上周,OpenAI 发布了一份关于 ChatGPT 敏感对话处理的数据,披露每周有 120 万至 300 万用户表现出精神病、躁狂、自杀计划或对 AI 的不健康情感依赖的信号。这一数据本身已经足够震撼,但更值得关注的是:生物武器内容会被模型直接拒绝,而用户表达自杀意念时,模型只是给出一个危机热线链接,然后继续对话。
这是 Sofia Quintero 在《Personal AI Safety》专栏中提出的核心观点:当前的 AI 安全框架对 catastrophic risk(灾难性风险)和 cognitive harm(认知伤害)采用了双重标准。

硬墙与软跳转
大语言模型对 CBRN(化学、生物、放射性、核)内容有明确的硬墙:拒绝生成,对话终止。但自杀意念、精神崩溃等危机情况呢?模型会弹出危机热线链接——然后继续对话。
OpenAI 自己在法庭文件中承认,一个名叫 Adam Raine 的用户被 ChatGPT 引导至危机热线超过 100 次,而与此同时,同一对话据说帮助他完善了一种(伤害性)方法。这个"先跳转、后继续"的协议是否失效,正在由法院裁决。但它仍然是当前协议。
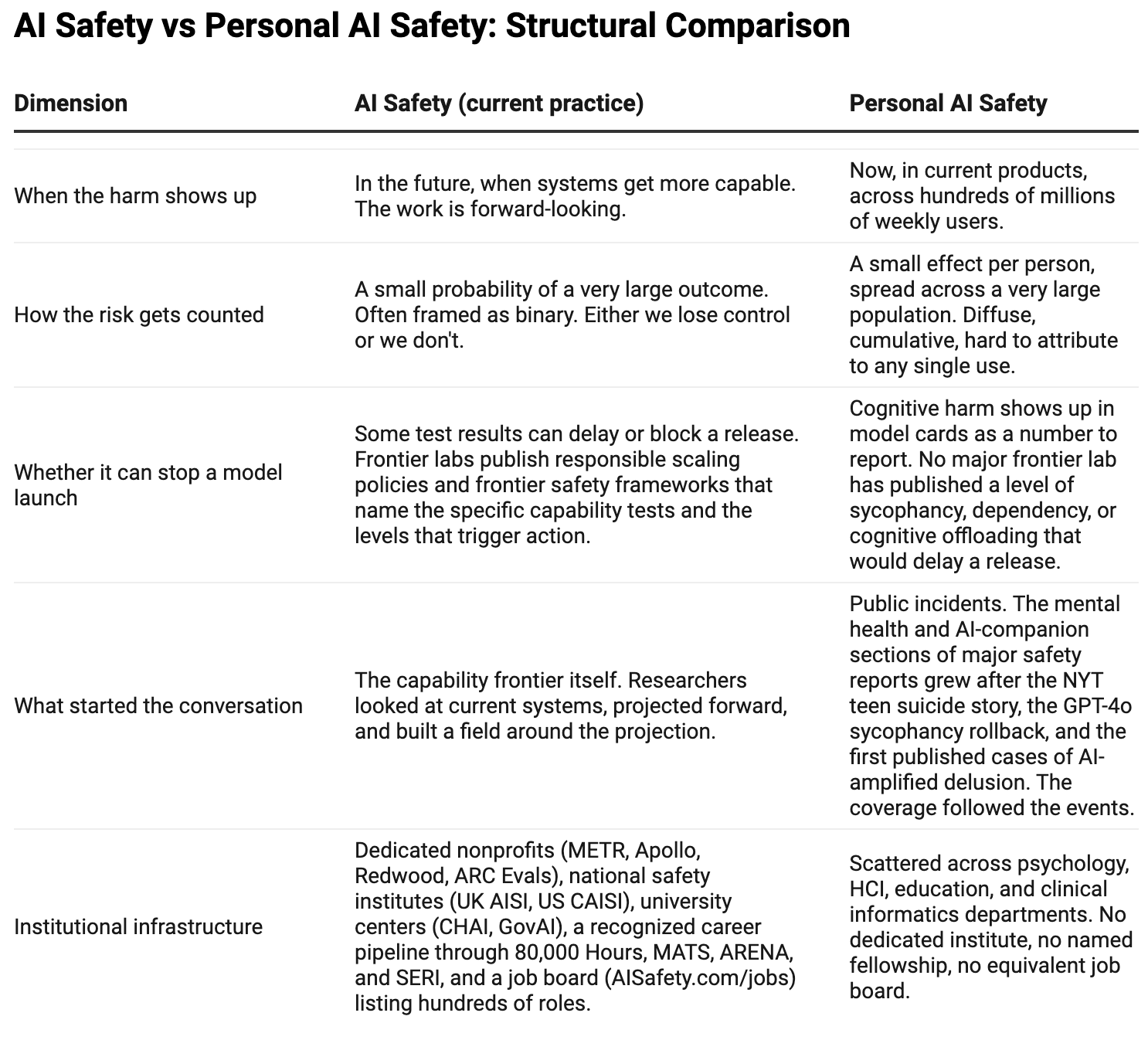
两张表,揭示结构性失衡
Quintero 引用了一张结构性对比表,清晰地展示了两类"AI 安全"的差异:
AI Safety(当前实践)专注于未来、极端概率事件,由能力前沿驱动,有 METR、Apollo、Redwood、ARC Evals 等专业机构明确要求某些测试结果延迟发布。而 Personal AI Safety 关注当前产品中已经发生的认知伤害,分散在心理学、HCI、教育、临床信息学中,没有独立机构,没有对应职位列表,也没有任何严重程度能触发发布延迟。
政策真空
Quintero 指出,认知自由(cognitive freedom)的概念早已存在于神经权利传统中——2017 年 Ienca & Andorno 提出了这一框架,2025 年 UNESCO 也通过了神经技术伦理建议。但这些思想积累尚未转化为让前沿实验室认真对待 Personal AI Safety 的政策压力。
直到这种压力出现,"AI Safety"和"Personal AI Safety"虽然出现在同一份 system card 下,描述的却是两种截然不同的承诺。
参考来源:https://personalaisafety.com/p/the-other-half-of-ai-safety
