项目仓库:cdkjframework/knowledge-base 许可证:MulanPSL-2.0
一、项目概览
WIKI 知识库是一款本地优先的私有知识库服务,集成了向量检索与**对话式问答(RAG)**能力。它通过 HTTP API 和 Web 界面向用户提供服务,支持 SSE 流式输出,并内置多用户会话管理、知识库文档管理、模型配置等完整功能。
核心特性
|
特性
|
说明
|
|
🏗️ 私有化部署
|
全量本地运行,数据不出网,适合企业级隐私场景
|
|
🔍 向量检索 + Rerank
|
FAISS 向量索引 + Reranker 二次排序,检索精度高
|
|
🤖 多 LLM 支持
|
OpenAI / DeepSeek / 通义千问 / 豆包 / xAI / Gemini / Kimi / LM Studio,统一接口切换
|
|
📄 多格式文档
|
支持 DOCX、DOC、PDF、XLS/XLSX、TXT、Markdown、图片 OCR 等
|
|
🔐 SSE 流式输出
|
打字机式实时响应,体验流畅
|
|
💬 多会话管理
|
基于 user_id + session_id 的会话隔离,支持 Redis 持久化
|
|
🌐 Web UI + API
|
内置 Web 界面 + 完整 REST API,开箱即用
|
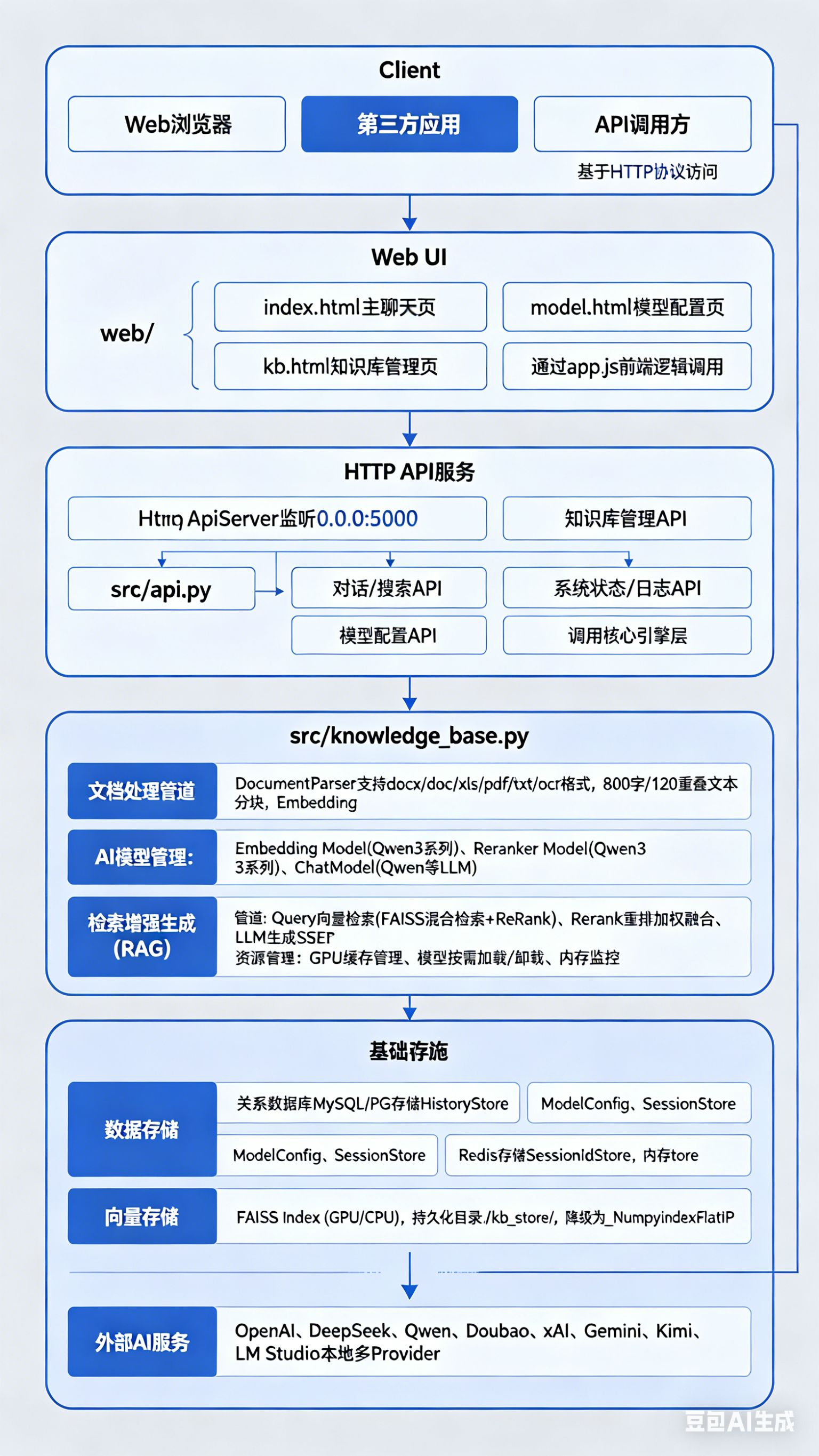
二、系统架构总览
2.1 整体架构图
系统采用分层架构设计,从上到下分为:
-
客户端/浏览器层 — 用户交互入口
-
HTTP API 层 (src/api.py) — 统一请求路由与鉴权
-
Web UI 静态资源层 (web/) — 前端界面
-
会话/历史存储层 (src/store/) — 会话状态与消息持久化
-
知识库核心层 (src/knowledge_base.py) — 文档解析、分块、Embedding、FAISS 索引、Reranker、Chat 模型
2.2 RAG 数据流
RAG 核心流程如下:
-
文档上传后,由 文档解析器 提取文本,并进行 分块
