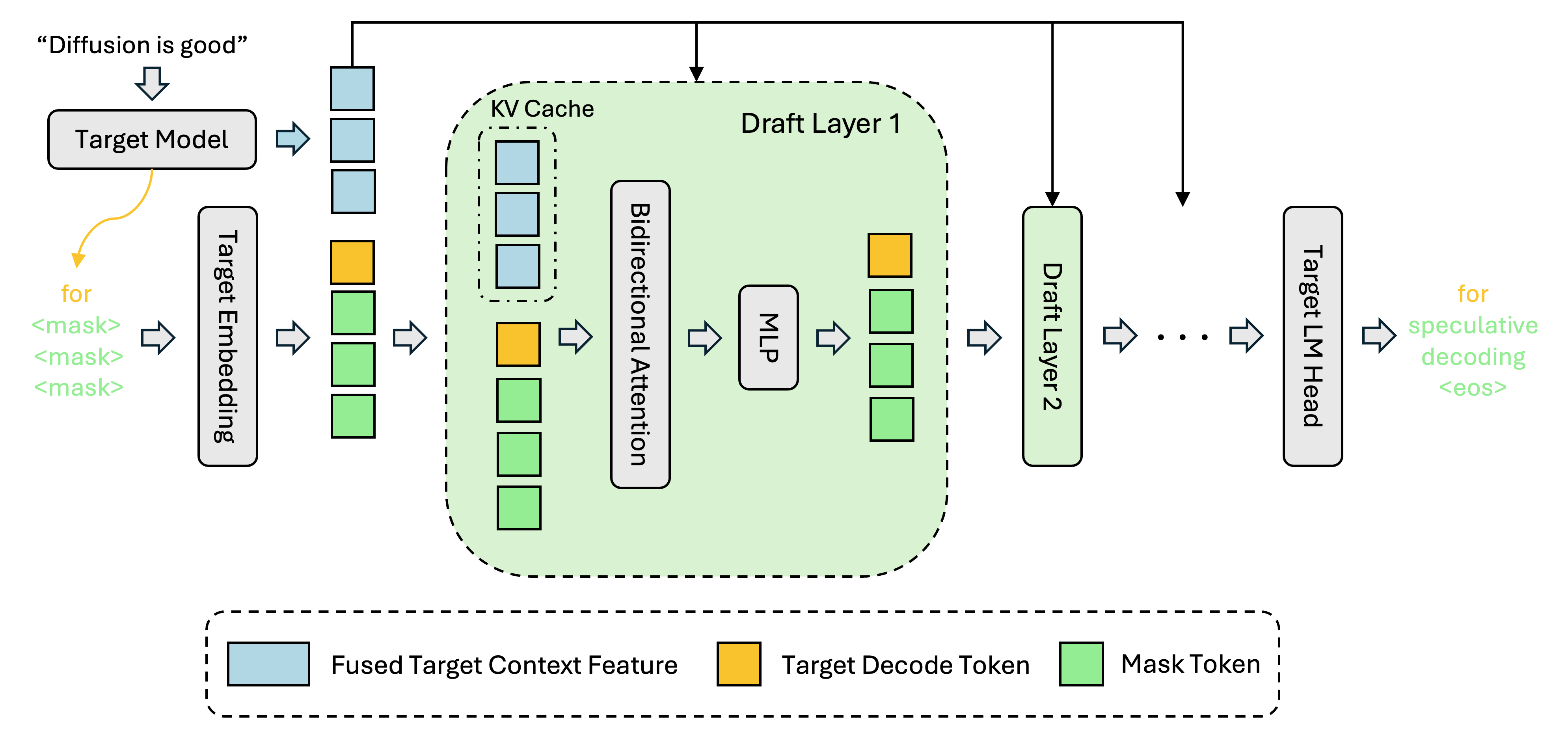

快手可灵团队开源 UniVideo,一个模型搞定“视频理解+生成+编辑”
快手可灵团队与滑铁卢大学联合推出统一视频模型 UniVideo,这个模型首次将视频理解、编辑和生成整合到了一个模型中。 该方法使用一个多模态大语言模型 (MLLM) 来理解指令和上下文,一个多模态 DiT (MMDiT) 用于生成和编辑视频。该技术支持多种视频处理功能,包括生成,即根据文本,图像等参考描述生成视频理解,能够解析图像或视频中的视觉信息编辑,根据用户描述与图像参考对视频进行内容,风格修改。 演示中它支持通过输入图片和 prompt 来生成视频,也可以输入视频和图片来修改视频,或者直接使用 prompt 来编辑视频。 技术上这个模型最大的突破是:用 千问 2.5 VL 做理解负责处理图像、视频和文本输入,用混元视频做生成,两个模型联动配合,让 AI 既能"看懂"又能"创作"。 以前这些任务需要好几个模型分别处理,现在一个模型全搞定,而且不同能力之间还能相互增强。 从实际效果来看动作比较小的视频质量是可以的, 不过也有典型的AI问题, 比如火焰效果需要优化, 以及会有一定程度的一致性问题, 比如这个头发的发丝效果. 但瑕不掩瑜, 这个模型的前景非常不错. 开源地址:https:...