混元翻译模型 Hy-MT2 宣布正式开源,包含 3 个尺寸:Hy-MT2-1.8B、Hy-MT2-7B、Hy-MT2-30B-A3B,三个模型均支持33个语种互译,5种民汉/方言。
同步还开源了一个翻译指令遵循测试集 IFMTBench。测试集中的指令主要是和翻译任务相关,例如翻译风格变换、指定术语翻译等,指令和待翻译的文本涵盖了多个语种。
以及推出基于 Hy-MT2 打造的「腾讯Hy翻译」小程序,支持语音输入,优化了自定义翻译风格和指令的能力。用户不仅可以在联网环境下体验高速版的混元翻译模型,也可以通过提前下载端侧翻译模型,在无网络或者弱网络场景中使用离线翻译,解决了部分应用场景中网络条件受限的问题。
公告称,相较上一代翻译模型 Hy-MT1.5,Hy-MT2 效果提升明显,尤其在多语言指令遵循、专业领域翻译和真实应用场景翻译中表现较好,追平甚至超过大尺寸通用模型。
腾讯 Hy 翻译 APP 也正在上架中,预计很快会对外提供服务。
在通用翻译能力评测中,Hy-MT2系列三个模型在 FLORES-200 平均表现上分别达到目前行业表现最好的翻译模型 (Gemini 3.1 Pro )的 88.1%、 96.9% 和 98.1% 水平。
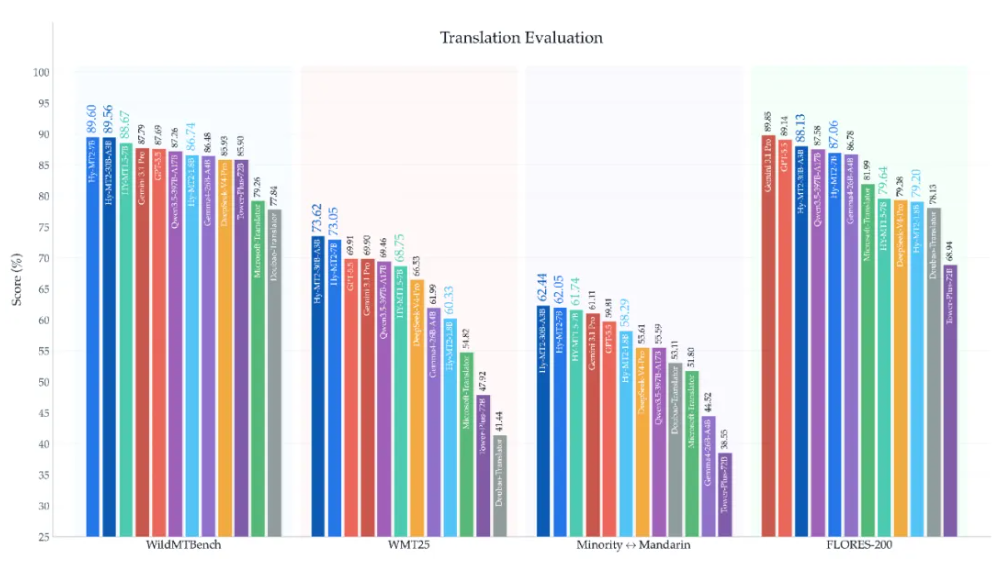
Hy-MT2-1.8B 和 Hy-MT2-7B 的 GEMBA 评分(基于大语言模型的翻译质量自动评估指标)分别达到 Gemini 3.1 Pro 的 96.7% 和 99.9%水平,并且这一场景下Hy-MT2-30B-A3B 效果已经超过 Gemini 3.1 Pro。
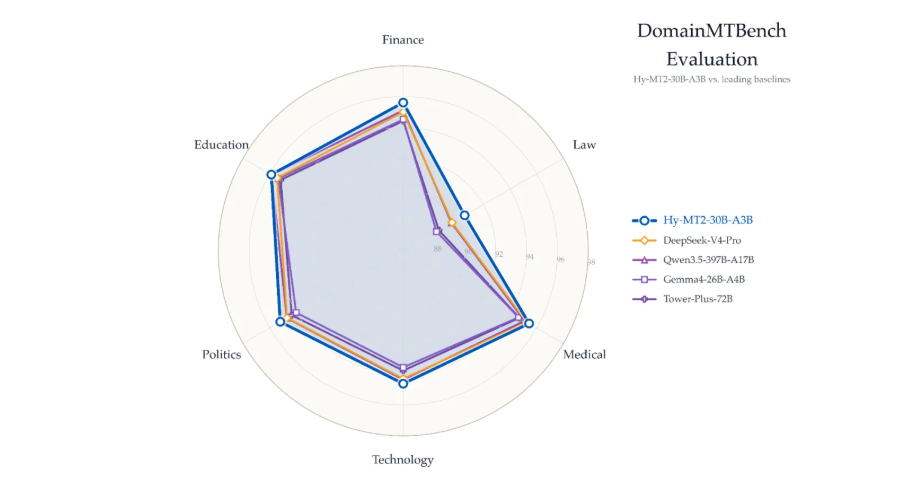
