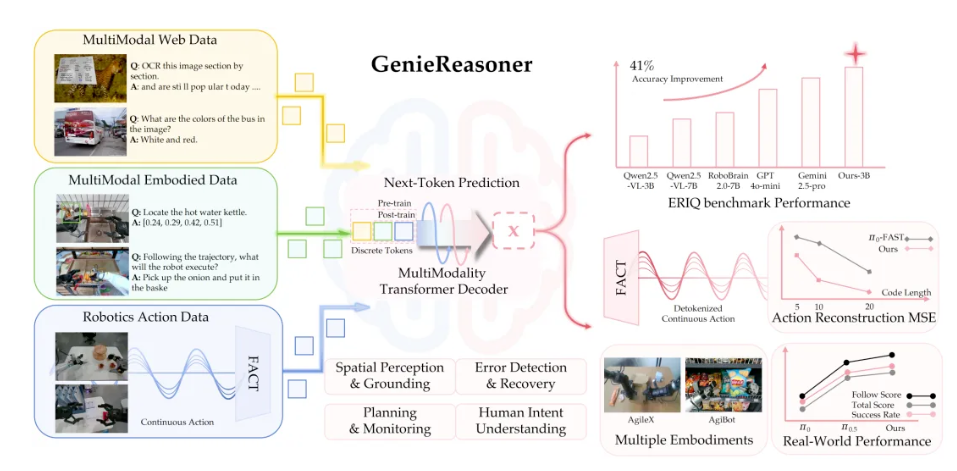
智元具身研究中心宣布推出一体化大小脑系统:GenieReasoner。其聚焦于如何在一个一体化模型中,兼顾高层语义推理和底层精细控制,并开源了全面的基于机器人视角的具身大脑 benchmark—— ERIQ,支持相对应解耦地评测推理性能。
根据介绍,GenieReasoner的设计初衷是建立一套“Action as Language”的统一表达范式,在赋予动作序列大模型级的语义泛化能力的同时,突破离散化表征在执行精度上的物理瓶颈。”改成“GenieReasoner的设计初衷是建立一套Action as Language的统一表达范式,并且在赋予动作序列大模型级的语义泛化能力的同时,突破离散化表征在执行精度上的物理瓶颈。
智元具身研究中心研究发现,现有 VLA 模型在复杂场景中的性能波动,本质上源于模型过度依赖“视觉-动作”的表面统计相关性,而缺乏深层的具身推理(Embodied Reasoning)。然而,提升推理能力与保持执行精度之间往往存在竞争关系:传统的“离散VLM主干 + 连续动作头”架构会因不同目标函数的数学冲突产生梯度干扰,导致模型在“逻辑泛化”与“执行精度”之间被迫取舍。为此,GenieReasoner架构从两个维度重建了VLA范式:通过统一离散表征消除梯度冲突,使用生成式解码技术突破重构精度上限。
![]()
GenieReasoner架构:
- 动作即语言:GenieReasoner 摒弃了“嫁接”思维,将连续的物理轨迹映射为一套紧凑的“离散动作词表”。在模型看来,执行抓取动作与预测下一个文本 Token 具有同等的语义地位。
- 共享梯度空间:通过将通用 VQA、具身推理数据与动作序列在同一离散空间进行联合训练,模型在单一梯度路径下实现了认知与控制的同步优化。
![]()
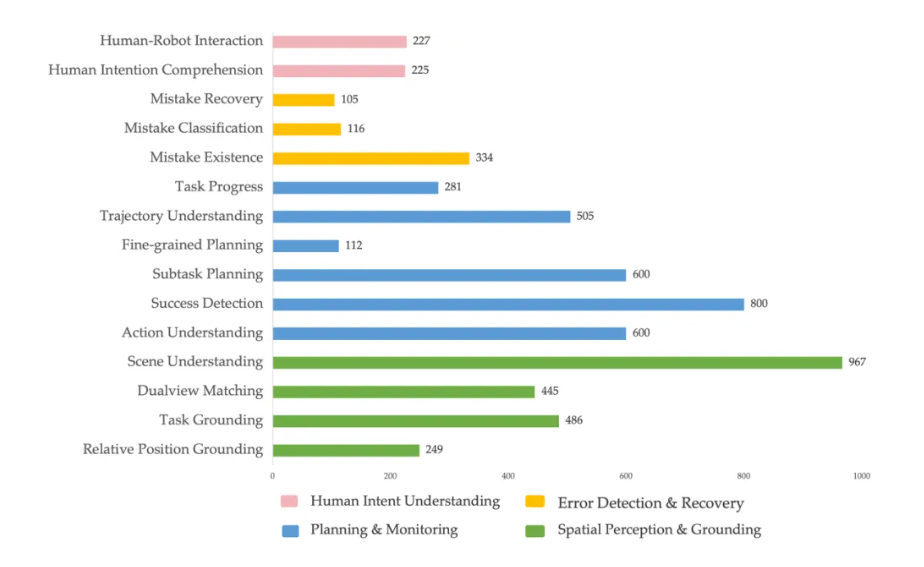
ERIQ包含6k+高质量样本,以单选题、是非题的形式呈现,且每个样本都经过人工审核校验。数据集场景覆盖家居、工业、商超等100+真实场景。其四大核心类别包括:
- 空间感知与定位(理解“左边第二个”、“红色的”)
- 任务规划与监测(长程任务的逻辑拆解)
- 错误识别与恢复(意识到“手滑了”并重新尝试)
