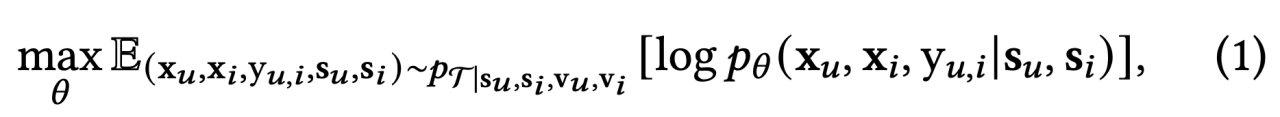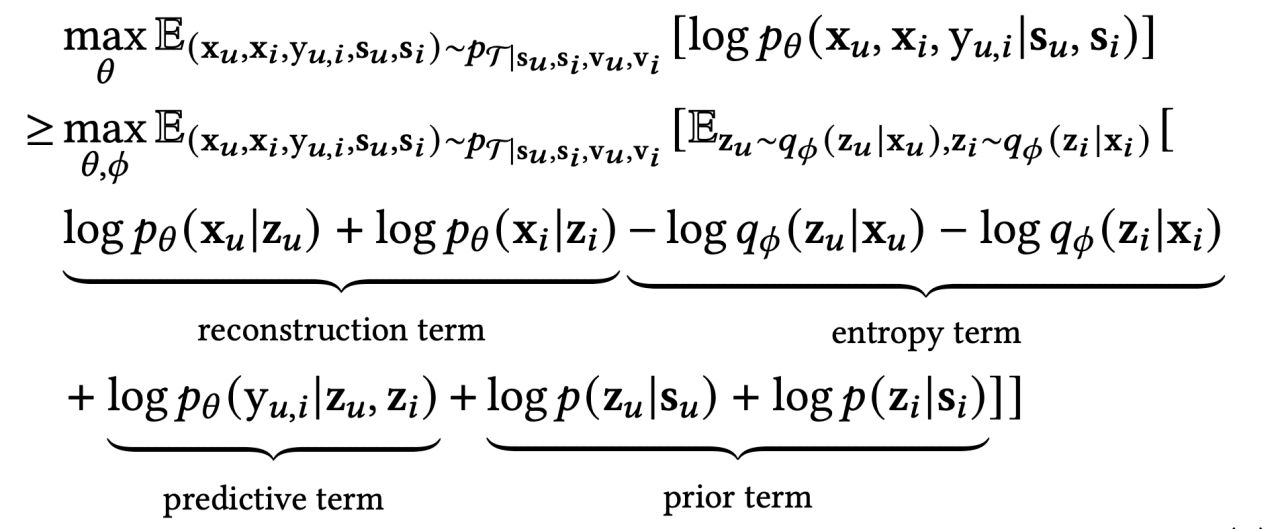在真实的工业级推荐场景中,用户的偏好会随着时间不断迁移,而模型当然也不能“一成不变”,需要不断在每一天新到来的数据上训练,来适应数据分布的迁移。理想中,模型在“见识过”各种各样的用户数据后,可以从容自如、准确地预测用户的行为。而实际情况是,模型在训练每一天的数据时,AUC可以持续增长,但在未来一天的样本上预测的时候,又会断崖式下跌,仿佛模型在不断地“过拟合”每一天的数据。不仅如此,电商平台的大促前后,剧烈的数据分布“地震”往往会让模型在大促当天表现不佳。
推荐模型在持续训练中为何“失忆”?如何让模型能够在不断迁移的数据分布中“找到”有效的的信息?