-
分块后的文本通过 Embedding 模型 生成向量,存入 FAISS 索引
-
用户提问时,问题先经 Embedding 转向量,在 FAISS 中检索候选文档
-
候选文档经 Reranker 二次排序后,与用户问题一起送入 Chat 模型
-
Chat 模型生成回答,通过 SSE 流式返回给用户
三、核心模块详解
3.1 项目目录结构
.
├─ src/
│ ├─ api.py # HTTP API 与静态资源路由
│ ├─ main.py # 启动入口
│ ├─ knowledge_base.py # 知识库核心逻辑
│ ├─ document_parser.py # 文档解析
│ ├─ universal_llm_client.py # 多模型统一客户端
│ ├─ model_config_manager.py # 模型配置管理
│ ├─ windows_service.py # Windows 服务入口
│ └─ store/ # 会话/历史存储实现
├─ web/ # 内置 Web 控制台
├─ docs/
│ └─ API.html # 离线 API 文档
├─ assets/ # README 截图与静态资源
├─ config.json # 主配置文件
├─ config.multi-provider.example.json
├─ manage_service.ps1 # Windows 服务管理脚本
├─ manage_service.sh # Linux systemd 服务管理脚本
├─ encrypt_secret.py # 密钥加密工具
├─ ingest_to_kb_store.py # 知识导入工具
├─ migrate_to_sessions_table.py # 历史数据迁移脚本
└─ tune_threshold.py # 检索阈值调优脚本
3.2 核心模块说明
📌 knowledge_base.py — 知识库引擎
这是整个系统的心脏,职责包括:
-
文档解析:调用 document_parser.py 提取各类文档的文本内容
-
