![图片]()
本文基于演讲内容与 PPT 材料整理,部分数据与案例已脱敏,仅供参考交流。
PPT 下载: https://discuss.nebula-graph.com.cn/t/topic/17404
本文首发于「NebulaGraph 」公众号,更多产品咨询请访问「NebulaGraph 」官网,添加技术交流群方式,详见文末
很高兴在这个夜晚与大家在线上相遇。我是来自 NebulaGraph Product VP 杨哲超。今天,我想与各位分享在AI 与图数据库交叉领域的一些思考与实践。
图数据库或许对很多开发者来说仍是一个相对垂直和小众的产品,但实际上,它与人工智能的关系极为紧密。在大模型兴起之前,知识图谱已是 AI 体系中不可或缺的技术组成部分,而图数据库,正是知识图谱的最佳底座,专注于解决多元异构数据的融合、分析与决策问题。
在数据库权威排名 DB-Engines 上,NebulaGraph 在全球图数据库类别中排名第二,在国内则位居榜首。我们不仅支持超大规模图数据、具备高性能与低构建成本等特性,更在 AI 时代持续探索图与智能的深度融合。
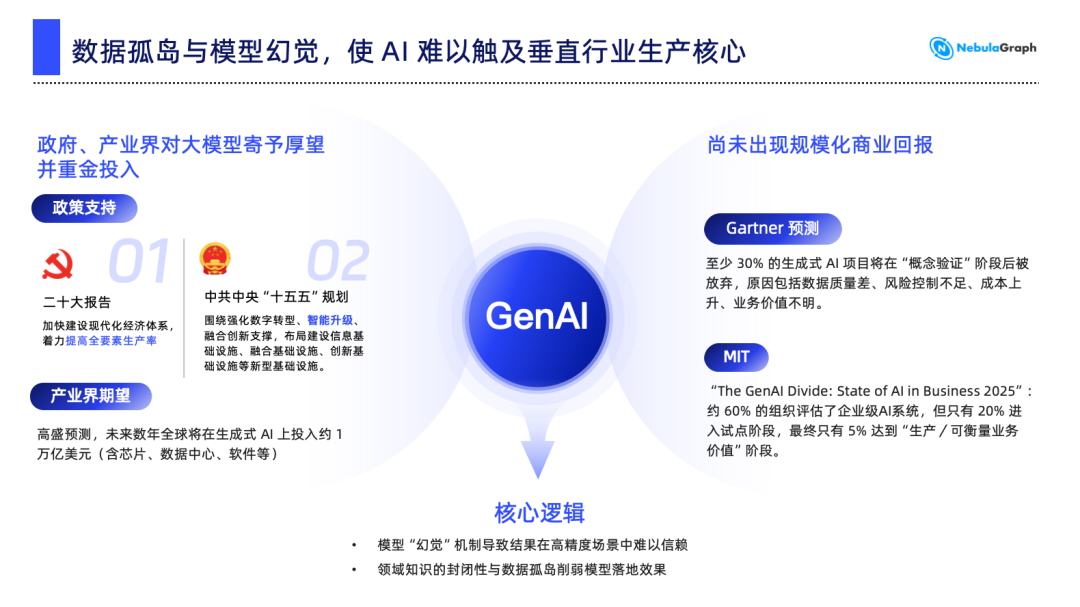
一、AI 的期望与现实:为何大模型难以深入产业?
当前 AI 行业面临一个明显矛盾:一方面,政策与产业界对大模型寄予厚望。从国家“十五五”规划对人工智能的全方位赋能要求,到高盛预测未来数年在生成式 AI 上近 1 万亿美元的投入,无不显示各界对 AI 推动生产效率提升的期待。
然而另一方面,大模型在生产领域的规模化商业回报尚未显现。据 Gartner 预测,超过 30% 的生成式 AI 项目将在概念验证阶段后被放弃,原因涉及数据质量、风险控制、成本与业务价值不明确等。MIT 的研究进一步指出,最终仅有约 5% 的 AI 项目能进入生产环境并实现可衡量的业务价值。
![图片]()
我们认为,造成这一割裂的核心原因有两个:
1. 模型幻觉问题:本质是基于概率的预测模型,其设计目标并非严格遵循事实,导致在高精度、高可靠性要求的场景中,输出结果难以信赖。
2. 数据孤岛问题:即使是最强大的通用大模型,也难以接触到各行业内部的专有数据,例如政务内网、企业业务系统等,导致模型在垂直领域中“看不见”关键信息,难以触及生产核心。
二、GraphRAG:从检索答案到核查事实的范式升级
最近 Google 推出的 NotebookLM 之所以受欢迎,正是因为它通过引入外部知识源,显著降低了模型幻觉。这背后的关键机制正是 RAG.
