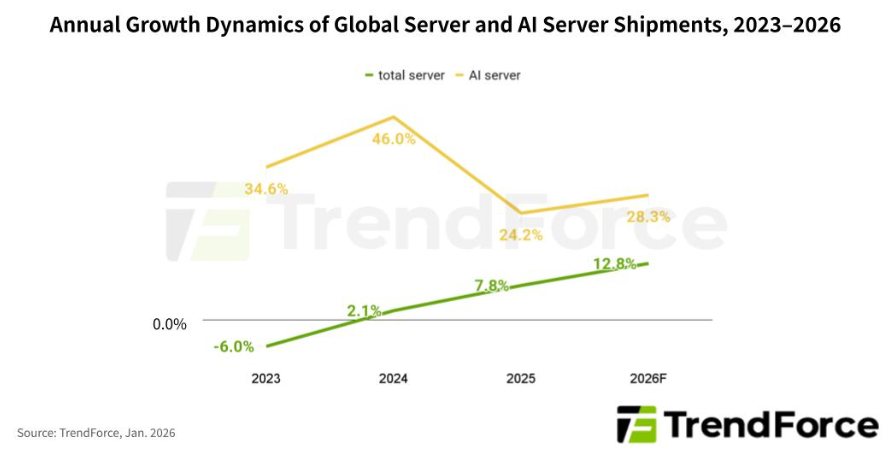
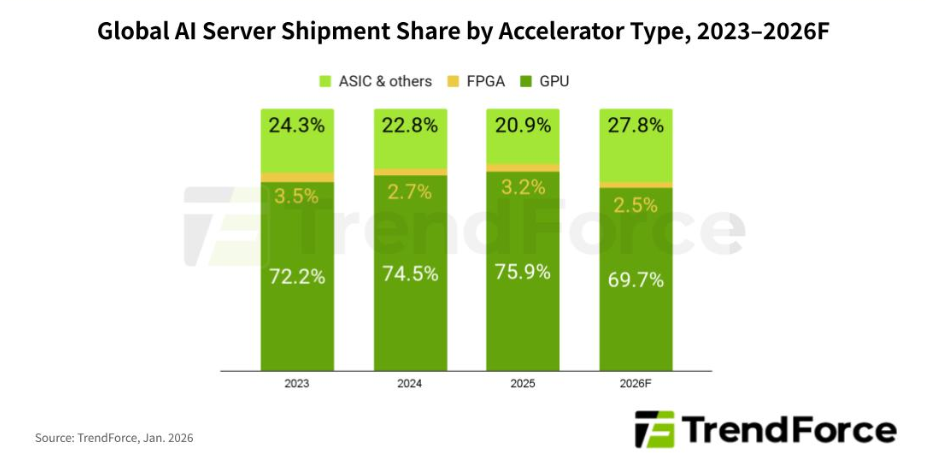

Galaxy 比数平台功能介绍及实现原理
一、背景 得物经过10年发展,计算任务已超10万+,数据已经超200+PB,为了降低成本,计算引擎和存储资源需要从云平台迁移到得物自建平台,计算引擎从云平台Spark迁移到自建Apache Spark集群、存储从ODPS迁移到OSS。 在迁移时,最关键的一点是需要保证迁移前后数据的一致性,同时为了更加高效地完成迁移工作(目前计算任务已超10万+,手动比数已是不可能),因此比数平台便应运而生。 二、数据比对关键挑战与目标 关键挑战一:如何更快地完成全文数据比对 现状痛点: 在前期迁移过程中,迁移同学需要手动join两张表来识别不一致数据,然后逐条、逐字段进行人工比对验证。这种方式在任务量较少时尚可应付,但当任务规模达到成千上万级别时,就无法实现并发快速分析。 核心问题: 效率瓶颈:每天需要完成数千任务的比对,累计待迁移任务达10万+,涉及表数十万张。 扩展性不足:传统人工比对方式无法满足大规模并发处理需求。 关键挑战二:如何精准定位异常数据 现状痛点: 迁移同学在识别出不一致数据后,需要通过肉眼观察来定位具体问题,经常导致视觉疲劳和分析效率低下。 核心问题: 分析困难:在比对不通过的情况...