文本分块:可配置块大小(默认 800 字符)和重叠(默认 120 字符)
-
Embedding 生成:使用本地 Embedding 模型(默认 Qwen3-Embedding-0.6B)将文本向量化
-
FAISS 索引构建:将向量存入 FAISS 索引,支持 GPU 加速
-
检索与 Rerank:向量检索候选文档 → Reranker 二次排序
-
对话生成:将检索结果与用户问题组装 Prompt,调用 Chat 模型生成回答
📌 universal_llm_client.py — 通用 LLM 客户端
统一的 LLM 调用层,通过 UniversalLLMClient 类屏蔽不同厂商 API 的差异:
|
提供商
|
支持模型
|
base_url
|
|
OpenAI
|
GPT-4, GPT-3.5-Turbo
|
https://api.openai.com/v1
|
|
DeepSeek
|
deepseek-chat, deepseek-coder
|
https://api.deepseek.com/v1
|
|
通义千问
|
qwen-max, qwen-plus
|
https://dashscope.aliyuncs.com/compatible-mode/v1
|
|
豆包
|
doubao-pro-32k
|
https://ark.cn-beijing.volces.com/api/v3
|
|
xAI
|
grok-beta
|
https://api.x.ai/v1
|
|
Gemini
|
gemini-pro
|
https://generativelanguage.googleapis.com/v1beta
|
|
Kimi
|
moonshot-v1-32k
|
https://api.moonshot.cn/v1
|
|
LM Studio
|
自定义模型
|
http://localhost:1234/v1
|
底层基于 OpenAI Python SDK 的兼容接口,上层支持对话、向量检索、Rerank 三类模型调用。