针对这一问题,Shopee傅聪团队联合新加坡管理大学SMU,深入分析挖掘了工业级推荐系统数据分布迁移的模式,并在此基础上提出了一种模型架构无关的学习框架ELBO_TDS(Evidence Lower Bound Objective for Temporal Distribution Shift)。
![]()
该研究成果发表后,便获得人工智能领域核心基础设施平台Hugging Face的关注。作为学术界与工业界公认的重要开源平台,Hugging Face主动邀请傅聪团队将论文及配套的推荐系统时间分布偏移工业基准数据集分别托管至其论文库与数据集平台。这一认可充分体现了傅聪团队的该项研究在理论创新与工程实践方面的双重价值。
![]()
傅聪团队的研究方法从真实场景数据分析出发,重新解读了推荐系统场景下,用户交互数据的“生成过程”,并提出了一种ELBO建模目标,将增强表征时间尺度鲁棒性的自监督学习,与训练模型个性化能力的标签监督学习,无缝统一在了一个因果学习框架中,为持续学习、甚至life-long学习提供了一个新的视角。
时间维度分布迁移分析:改写推荐系统数据认知
推荐数据在时间维度上的分布漂移会阻碍模型的稳定学习,尤其是在Shopee的场景,每月一大促、半月一小促的周期让模型的训练AUC曲线如同“过山车”。想要解决问题,首先需要理解问题的本质。
论文对30天周期的训练数据进行了深入分析,将部分结果可视化后,如下图所示:
![]()
推荐系统模型的训练数据,本质上是用户的行为 + 各种类型特征的记录。在推荐系统的特征工程中最常用的特征不外乎三大类:统计特征、类别特征、序列特征。不同类型特征的迁移表现可以总结为以下三点:
- 统计类特征(如物品最近3天窗口的CTR)的item CV分布呈现单峰分布。解读:CV(Coefficient of Variation)一般用于度量某个数值的波动剧烈程度。单峰分布的CV代表了该统计特征在大多数情况下呈现出“有界性”。换句话说,特征的数值在很小的概率下会产生远离均值的异常值。
- 序列特征中,与目标商品相关的item数量(例如在swing i-to-i graph中有互连边的关系)的CV分布也是偏左单峰。
- 类别特征(例如item id,user id)的分布,在连续多天的JSD(香农熵,衡量分布差异性)数值上是缓慢增长。解读:以item ID为例,任意相邻两天的JSD是0.53附近。但第0天到第13天的累积JSD却只增长到了0.59。
