Doubao-Seed-2.0-lite 宣布升级新版本,这是豆包大模型家族首款全模态理解模型,支持视频、图像、音频、文本原生统一理解,Agent、Coding 与 GUI 能力同步升级。
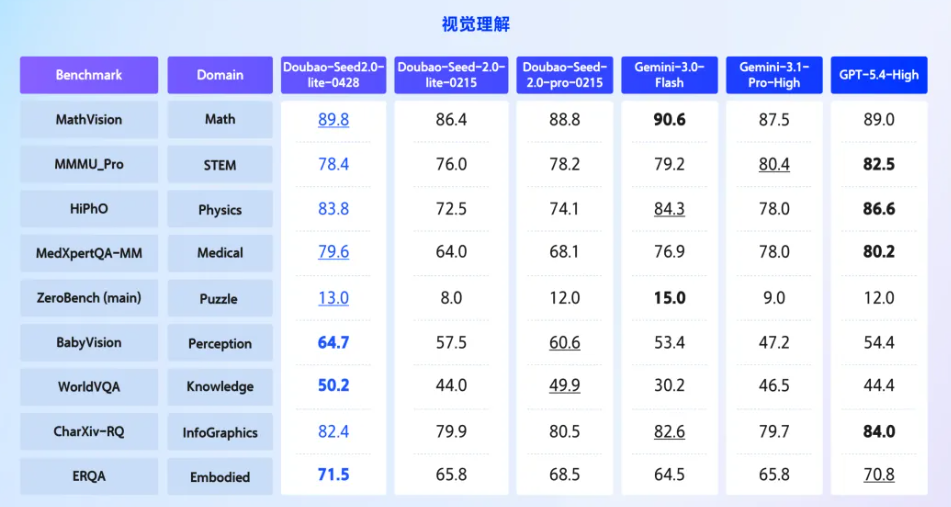
根据介绍,新版本的 Doubao-Seed-2.0-lite 继续在视觉理解能力上大幅提升,在物理(HiPhO)、医疗(MedXpertQA)等高阶学科推理上,表现大幅超越2月发布的 Doubao-Seed-2.0-pro。在细粒度感知(BabyVision、WorldVQA)与具身理解(ERQA)等关键领域达到 SOTA 水平,更适合企业在高价值场景规模化部署。
融入语音理解后,新版本的 Doubao-Seed-2.0-lite 可同时理解多种输入模态,并完成跨模态联合推理,直接处理必须“音画结合”才能判断的复杂业务需求。
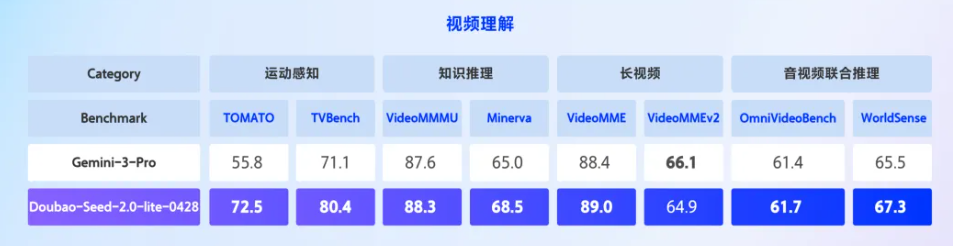
在视频理解场景下,模型能够联合分析视频中的画面与音频信息,精准辨析视频中的视听一致性,判断“看到的”与“听到的”是否一致。
同时支持根据自然语言指令,在视频中精准定位特定事件发生的时间点;更能跨越多个时间段提取关键线索,持续追踪人物与事件发展,并基于画面进行多步逻辑推理,还原事件关系与行为脉络。
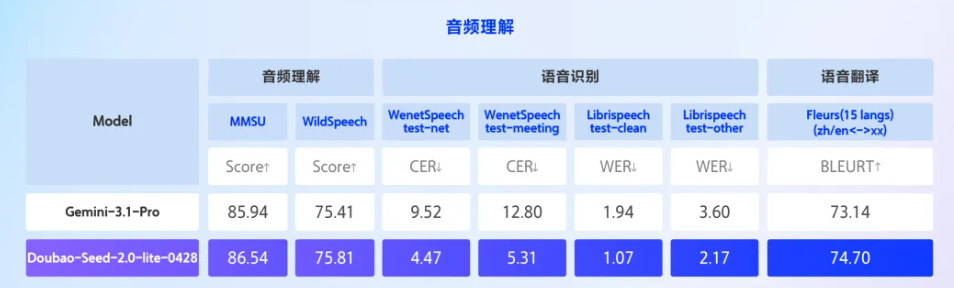