📌 document_parser.py — 文档解析器
支持以下格式的文档解析:
|
格式
|
解析方式
|
是否需要 OCR
|
|
DOCX
|
✅ 直接解析
|
❌
|
|
DOC
|
✅ 直接解析
|
❌
|
|
XLS / XLSX
|
✅ 直接解析
|
❌
|
|
TXT
|
✅ 直接解析
|
❌
|
|
Markdown
|
✅ 直接解析
|
❌
|
|
PDF
|
🔧 需 OCR 引擎
|
✅
|
|
图片
|
🔧 需 OCR 引擎
|
✅
|
|
OFD
|
🔧 需 OCR 引擎
|
✅
|
OCR 功能支持两种引擎:
📌 store/ — 存储层
采用接口抽象 + 多实现的设计模式:
store/ ├── interfaces.py # 存储接口定义├── memory_store.py # 内存存储(开发/测试用)├── db/ # 数据库存储(MySQL / PostgreSQL) └── redis/ # Redis 存储(会话持久化)
-
会话存储:支持 memory(内存)或 redis(持久化)两种后端
-
消息存储:支持 memory、mysql、postgresql 三种后端
-
当使用 Redis 作为会话后端时,Session ID 直接使用 Redis 键,支持独立部署的会话持久化
📌 api.py — HTTP API 层
基于 FastAPI 构建,提供完整的 RESTful API,包括:
-
知识库 CRUD(创建、删除、列表、文档上传)
-
对话接口(支持 SSE 流式)
-
模型配置管理
-
会话管理
API 文档访问地址:http://localhost:5000/api-docs 或 http://localhost:5000/docs/
四、配置体系
4.1 核心配置项 (config.json)
json