- 人机协作(读懂人类的意图暗示)
进一步,四大核心能力被拆解成15个细分维度的子能力(或子能力的组合),例如:
- Success Detection聚焦于“任务完成性检测”,评估模型“任务规划+事件顺序”的能力。
- Task Grounding聚焦于“找到与任务相关目标”,评估模型“感知+任务规划+场景理解”的能力。
- Mistake Classification聚焦于“识别发生的错误类型”,评估模型“因果关系+异常识别”的能力。
- Human Intent Understanding聚焦于“机器人理解用户意图”,评估模型“学习与用户交互 +任务规划”。
原始数据都来自于真机真实场景,超过100多种任务场景,其中家居35%,餐厅20%,商超20%,工业占15%,办公场景10%。在输入模态的设计上,ERIQ旨在全面评估模型的多模态理解与推理能力,数据构成涵盖了多种关键的输入模态:主体由约53%的静态单帧图像构成,用于测试模型的基础视觉感知能力;另有约27%的时序图像数据,以考察模型对时序动态变化的理解;剩余部分则由多帧图像与文本交错组成,评估模型对复杂场景的多步推理能力。
![]()
在后续实验中发现: 在不同预训练的对比下,ERIQ得分更高的VLM,在VLA性能测试中展现出更强的指令跟随能力,得以论证具身VLM越强(脑子好),VLA越强(手越巧)。
智元方面表示,GenieReasoner 的发布是其具身研究中心对具身大脑“智商”与小脑“身手”协同进化的一次初步探索。实验结果表明,在统一离散空间内进行联合训练,不仅大幅提升了模型的泛化性与指令跟随能力,更重要的是,它验证了一套天然兼容Scaling Law的具身模型架构。
但在动作绝对精度和极长程任务的稳定性上,仍有巨大的优化空间。虽然通过提升数据的多样性(Diversity)可以实现性能的量级增长,但在实际路径中,如何在高通量数据 Scaling的同时确保数据的“高质量”与“低噪声”,依然是行业待解的最优路径难题。
“下一步,智元具身研究中心将从“逻辑深度”与“执行精度”两个维度持续推进,并致力于实现具身大小脑、世界模型(World Model)与真机强化学习(Real-world RL)的闭环协同。通过在真实物理世界中的闭环交互与数据反哺,构建出真正具备常识推理与极限操作能力的通用基座模型。”
更多详情可查看官方公告。