从上面的数据分析我们可以看出,任意一种特征的数值或分布,在天与天之间切换时,都呈现了不弱的抖动(CV数值在2~4)。但长周期来看,数值的波动烈度又是相对稳定的(CV单峰、JSD增长缓慢)。
这像极了一拳超人的绝技:超级反复横跳。
为什么数据会“反复横跳”呢?这个横跳过程中的那个相对稳定的“均值”又代表什么呢?
一般情况下,可以假定参与到推荐系统“协同过滤”过程的用户,是“理性”和“感性”掺杂的个体,但多数情况下理性占主导,尤其是电商场景,涉及到真实交易支付。一个商品的质量等本质属性不会突变,所以不会今天畅销、明天滞销、后天又畅销;同样,一个用户,也可以认为其文化背景、生活环境、年龄履历、经济状况,不会经常突变。因此,论文认为,这个稳定的均值代表参与到推荐系统的对象(用户和物品)的“稳定内核”,而横持续跳着的“方差”,则是由各种因素带来的“干扰”,例如社交媒体的流行趋势、热点讯息、用户不定期的访问习惯、广告促销、系统Bias和不确定性等等。
由此看来,我们需要对推荐系统的数据模型进行重新认知。
传统的理解里,推荐模型建模的是P(Y|X),把X作为数据的“真实”,以此X来推断标签Y,那么数据的“因果”流向是 X -> Y。但论文认为,X中的绝大多数“手工特征”是对真实属性、偏好的带噪声的表达,而不是数据的“真实”。那么,推荐系统的真实数据生成过程可能是下面这张图:
![]()
论文认为参与到推荐系统的对象——用户和物品都包含两面性。一种是稳定因素,代表对象的内核、本质,例如商品的类目、质量、功能,或用户的性别、年龄段(相对稳定)。另一种是波动因素,代表对象的表象、某种视角的观测,例如商品的销量一般会持续上涨至其生命周期结束,用户的即时兴趣会收到社会属性的影响。
为了方便建模,论文方法引入隐变量Z。这个视角下的数据生成过程,或者因果关系,是稳定因素S和波动因素V共同作用于隐变量,即S -> Z,V -> Z。而再经由Z,形成了大家对数据表象的观测X和Y,即Z -> X, Z -> Y。
因此,论文方法希望模型能够捕捉到 Z 的分布,从而建模好 X 和 Y的联合分布。因此,论文方法追究的这个过程,更接近与“生成式建模”的思路(注,不同于目前业界很多所谓的生成式推荐,其本质都还是建模条件分布P(Y|X),严格意义上属于判别式模型)。