{ "server": { "host": "0.0.0.0", "port": 5000 }, "search": { "default_k": 2, "max_search_results": 3, "min_source_similarity": 0.55 }, "db": { "backend": "mysql", "mysql": {...}, "postgresql": {...} }, "session": { "backend": "redis", "redis": {...} }, "knowledge_base": { "embedding": { "model": "Qwen/Qwen3-Embedding-0.6B", "device": "auto" }, "rerank": { "model": "Qwen/Qwen3-Reranker-0.6B" }, "chat": { "model": "qwen/qwen3.5-35b-a3b", "use_lm_studio": true }, "lm_studio": { "base_url": "http://127.0.0.1:1234", "chat_model": "qwen/qwen3.5-35b-a3b" }, "chunking": { "size": 800, "overlap": 120 }, "retrieval": { "candidate_multiplier": 8, "min_candidates": 30, "embed_weight": 0.35, "rerank_weight": 0.65 } }, "chat_context": { "enabled": true, "max_turns": 6 }, "logging": { "level": "INFO", "keep_days": 7 } }
4.2 关键配置解读
|
配置项
|
作用
|
|
search.default_k
|
默认返回的文档片段数
|
|
search.min_source_similarity
|
最低相似度阈值,低于此值的候选将被过滤
|
|
knowledge_base.chunking.size/overlap
|
文档分块大小与重叠字符数
|
|
knowledge_base.retrieval.embed_weight/rerank_weight
