中国人民大学高瓴人工智能学院与字节跳动技术团队合作近日完成相关研究,发布 Scale-SWE 数据集。研究团队依托火山引擎的 Sandbox 基建,通过 Sandboxed multi-agent 系统,成功实现 SWE 任务的规模化拓展,构建起包含 100k 真实数据、目前规模最大的开源高质量 SWE 数据集。
![]()
基于该数据集蒸馏数据所训练的 Qwen3-30A3B-Instruct 模型,也在 SWE-bench-Verified 评测中取得了 64% 的优异成绩。
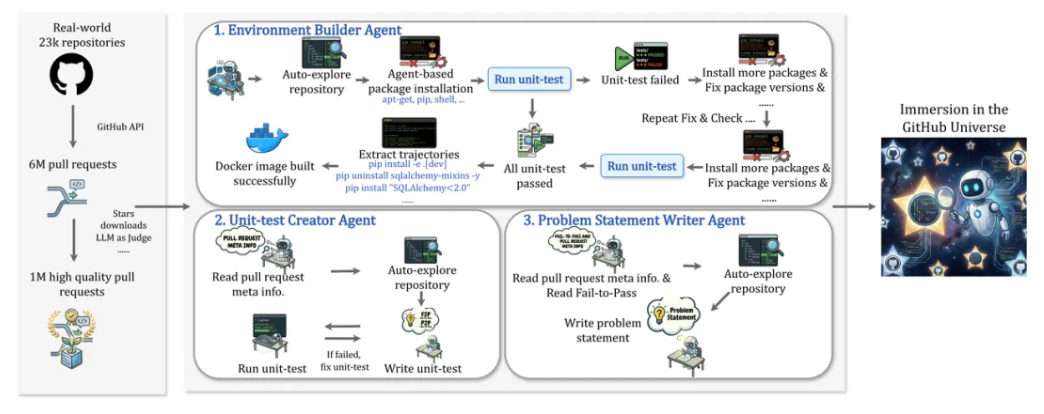
根据介绍,研究团队提出了一套在 Sandbox 环境中运行的多 Agent 工作流,主要包含三个核心模块:EBA(Environment Builder Agent)、UCA(Unit-test Creator Agent)和 PSWA(Problem Statement Writer Agent)。
-
EBA(Environment Builder Agent):EBA 负责在 Sandbox 中自主探索仓库结构,定位并配置环境文件,如 README.md, setup.py, pyproject.toml 等并完成环境配置。在执行 pytest 等脚本验证环境后,可根据报错信息动态调整配置。该阶段对资源消耗较大,依赖高并发调度实现高效执行。
-
UCA(Unit-test Creator Agent):针对缺乏自带 unit-test 的高质量 pull request,UCA 可依据代码差异与仓库完整代码自动生成 F2P/P2P 测试样例,并通过与环境交互进行调整,最终通过切换 commit 执行测试进行验证,确保测试用例符合定义。高并发物理机调度是本阶段快速验证的基础,因为数据量的规模高达 100k。
-
PSWA(Problem Statement Writer Agent):PSWA 负责生成高质量的问题描述,要求既不泄露缺陷位置或解决方案,又能完整准确地反映问题语义。为防止信息泄露,团队选用指令遵循能力更强的 Gemini 3-Pro 作为驱动模型。消融实验显示,问题描述质量对模型 SFT 效果影响显著,在 SWE-bench-Verified 上差异可达近 10%。
上述三个 Agent 模块的高效协同,高度依赖稳定、高并发的 Sanbox 基础设施作为底座。依托火山引擎 Sandbox 基建,研究团队得以调度数千个 Sandbox 并发执行 SWE 数据构建任务,原本单台物理机需运行约 1 个月的工作量,现仅需 1 小时即可完成,且调度过程稳定可靠,有效避免了资源抢占问题。
同时,镜像拉取内置 cache 机制,大幅降低延迟。正是这一高并发调度能力,为 100k 量级 SWE 数据的快速构建提供了坚实支撑,使多 Agent 工作流的规模化落地成为可能。
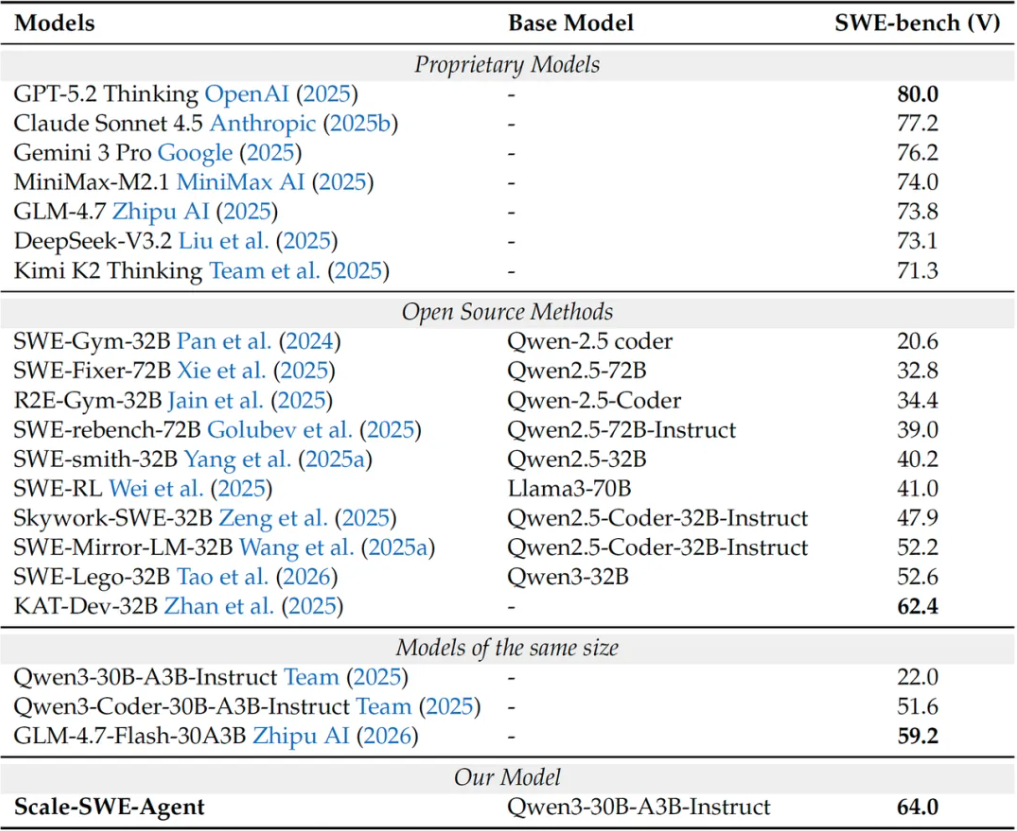
为了验证 Scale-SWE 数据的效果,研究团队使用 DeepSeek v3.2 进行蒸馏。得到 71k 条成功轨迹,并基于 Qwen3-30B-A3B-Instruct 进行 SFT。结果如下:
![]()
实验表明,对于同等规模模型,Scale-SWE-Agent 相较于 Qwen3-Coder-30A3B 和 GLM-4.7-Flash-30A3B 均有显著提升。即便是更大规模的模型(如 KAT-Dev-32B)以及基于其他数据集训练的模型(如 SWE-Lego-32B),Scale-SWE 仍展现出稳定的性能优势,充分验证了该数据集的有效性。
此外,团队在相同蒸馏流程下,对比了不同数据集的效果,结果如下:
![]()