方法论:从ELBO推导出自监督和判别式监督联合学习框架
首先,论文基于对数据的观察总结提出了稳态-波动假设:
![]()
接着,基于这个假设,论文方法希望模型建模联合分布的时候可以过滤掉波动因素V的干扰,从而让预测更稳定,从这个角度来看,论文提出了以下极大似然估计目标:
![]()
这个目标的含义是,从一个带有噪声V的数据分布上采样得到样本,但让模型试图仅仅学习given稳定因素S,X和Y的联合概率分布。上述目标不可直接优化,为了方便VAE形式的建模,引入隐变量Z,稍加推导,可以得到新的目标ELBO:
![]()
这个ELBO包含4个小项目,从语义理解看:
- 重构项:从隐变量Z 重构出样本 X,
- 熵约束项:对隐变量Z的方差进行有效约束,保证表征坍塌。
- 预测(判别式)项:从隐变量Z预测标签Y。
- 先验约束:使得隐变量Z尽可能只与稳定因素S有关,从而让表征Z具备应对时间维度分布迁移的鲁棒性。
优化上述ELBO,模型就可以得到具有这样特性的表征Z,既包含了重构X的能力,最大限度的保留信息,防止表征坍塌;又保留了有助于判别式任务的有效信息,助力下游任务;还排挤掉了与V有关的信息,强化了应对时间分布迁移(Temporal Distribution Shift,TDS)的鲁棒性,可以说是全能表征。更具体地,模型的训练框架如下:
![]()
多视图数据增强策略
从上述模型结构图可以看到,模型的输入包含带有波动因素V的数据样本。获得这样的样本,最简单的方法就是,从历史样本中获取和构造。然而,这样做费时费力非存储不说,还有一个非常严重的缺点,就是One-Epoch过拟合问题。
所谓One-Epoch过拟合问题,是在工业界不同场景被广泛发现的问题:模型在同一天数据上训练超过一次就容易过拟合到当天样本,造成预测未来时间的样本的AUC明显下降。
为了不产生类似的问题,论文提出了在线增强策略,针对不同类型的特征:
- 统计类型 的特征进行数据分桶(工业界常规操作),增强视图样本则通过扰动真实样本产生,根据之前的数据观测分析,可以把真实样本的桶号随机扰动到其附近的分桶号上。
- 类比类型的特征,随机替换或者zero mask。
- 序列类型的特征,对序列item进行随机mask
上述操作随机进行多次,可以得到一条样本的多个“视图”。这就好像图片预训练模型的随机裁剪、旋转、变色等数据增强操作。