|
Embedding 与 Rerank 的融合权重(0.35 + 0.65 = 1.0)
|
|
chat_context.max_turns
|
对话上下文最大轮次,控制历史消息长度
|
|
session.backend
|
会话存储后端,生产环境建议使用 redis
|
五、Embedding / Reranker 硬件需求
|
规格
|
内存
|
GPU
|
显存
|
推荐场景
|
|
0.6B
|
8 GB
|
16GB
|
≥ 6GB(可选)
|
轻量部署、CPU 可跑
|
|
4B
|
16 GB
|
32GB
|
≥ 12GB
|
中等规模、GPU 加速推荐
|
|
8B
|
24 GB
|
64GB
|
≥ 24GB
|
大规模、GPU 必选
|
生产建议:
-
Embedding 模型必须加载在显存中,GPU 不可用时可退回 CPU,但速度会大幅下降
-
模型权重与 FAISS 索引默认存放在 SSD 上,避免 HDD 影响加载速度
-
多用户并发场景下,务必将 session.backend 设为 redis
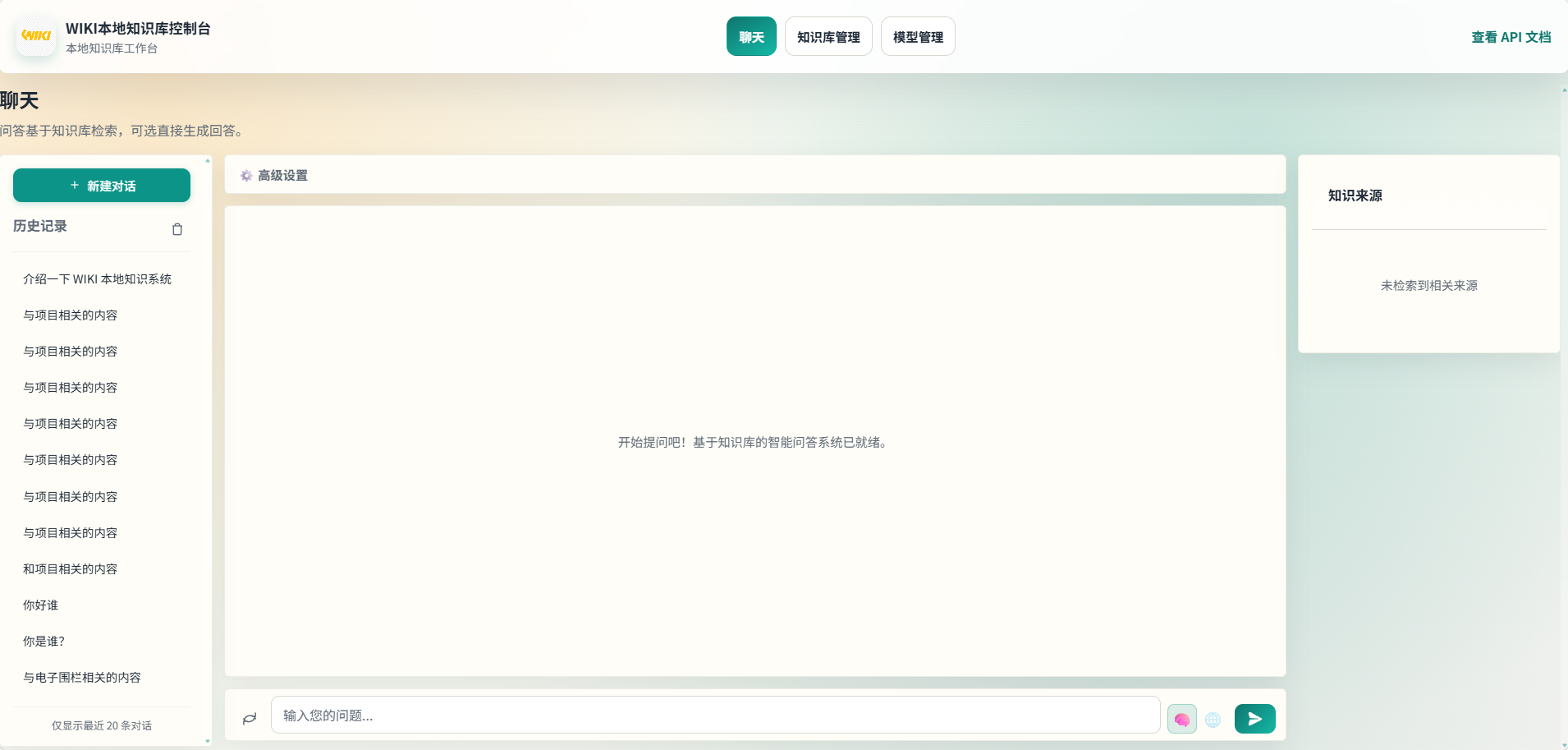
六、Web UI 界面展示
💬 对话界面
支持多轮对话、知识库关联、SSE 流式输出,对话历史自动保存。
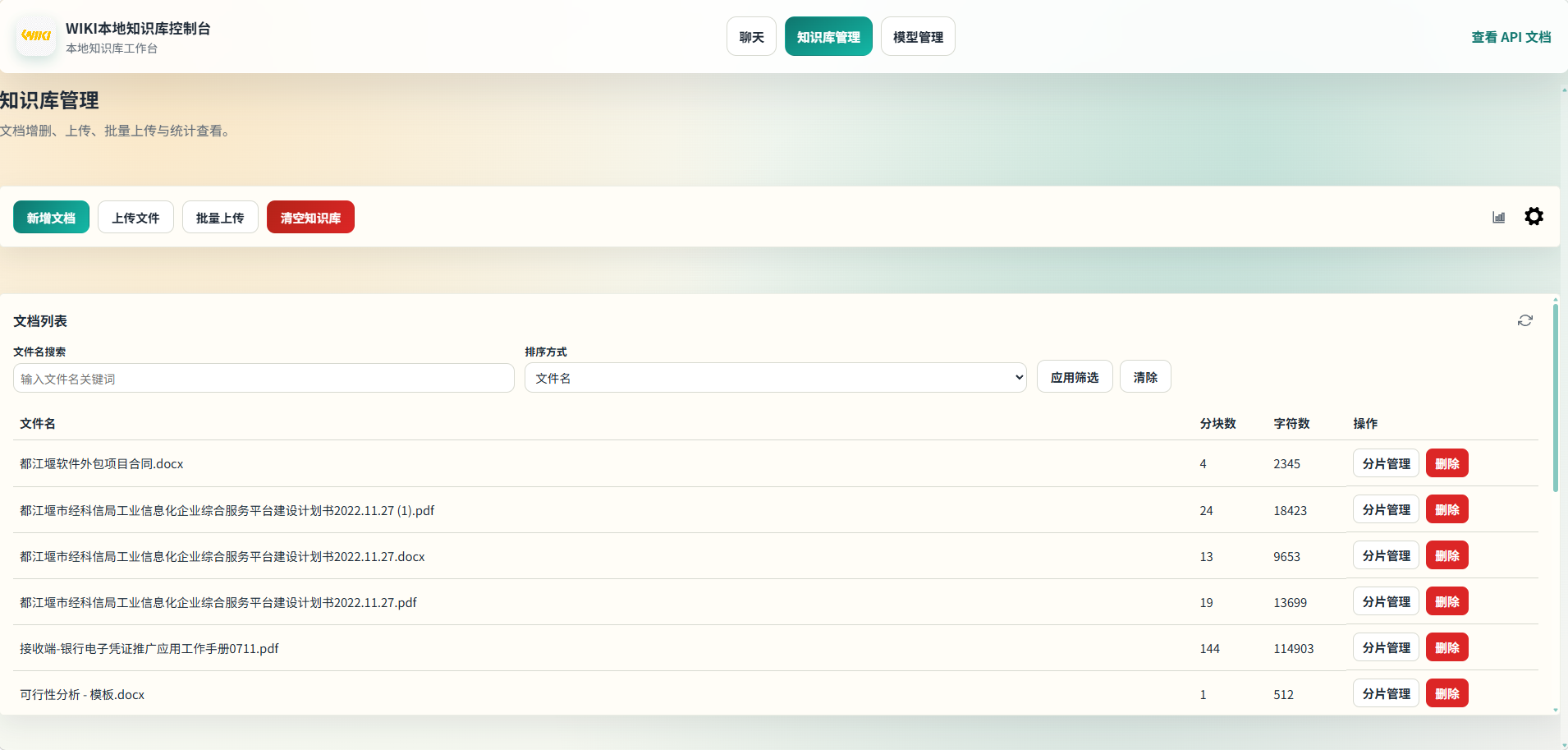
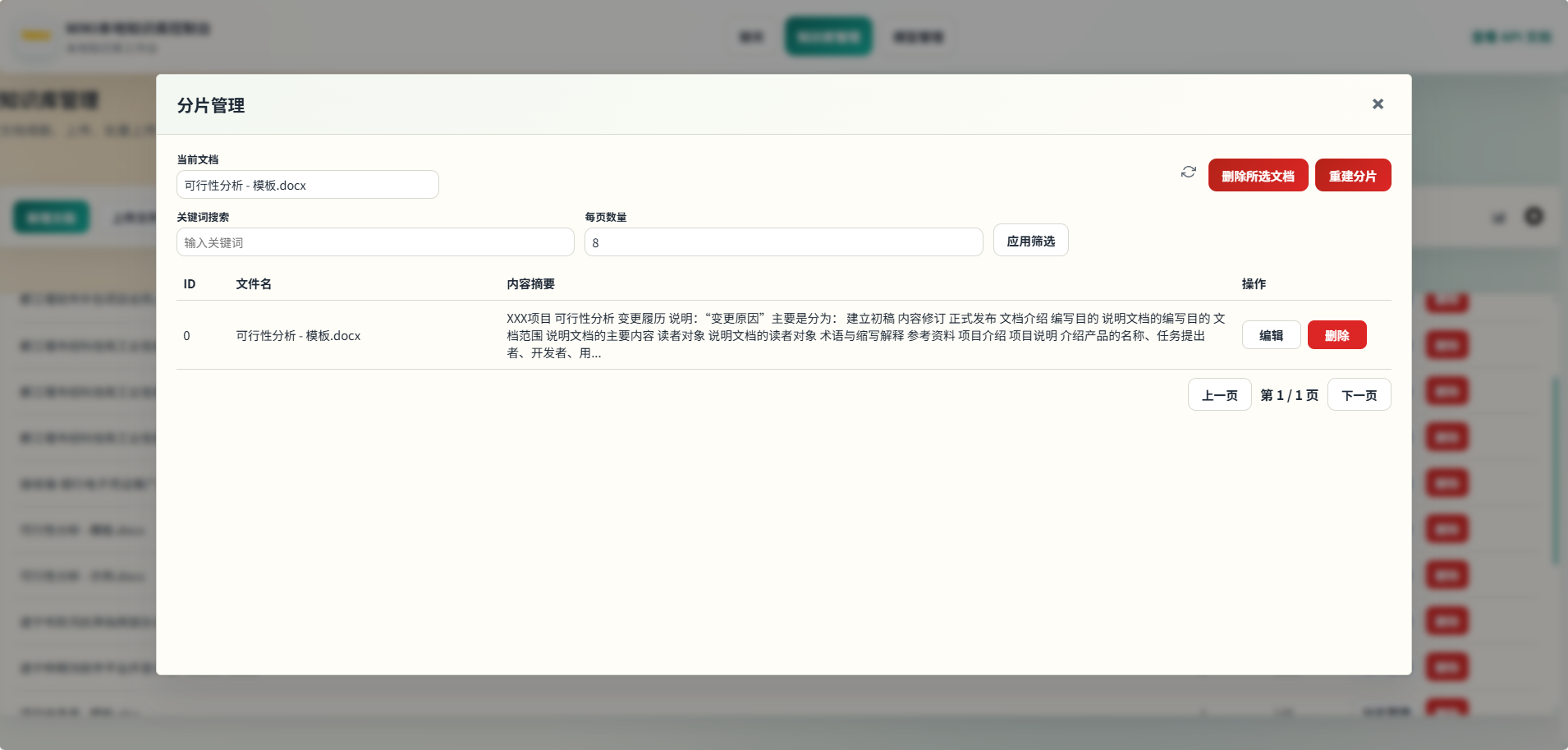
📚 知识库管理
支持知识库的创建、文档上传(批量)、删除、检索测试等操作。
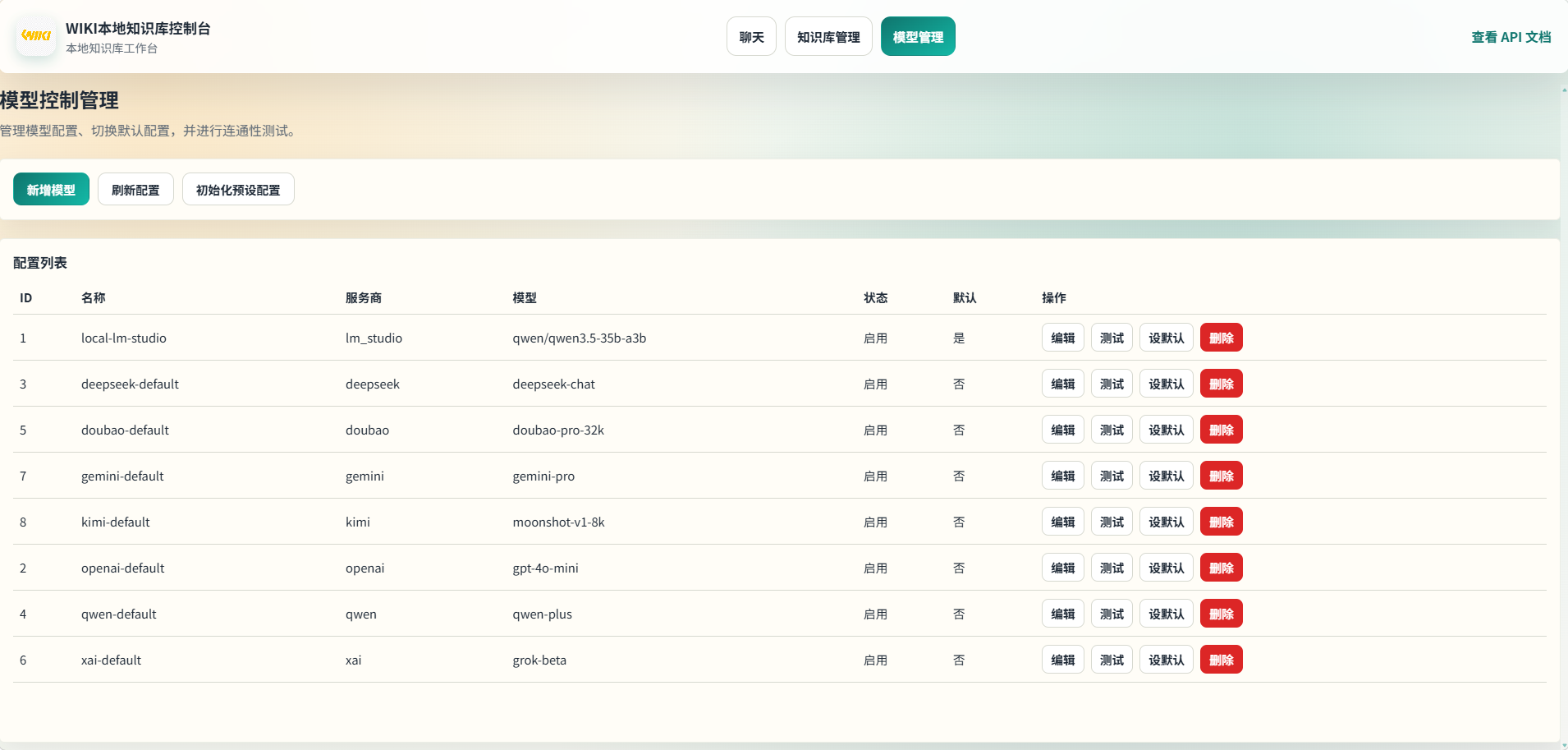
⚙️ 模型配置
可视化配置 Embedding、Reranker、Chat 模型参数,无需手动编辑 JSON。
七、功能矩阵
|
功能
|
状态
|
说明
|
|
知识库向量存储
|
✅
|
FAISS 索引
|
|
文档解析/OCR
|
✅
|
多格式 + 可选 OCR
|
|
多轮对话
|
✅
|
上下文记忆
|
|
SSE 流式输出
|
