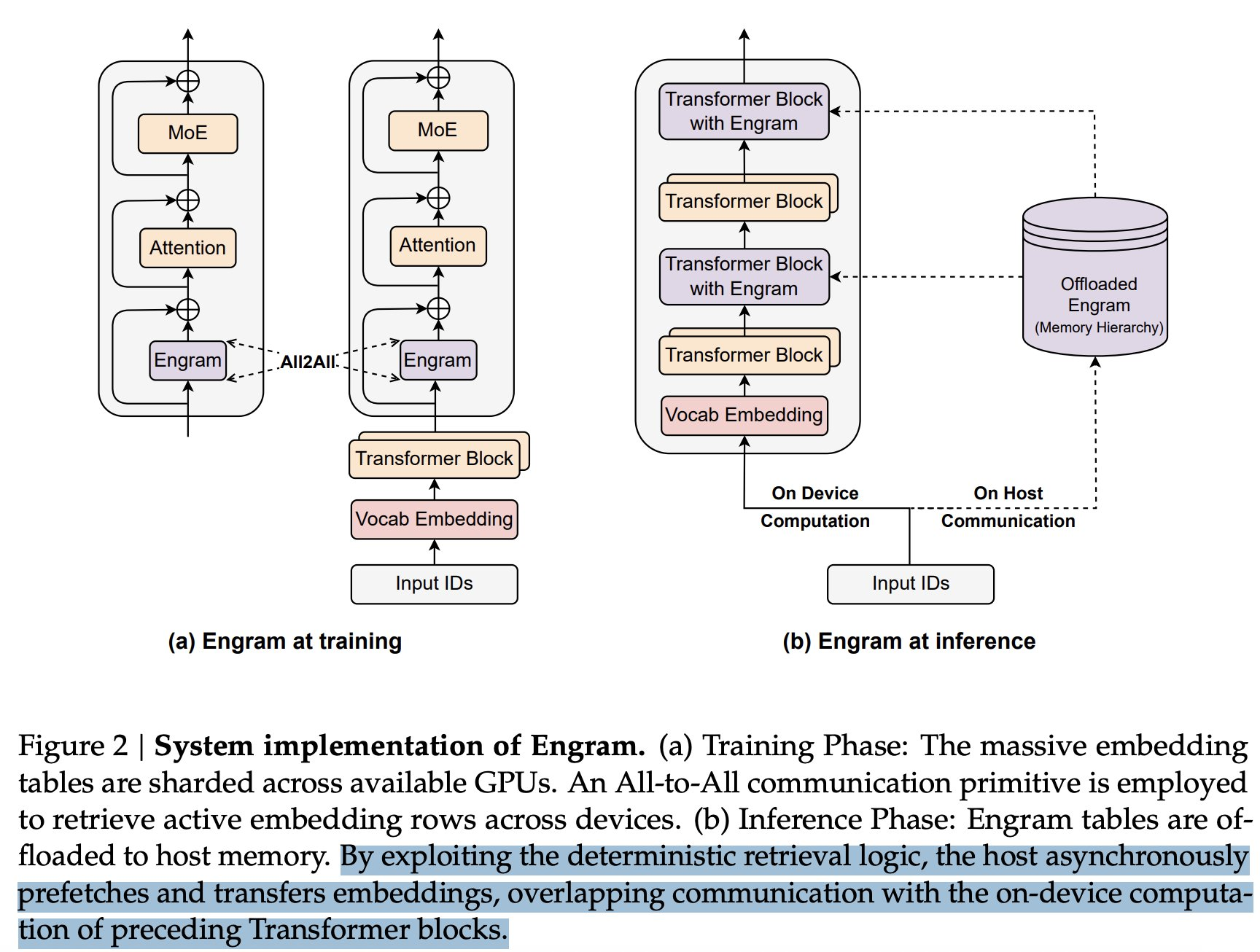
Engram 则是 DeepSeek 在内存-计算权衡(memory-compute trade-off)上的又一次突破。传统架构中,模型权重需要全部加载到高速显存中,但 Engram 允许将部分冷数据offload 到 NAND 闪存或 SSD,在需要时再调度回高速内存。这意味着推理不再高度依赖昂贵的 HBM 显存容量,中低端存储介质同样可以承载大规模模型的运行。
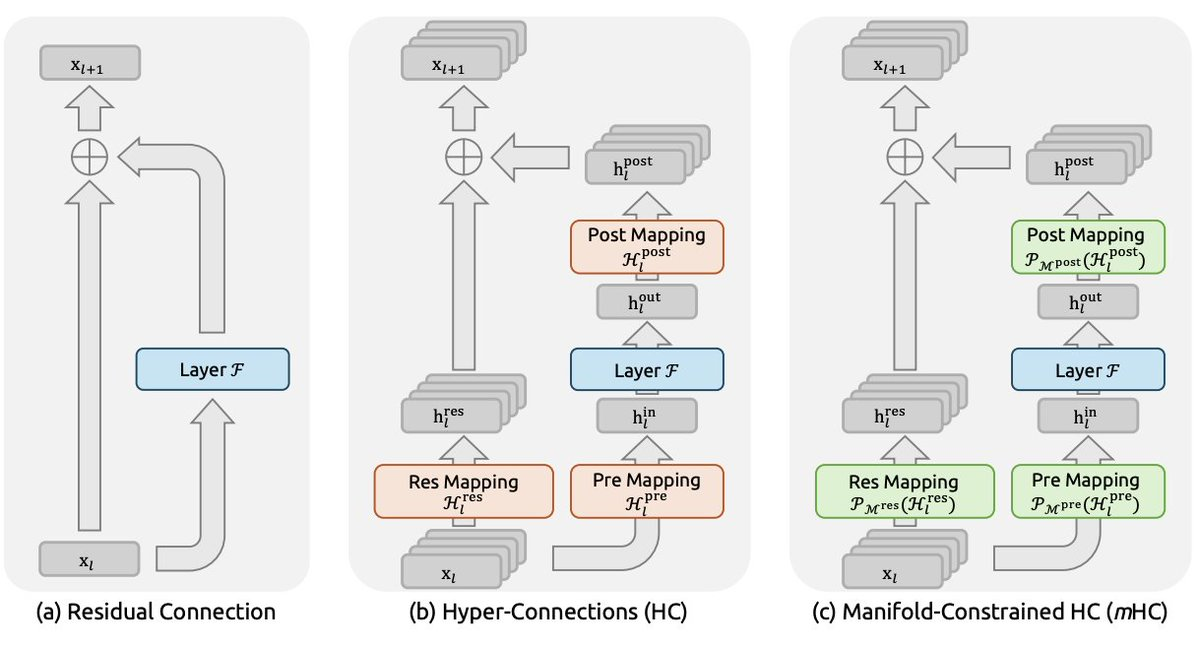
mHC(混合层级压缩)则为训练阶段带来了稳定性保障。在超大规模 MoE(混合专家)模型的训练中,梯度的不稳定是主要难题之一,mHC 通过分层压缩策略平滑了梯度流,使得万亿参数级别的训练得以稳定收敛。