上述样本生成过程不需要参考历史样本,可以在训练时并行计算,对样本训练带来的成本几乎可忽略不计。
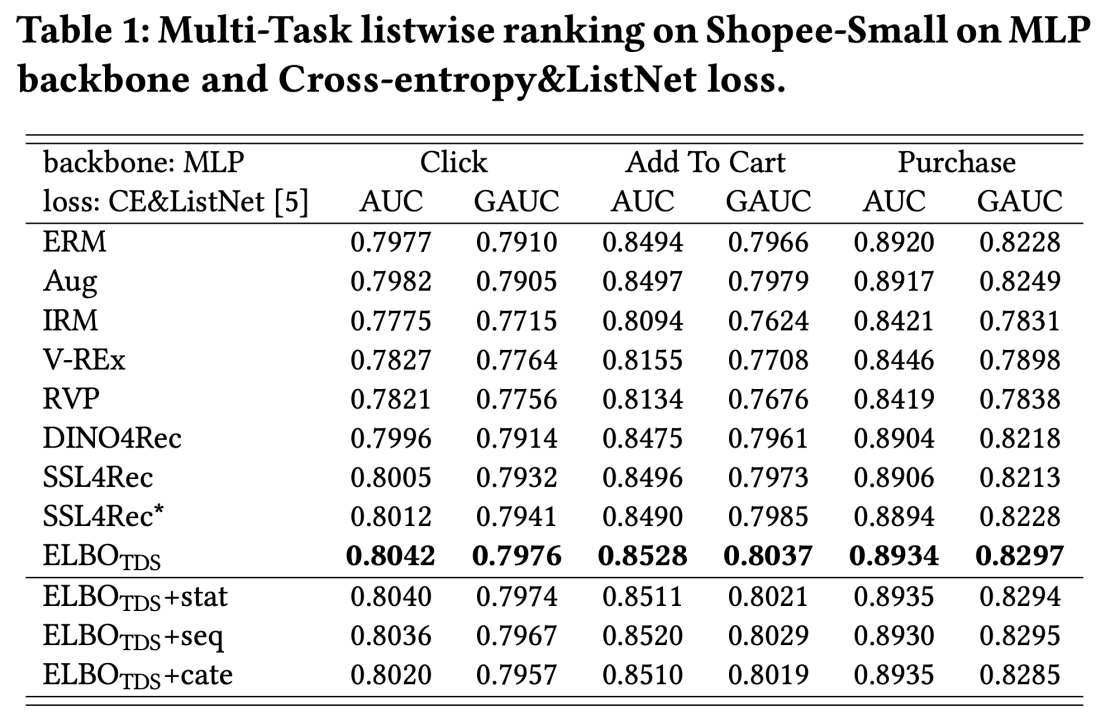
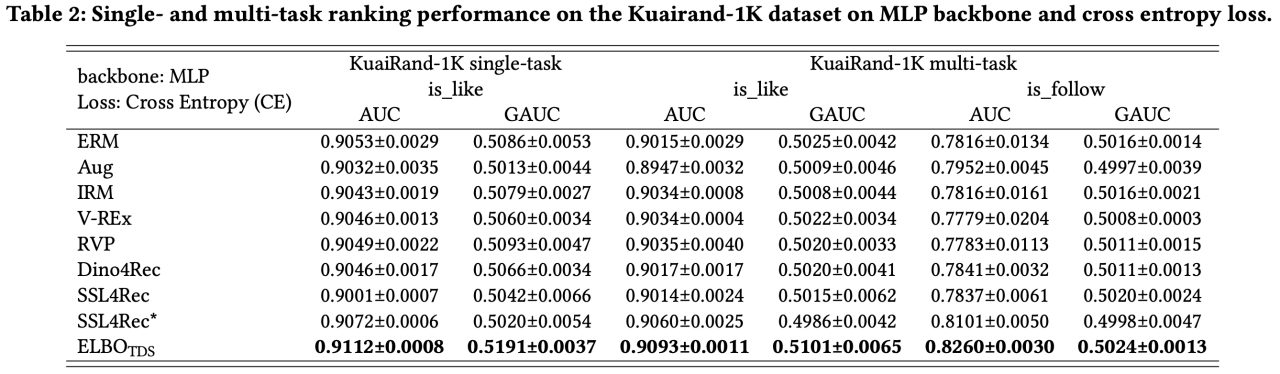
实验数据和结果分析
推荐系统数据的时间分布迁移(TDS)是一个相对比较小众且新型的领域,可对比的方法不多。但论文关注到和这个领域最相关的一个机器学习方向叫做不变性学习(Invariant Learning or Invariant Risk Minimization for covariant shift)。与此相对应地,传统的推荐模型建模其实都隐含一种数据分布随着时间推移保持i.i.d.的假设,可以被统称为Empirical Risk Minimization (ERM)。此外,论文中还将比较相似的基于对比学习的自监督学习,以及将图像pretrain领域的Dino适配到搜推领域,统一纳入到Baseline之中。
论文在公开数据集和工业级数据上都进行了实验。公开数据集的选择也比较有限,主要原因是,要对数据特征进行有效“扰动”,就需要了解特征的语义;同时,数据需要在相对比较连续的一段时间内进行采集,保证用户偏好不会产生极大偏移,从而脱离论文研究问题的范畴;数据不可以经过主观性强的、大力度的采样,导致数据分布产生不自然的扭曲。因此,传统 的常用推荐benchmark,如Amazon Reviews、MovieLens数据集存在时间尺度过长且不连续、采样力度过大的问题;AliCCP、AE等电商数据存在时间戳不明确、特征含义不明等问题。最终我们找到快手release的kuairand系列数据。针对kuairand数据集,由于其跟踪user来采集数据,导致数据因用户来访频率不稳定而产生时间区间的数量不均,例如数据采集区间内4~5月的很多自然天内内没有数据。我们将数据按时间戳排序后,将数据集重新等分为数量差不多的几个part,定义为不同虚拟“自然天”的数据。
实验结果如下:
![]()
![]()
首先,从上述数据我们可以看到论文提出的ELBO_TDS框架,相较于baseline,均取得了显著提升。这说明ELBO_TDS可以有效低去除数据中与用户核心兴趣无关、与时间迁移有关的噪声,从而更好地预测用户的偏好。
其次,ELBO_TDS在视频、电商两类模态的数据上均取得有效提升,也说明了TDS问题在各类推荐系统中广泛存在。