✅
|
打字机效果
|
|
Rerank 重排序
|
✅
|
提升检索精度
|
|
Web UI
|
✅
|
内置界面
|
|
API 服务
|
✅
|
REST + Swagger 文档
|
|
多用户会话隔离
|
✅
|
user_id + session_id
|
|
Redis 持久化
|
✅
|
会话/历史
|
|
数据库持久化
|
✅
|
MySQL / PostgreSQL
|
|
对话历史导出
|
-
|
待开发
|
|
MCP 集成
|
-
|
待开发
|
|
SLA 指标监控
|
-
|
待开发
|
|
分布式部署
|
-
|
待开发
|
八、快速上手
环境要求
安装与启动
bash
# 1. 安装依赖pip install -r requirements.txt # 2. 编辑配置# 修改 config.json 中的数据库、Redis、模型路径等# 3. 启动服务python -m src.main # 或使用自定义参数python -m src.main --host 127.0.0.1 --port 5000
服务启动后访问:
-
🏠 首页:http://127.0.0.1:5000/ui/
-
📚 知识库:http://127.0.0.1:5000/ui/kb.html
-
⚙️ 模型配置:http://127.0.0.1:5000/ui/model.html
-
📖 API 文档:http://127.0.0.1:5000/api-docs
常用命令行参数
|
参数
|
说明
|
|
--host
|
绑定地址
|
|
--port
|
绑定端口
|
|
--no-preload-embedding
|
启动时不预加载 Embedding 模型
|
|
--no-preload-reranker
|
启动时不预加载 Reranker 模型
|
环境变量
|
变量
|
说明
|
|
KB_CONFIG_PATH
|
自定义配置文件路径
|
|
KB_PRELOAD_EMBEDDING
|
是否预加载 Embedding 模型
|
|
KB_PRELOAD_RERANKER