![图片]()
RAG 的本质,是让大模型从记忆里找答案转变为到事实中去核查。而目前常见的 RAG 索引方式主要有三种:全文索引、向量索引和图索引。
1. 全文索引:基于关键词匹配,略显生硬,依赖倒排索引等技术。
2. 向量索引:更接近语义检索,能够理解内容含义,适合推荐、相似性查询等场景。
3. 图索引:核心是找关系,能够保留数据中丰富的关联信息,避免信息被切割丢失。
相比前两者,GraphRAG 可视为传统 RAG 的革命性升级。它将知识图谱与图技术深度整合到大模型架构中,显著提升了上下文关联性、推理深度与结果可解释性。
三、GraphRAG 的挑战与 NebulaGraph 的破局之路
尽管 GraphRAG 优势明显,但其应用仍面临两大门槛,这让很多想尝试的开发者望而却步:
![图片]()
为了不让 GraphRAG 沦为 PPT 里的摆设,NebulaGraph 核心做了两件事:
1. 降低技术门槛:让业务人员也能驾驭图
我们不希望 GraphRAG 是一个无法干预的黑盒。通过提供可解释、可干预的工具,业务人员可以根据行业理解在图谱中直接插入规则。这种人工干预+模型概率的结合,才能保障产品在生产环境里的可靠性,真正实现:
![图片]()
2. 降低使用成本:打造端到端自动化工具链
我们将 GraphRAG 从科研项目转变为标准产品,大幅压缩实施周期与成本:
-
传统流程需经历:数据清洗 → 分块 → 实体抽取 → 关系抽取 → 社区发现 → 摘要生成 → 图入库 → 接口封装,全程约需 2–4 周 ;
-
NebulaGraph 自动化方案:
-
通过大模型自动识别数据领域,覆盖约 65% 的高频行业场景;
-
高集成封装,开箱即用,数小时内即可完成图谱构建,初始 F1 值可超 0.85;
-
遵循第一性原理优化,建索引效率较微软 GraphRAG 提升约两个数量级。
![图片]()
四、实战案例:基于图智能的运维根因定位
分享一个我们最近在头部运营商落地的真实案例。在处理海量运维工单时,传统的做法是靠老专家的经验,在成千上万行日志里“捞”根因,不仅累,还容易漏。
NebulaGraph 的解决方案是,把工单按时间线来“连线成图”。 通过将每一个工单子图融合成一张全局知识大图,再利用 PageRank 等算法自动计算节点的权重。最终的效果非常惊艳:
该方法已申请发明专利,并适用于金融、电力、制造等所有具备时序日志与告警体系的场景。
![图片]()
(感兴趣的小伙伴,可以借鉴类似案例,如 BOSS 直聘 20 秒根因定位)
![图片]()
五、趋势展望:Graph + AI 推动大模型走向专业决策
站在现在看未来,我们认为 Graph + AI 会有两个显著的信号:
1. 从孤岛走向知识中枢:现在的 AI 很多是单点应用(比如一个简单的聊天机器人)。未来,企业会更倾向于把自有数据连接成一张大图,构建真正的企业大脑,支持更复杂的业务决策。
2. 从事后分析走向事前预测:现在的 RAG 大多是静态的检索,未来它会更具动态性。大模型将不只是告诉你发生了什么,而是能参与到事中的干预,甚至预测可能发生的风险。
六、愿景:共建开放、智能的图数据生态
作为国内领先的图数据库厂商,NebulaGraph 将持续推进图与 AI 的融合创新:
-
推动 GQL 标准化与 GraphRAG 架构规范化,降低行业使用门槛;
-
与高校、研究机构合作,培育“图 + AI”复合型人才;
-
开放产业案例库,分享跨行业实践,加速技术落地;
-
积极集成 Memory Zero、Memory Machine 等 AI 组件,构建更开放的图智能生态。
我们相信,图 + AI 将成为企业数字化转型的核心引擎,但技术落地不是一家公司能完成的,希望未来能与更多开发者一起,赋能千行百业实现真正意义上的智能升级。
✦
如果你觉得 NebulaGraph 能帮到你,或者你只是单纯支持开源精神,可以在 GitHub 上为 NebulaGraph 点个 Star!
每一个 Star 都是对我们的支持和鼓励✨
GitHub:https://github.com/vesoft-inc/nebula
官网:https://www.nebula-graph.com.cn/
论坛:https://discuss.nebula-graph.com.cn/
技术交流群:NebulaGraphbot
✦
✦