通义实验室宣布正式推出 Fun-ASR1.5,实现了「方言工业级可用」的语音识别大模型。
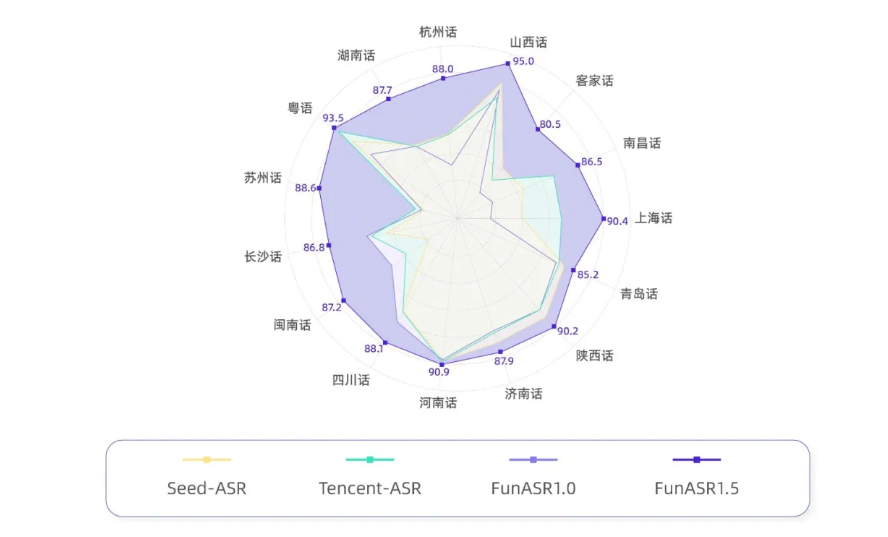
Fun-ASR1.5 基于统一的大模型架构,单模型即可无缝覆盖 30 种语言、汉语七大方言体系及 20+ 地方口音,古诗词吟诵也能精准转写。测试显示,典型方言场景字错误率(CER)相对下降 56.2%。目前已有 5 种方言准确率突破 90%,15 种超过 80%。
根据介绍,Fun-ASR1.5 聚焦“听得更全、听得更准、输出更规范”三大目标,实现从“通用转写工具”向“多语言、多文化理解平台”的关键演进。Fun-ASR1.5 基于超 数十万小时真实方言语音数据训练,涵盖日常对话、地方新闻、乡村政务等多场景。
模型支持汉语传统七大方言体系(官话/吴/湘/赣/客/闽/粤),并深度适配 20+ 地区口音官话,覆盖中原、西南、冀鲁、江淮、兰银、胶辽、东北、北京、港台等,包括河南、陕西、湖北、四川、重庆、云南、贵州、广东、广西、河北、天津、山东、安徽、南京、江苏、杭州、甘肃、宁夏 等 20 多个地区。
测试显示,在典型方言音频上,Fun-ASR1.5 相比上一版本平均字错误率(CER)相对下降 56.2%。这一能力正在赋能县域教育直播、地方政务服务热线、方言文化纪录片制作等长尾但高价值的应用场景。
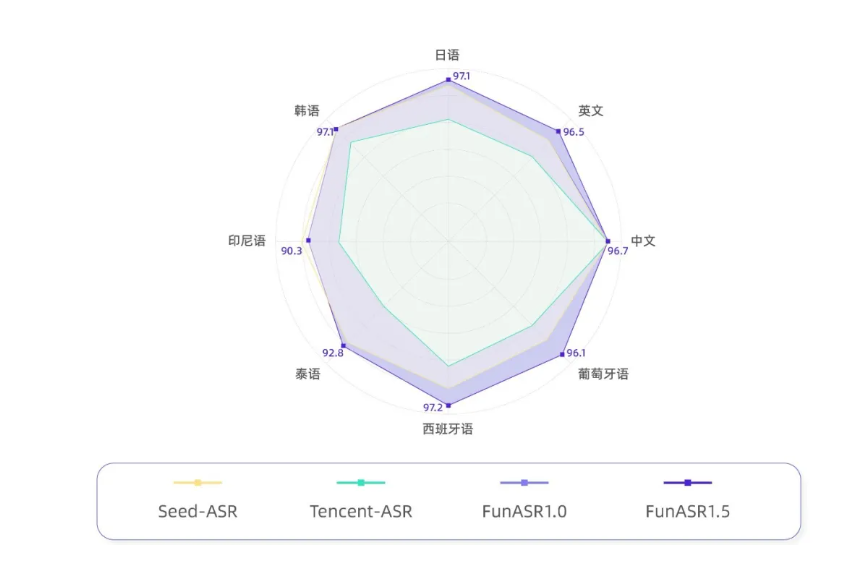
Fun-ASR1.5 支持 30 种主流语言的精准识别,包括:
- 东亚与东南亚:中文、日语、韩语、越南语、泰语、印尼语、马来语、菲律宾语
- 南亚与中东:印地语、阿拉伯语
- 欧洲主流语言:英语、法语、德语、西班牙语、葡萄牙语、俄语、意大利语、荷兰语、瑞典语、丹麦语、芬兰语、挪威语、希腊语、波兰语、捷克语、匈牙利语、罗马尼亚、保加利亚语、克罗地亚语、斯洛伐克语等
得益于统一的多语言训练框架,Fun-ASR1.5在混合语种对话、跨语言自由切换(Code-Switching)场景下表现尤为突出。模型可准确识别语音内容,无需预设语种标签。
此外,Fun-ASR1.5 对中文古诗词识别进行了专项优化。项目团队构建了覆盖先秦、汉魏、唐宋、元明清至近代的古诗词语音-文本对齐语料库,包含《诗经》《楚辞》、李白杜甫诗集、苏轼辛弃疾词作等经典文本的真人诵读录音,显著提升高频诗句的识别准确率。
在内部评测集中,Fun-ASR1.5 对古诗词的字符级准确率达到 97%。该能力已在国学在线课程、有声诗词APP等场景应用,未来有望助力中小学语文教育与非遗文化传承。
Fun-ASR1.5 还在后处理环节重点优化了两项能力:标点预测更加智能、文本归一化(ITN)表现进一步提升。