在涵盖 8 个专业领域的 DomainMTBench 上,三个模型的 GEMBA 评分分别达到 Gemini 3.1 Pro 的 96.2%、97.9% 和 99.0%水平。
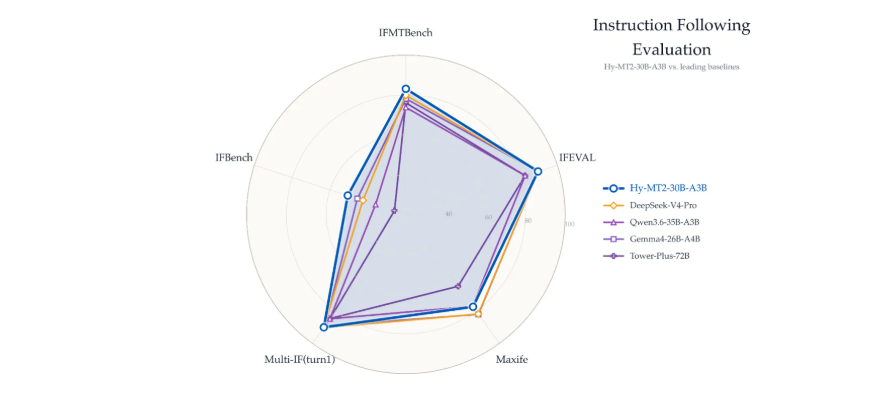
相比上一版本模型,Hy-MT2的最大提升体现在指令遵循能力上,模型能够更准确地理解并执行用户关于术语、风格和输出格式等方面的具体要求。腾讯混元自建数据集IFMTBench测试结果表明,Hy-MT2-7B和 Hy-MT2-30B-A3B的翻译效果已经超越等相近尺寸开源模型,接近 Gemini 3.1 Pro。
跟此前模型不一样的是,为在翻译效果和推理效率之间取得更好的平衡,Hy-MT2首次引入混合专家架构,推出 Hy-MT2-30B-A3B,通过扩大总参数规模提升模型容量,同时控制每次推理时的激活参数量,在增强翻译质量的同时降低推理开销,相比单纯扩大稠密模型规模,这种设计更适合面向真实应用场景的高质量翻译系统。
此外,上一版本的模型Hy-MT1.5-1.8B虽已提供 4-bit量化版本,但该版本仍需要 1GB 以上的存储空间,在移动端、边缘设备和其他资源受限环境中存在一定部署压力,并且其推理速度也难以充分满足部分低延迟翻译场景的需求。
除4-bit、8-bit 和 FP16 版本外,Hy-MT2还基于混元自研技术提供了 1.25-bit和2-bit版本,以适配不同硬件环境下的部署需求。基于混元自研Sherry 框架实现的1.25-bit 极低比特量化版本仅需约 440MB 存储空间即可部署,并且在苹果 A15 上的推理速度相比 Hy-MT1.5 的 4-bit 量化版本提升了 1.5 倍。
