


原力灵机推出 GeoVLA 框架
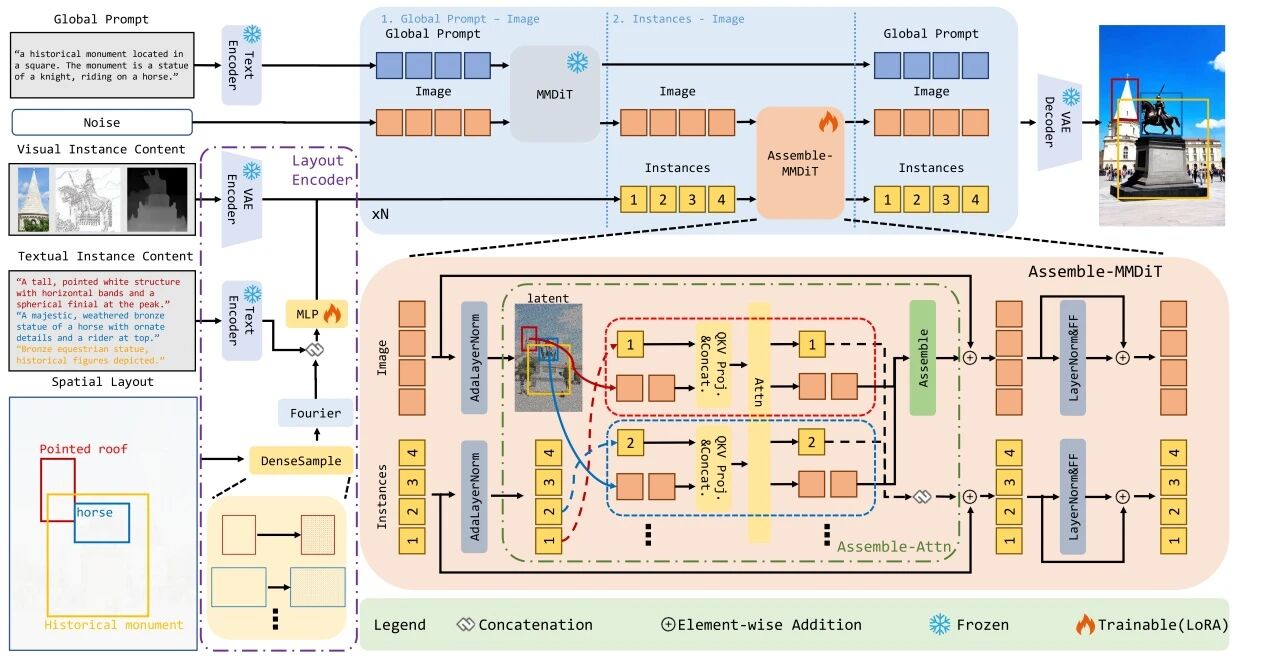
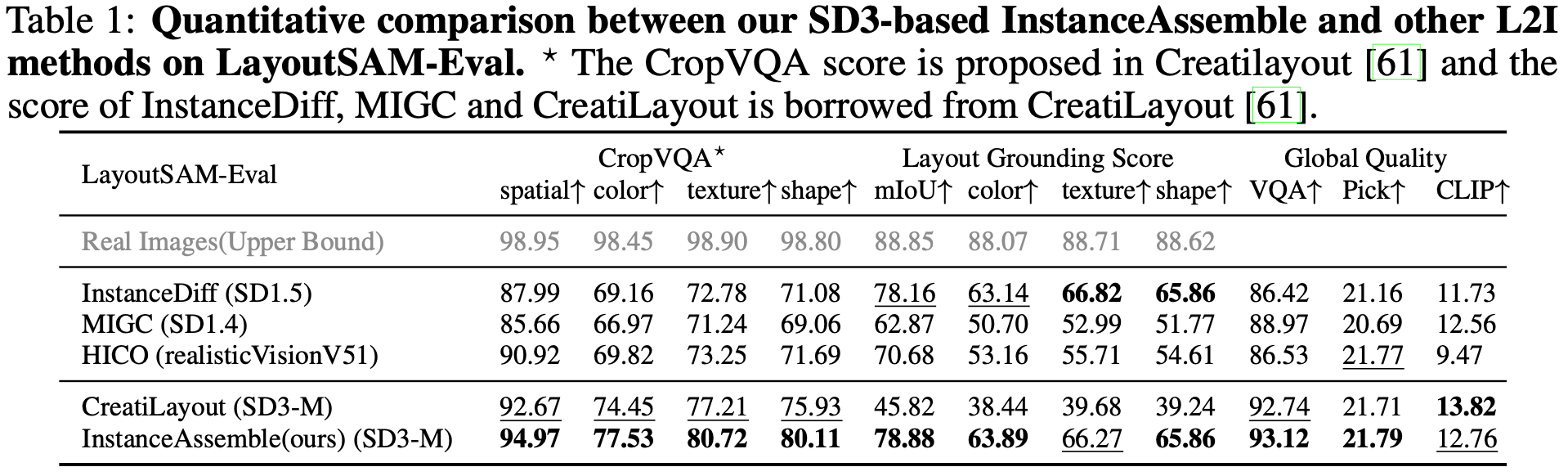
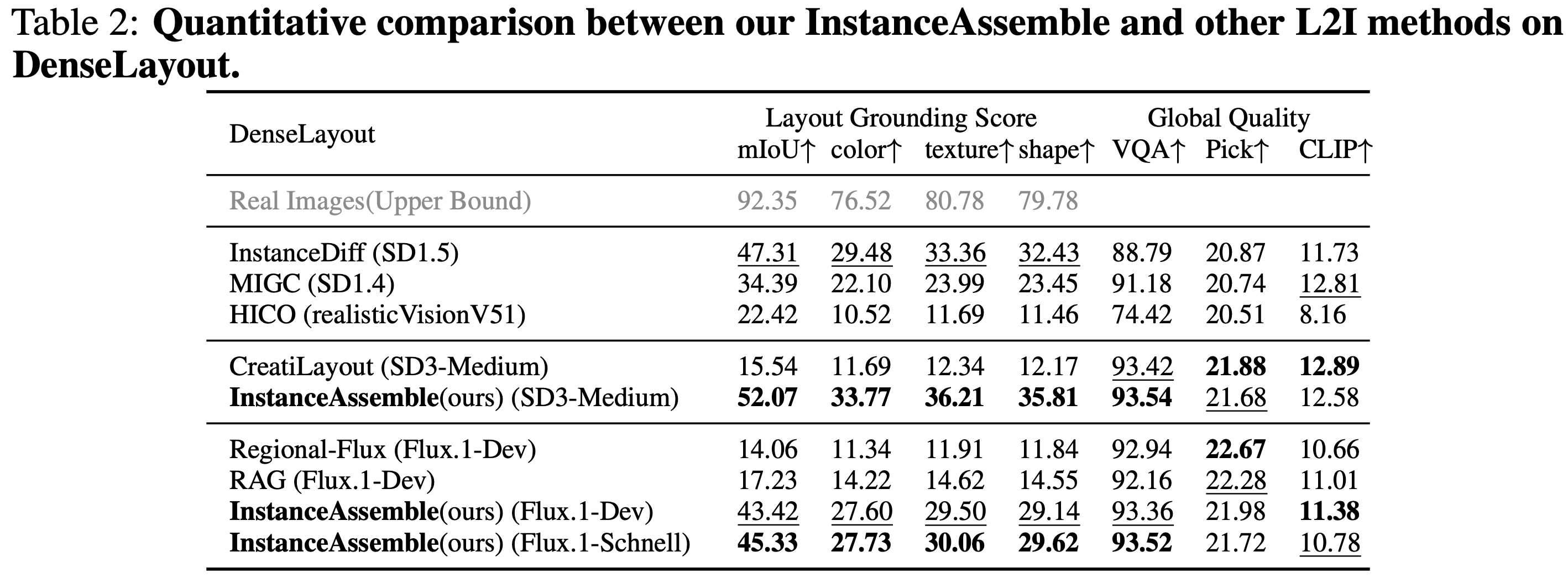
原力灵机的研究团队推出了一种全新的 VLA 框架 ——GeoVLA。该框架在保持现有视觉 - 语言模型(VLM)强大预训练能力的同时,采用了创新的双流架构。 具体来说,GeoVLA 引入了专用的点云嵌入网络(PEN)和空间感知动作专家(3DAE),使机器人具备真正的三维几何感知能力。这一设计不仅在仿真环境中取得了领先的性能,更在真实世界的各种鲁棒性测试中表现出色。 GeoVLA 的核心逻辑在于将任务进行解耦:让 VLM 负责 “看懂是什么”,让点云网络负责 “看清在哪里”。这个全新的端到端框架包含了三个关键组件的协同工作,分别是语义理解流、几何感知流和动作生成流。这种方法使得模型能够更精准地进行任务。 在一系列实验中,GeoVLA 展现出了明显的优势。在 LIBERO 基准测试中,GeoVLA 的成功率高达97.7%,超越了之前的 SOTA 模型。此外,在 ManiSkill2等更加复杂的物理仿真测试中,GeoVLA 的表现也相当出色,尤其在处理复杂物体和视角变化时,保持了较高的成功率。 此外,GeoVLA 在分布外场景中的鲁棒性,证明了其在应对各种不确定性和变化条件下的强大适应能力。...