另外,IRM类方法例如IRM、V-REx、RVP等效果均低于在数据上增量训练的ERM(模拟现实推荐场景的天级更新)。说明TDS问题不是传统的IRM问题,需要有新的解决方案。
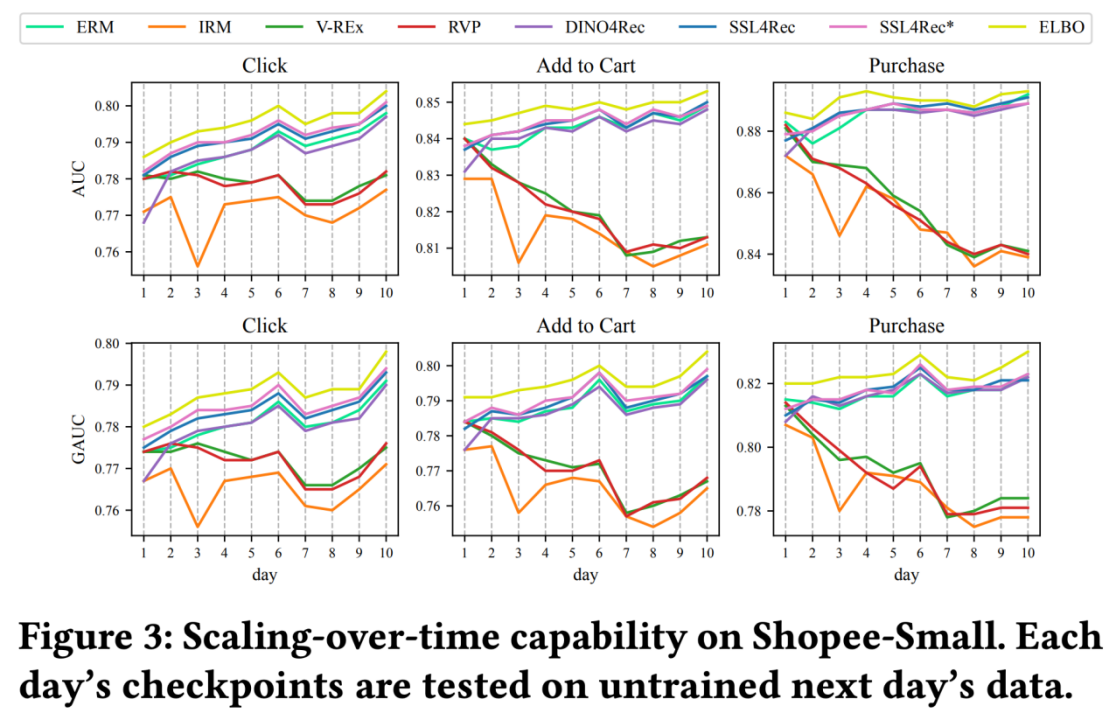
因为所有方法都是按照时间顺序,在数据的一个一个partition上增量训练的,我们用“前一天”的checkpoint去预测“下一天”的位置样本,将曲线画了出来:
![]()
我们可以看到,ERM、自监督、以及ELBO_TDS都是随着时间训练,表现越来越好;但IRM类方法基本都是越训练越差。
这是因为IRM类方法假设数据集的不同partition之间存在绝对不变的“内核”,试图用某种regularization + 对其它partition数据的重复访问,来学到这个“绝对不变”的隐变量。然而,这个假设并不适用于搜推广的情形。从理论上,TDS不是单纯的covariant shift的问题,TDS不假设稳定因子S绝对不变。从经验分析上,论文的数据分析也表明,除了剧烈波动的V因子,S因子也在随着时间漂移,只是相对来说非常缓慢。
针对covariant shift的IRM类方法失效的原因,一方面是“不允许”用户偏好迁移,这与任务目标违背;另一方面是参考了“历史”数据partition,触发了搜推广常见的one-epoch过拟合问题。
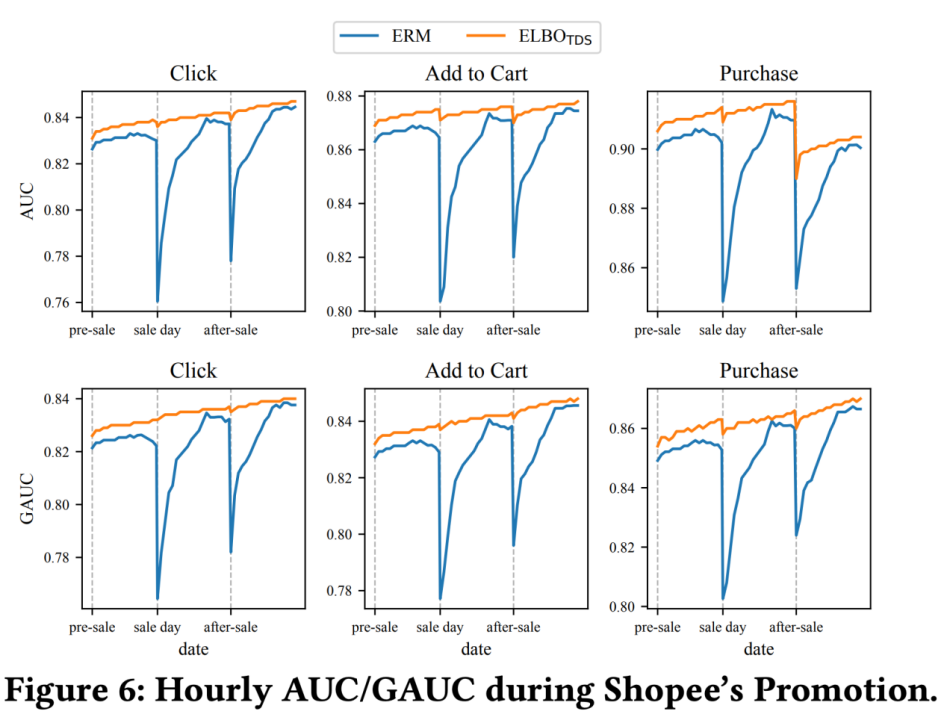
ELBO_TDS的另一个优势在于,对大促来带的剧烈数据分布地震不敏感:
![]()
Baseline,即线上的ERM方法,在大促前后,即便切换到了小时级别更新,进行快速的分布adaption,依然在大促前夜、大促后夜的时间区间出现了auc断崖下跌,会对大促前几个小时的收入造成损失。而ELBO_TDS效果几乎无损。最终,在两周实验期间,ELBO_TDS取得了2.33%的GMV/user的收益推全。
arxiv论文ELBO_TDS https://arxiv.org/pdf/2511.21032
huggingface https://huggingface.co/papers/2511.21032
GitHub开源代码 https://github.com/FuCongResearchSquad/ELBO4TDS