在音频上,模型支持19个语种的精准语音转写、中英文与其他14个语种互译,还能深度捕捉语音中的情绪变化、环境背景声与音乐细节,输出更完整、更接近人类认知的语义信息。根据公开评测集,Doubao-Seed-2.0-lite 在语音识别、翻译等多项音频理解基准上优于 Gemini-3.1-Pro。
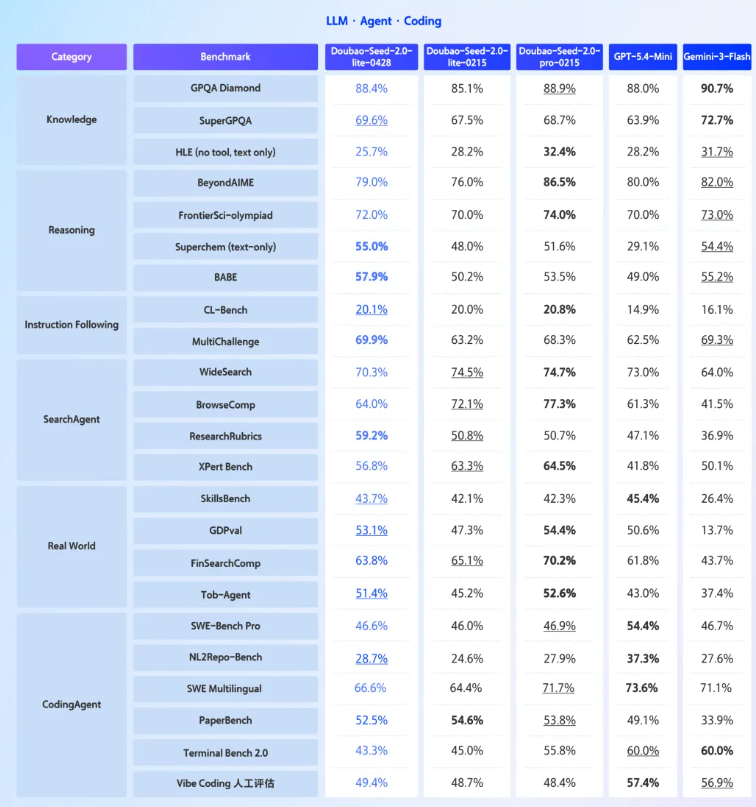
Doubao-Seed-2.0-lite 对多轮、多步、多约束的用户指令遵循度显著提升;继续增强任务反思推理与多 Agent 协同调度能力,让 Agent 在长程任务中自我拆解、自我校验,不偏题、不遗漏。
Doubao-Seed-2.0-lite 深度适配 OpenClaw、Hermes Agent 等框架,强化深度搜索与 Skill 动态调用,可边执行、边沉淀经验,越用越聪明。
模型的 Coding 能力全面覆盖前端页面、3D 场景与游戏开发,交付产物在视觉美观度与工程完整度上进一步提升,胜任从原型到上线的前后端深度开发。
基于升级的 GUI 能力,Doubao-Seed-2.0-lite 将“看懂界面”与“动手操作”打通为一条闭环:既能精准识别按钮、菜单、表单、弹窗等界面元素及其状态,也能稳定完成点击、输入、右键、滚动、拖拽等 Browser Use 与 Computer Use 操作。从读懂一张网页,到跨应用、跨窗口连续执行一整套业务流程。
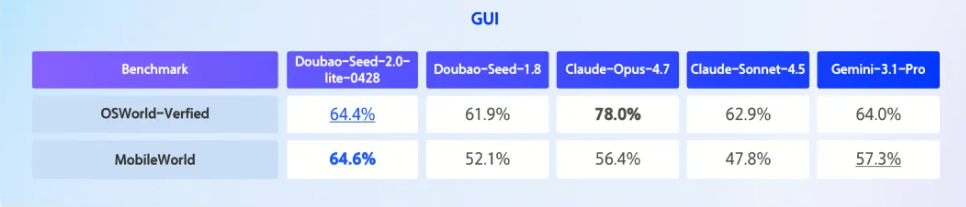
目前,这一技术已在电竞复盘、在线教育及跨境电商等多个领域落地。