|
是否预加载 Reranker 模型
|
|
KB_WARUMUP_STRICT
|
模型预热是否严格模式
|
九、安全建议
-
API Key 加密:config.json 中的 API Key 和数据库密码使用 encrypt_secret.py 工具加密存储
-
生产部署:务必将 session.backend 设为 redis,确保会话数据持久化
-
网络安全:API 默认不含鉴权,生产环境建议通过反向代理(Nginx)添加认证层
-
模型文件:本地模型文件需确保存储路径安全,避免未授权访问
十、辅助工具集
|
工具
|
用途
|
|
download_models.py
|
下载 Embedding / Reranker 模型
|
|
download_optional_parser_models.py
|
下载文档解析器 / OCR 模型
|
|
ingest_to_kb_store.py
|
批量导入文档到知识库
|
|
encrypt_secret.py
|
加密配置中的敏感字段
|
|
migrate_to_sessions_table.py
|
迁移旧版会话数据
|
|
add_thinking_summary_column.py
|
添加思维链摘要字段
|
|
tune_threshold.py
|
调优检索相似度阈值
|
|
manage_service.ps1/sh
|
Windows / Linux 服务管理
|
总结
WIKI 知识库是一个架构清晰、模块解耦、私有化友好的 RAG 系统。其核心设计思路是:
文档解析 → 文本分块 → 向量化 → FAISS 索引 → 向量检索 → Rerank 排序 → LLM 生成 → SSE 流式输出
整个流程在 knowledge_base.py 中串联,各模块通过接口解耦(存储层、LLM 客户端、文档解析器),使得替换模型、切换数据库、更换 OCR 引擎等操作都只需修改配置,无需改动核心逻辑。
如果你正在寻找一个可本地部署、支持多 LLM、具备完整 RAG 能力的知识库方案,这个项目值得深入体验。