这一技术对于需要持续迭代模型能力的商业公司而言,是规模化训练的关键基础设施。
在硬件生态层面,DeepSeek 的布局同样耐人寻味。NAND 闪存和 SSD 的大规模应用,使得 KV 缓存可以 offload 到廉价存储;LPDDR(低功耗双倍数据率内存)则被用于权重流式传输,进一步降低了对高端显存带宽的依赖。这一组合意味着:中国现有的成熟存储芯片和内存产业,无需等待高端 HBM 的突破,就可以承接 AI 大规模落地的需求。

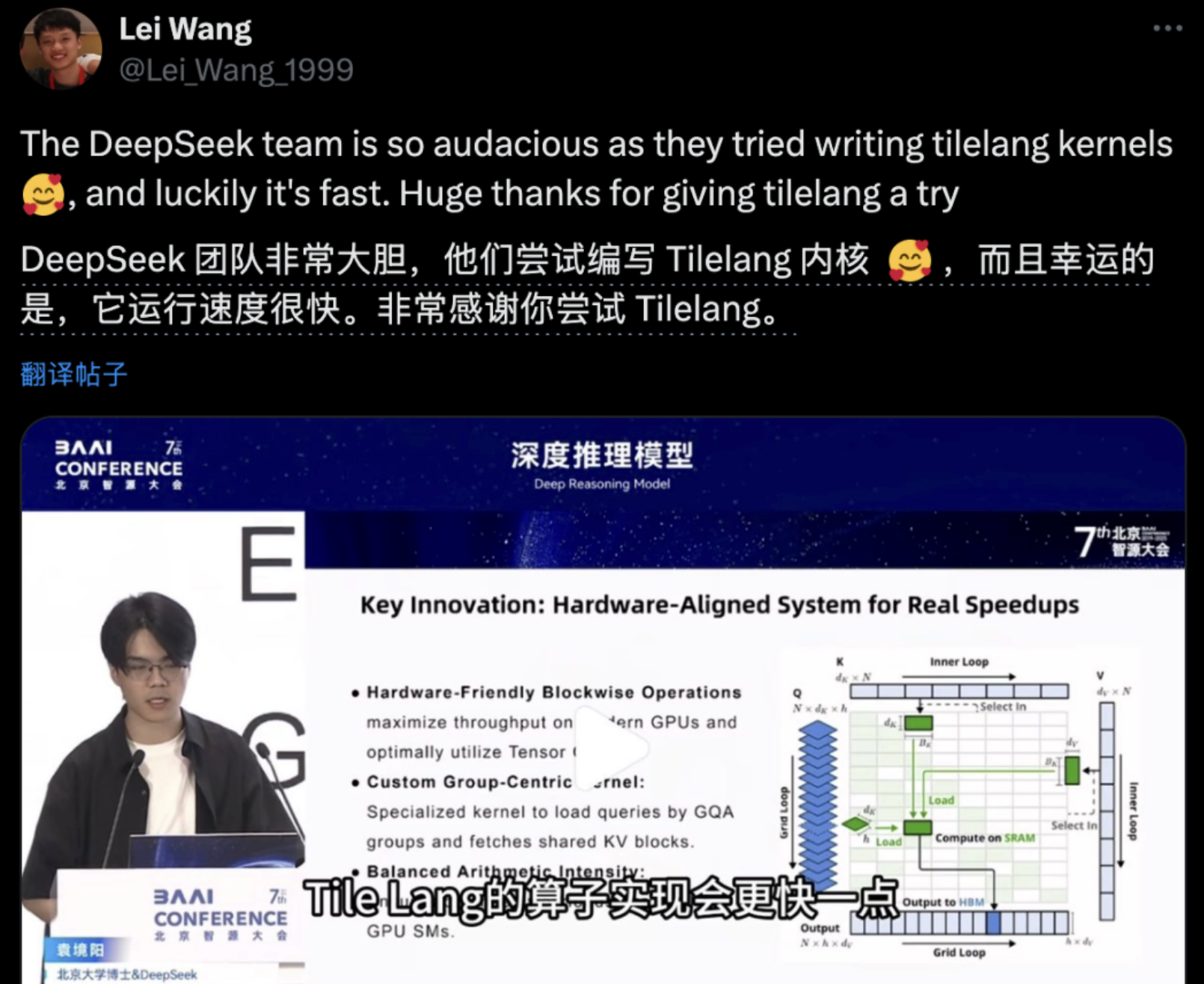
TileLang 是这一战略的黏合剂。它并非一门全新的编程语言,而是一种面向硬件可移植性的中间表示层,使得同一套模型代码可以在不同硬件平台上高效运行。无论是华为昇腾、寒武纪,还是其他国产 AI 芯片,只要支持 TileLang,就可以接入 DeepSeek 的软件生态。这意味着算法创新不再是 Nvidia 的专属护城河,而是可以普惠到整个中国硬件产业链。
从商业逻辑看,DeepSeek 的目标清晰而深远:通过算法压缩,让中低端国产硬件能够运行世界一流的大模型,从而激活一个价值万亿美元的中国 AI 硬件生态。如果这一战略得以实现,DeepSeek 自身有望成为首家估值突破万亿美元的中国 AI 公司——而这,不再是算力的军备竞赛,而是软件定义硬件的新范式。
参考来源:https://x.com/bookwormengr/status/2057909493250539891
