2026新年快乐
2026新年快乐
编者按: 在 RAG 系统中,一味追求更高维的嵌入模型真的意味着更好的性能吗?
文章重点介绍了 MyClone 将原有 1536 维的 OpenAI text-embedding-3-small 模型替换为 512 维的 Voyage 3.5 Lite 嵌入模型,从而实现 RAG 延迟与存储成本的大幅降低,还能在保持甚至提升检索质量的同时,明显改善用户体验。
技术的选择从来不只是参数的高低,更是与产品目标紧密对齐的战略决策。在追求高效、轻量与实时响应的今天,适合的模型往往比复杂的模型更能推动用户体验与业务价值的双重提升。
作者 | MyClone Engineering Team
编译 | 岳扬

在 MyClone.is,我们的使命是打造真正个性化的数字人格。我们通过检索增强生成(RAG)技术,为每位用户构建一个内容丰富、可交互的"知识分身" ------ 该分身基于用户上传的文档、笔记与知识库,将它们编码后存入向量数据库,为聊天对话和语音助手提供支持。
每当用户通过语音或文字与自己的数字人格互动时,系统都会在毫秒级时间内,基于这些向量做 RAG 检索,精准锁定知识库中最相关的知识片段,并用"像本人"的语气作答。在这一架构中,嵌入模型处于核心地位:它决定了系统对用户内容的理解深度、所需的向量存储空间,以及相关信息的检索与排序速度。毕竟,延迟是对自然对话最大的破坏。
此前,MyClone 使用的是 OpenAI 的 text-embedding-3-small 模型,该模型生成 1536 维的浮点向量,专为通用语义相似度任务优化。该模型在常见检索基准测试中表现出色,且价格相对低廉,但其默认的 1536 维向量尺寸相比低维替代方案,意味着更高的存储和带宽开销。
在高吞吐量的 RAG 系统中,1536 维向量会大幅增加内存占用、磁盘使用量和每次查询的 I/O 负载。随着用户数量和知识条目不断增长,这可能成为延迟和成本方面的瓶颈。
我们最近在 RAG 流程中识别出这一瓶颈,并果断采取行动:将 OpenAI 的 text-embedding-3-small(1536 维)替换为 Voyage-3.5 Lite(512 维)。这一改动大幅降低了存储需求和延迟,同时在用户数字人格的检索质量上不仅得以保持,甚至常常有所提升。 这类基础设施的优化,为用户带来了更快、更便宜、对话体验更自然的 AI 助手。
接下来,让我们深入探讨一下这项优化。
表面上看,从 1536 维降至 512 维像是一种妥协。维度更少,信息理应更少,检索质量也该下滑。然而,嵌入模型领域正因诸如 Voyage AI 所采用的 Matryoshka Representation Learning (MRL) 等创新而飞速演进。
Voyage‑3.5‑lite 采用了 Matryoshka training 和量化感知(quantization‑aware)技术,其前 256 或 512 个维度便能捕获绝大多数的语义信号,而非简单地对高维向量进行粗暴截断。公开基准测试和厂商数据表明,在降低维度后,Voyage‑3.5‑lite 仍能保持非常接近其完整维度版本的检索性能,并与主流商业模型相媲美。
相比之下,OpenAI 的嵌入模型主要设计为固定输出 1536 维,其降维通常是事后进行的(例如使用 PCA 或直接截断),除非针对每个领域进行精细调优,否则可能会丢失信息。正因如此,在"成本与延迟敏感、质量又不能打折"的场景里,Voyage-3.5-lite 显得更具吸引力。
最直接的收益体现在存储层。通过将向量维度从 1536 降至 512,我们将存储全部用户知识库所需的向量数据库存储空间减少了约 66%。
向量数据库依赖于计算查询向量与数百万个已存储文档向量之间的相似度(通常为余弦相似度)。这种搜索的计算开销与向量的维度大小正相关。
这项优化使检索延迟直接降低 50%(速度提升 2 倍)。
对于主打语音交互功能的数字人格而言,每一毫秒都至关重要。用户提问后若出现明显停顿,就会破坏"真实对话"的沉浸感。
检索延迟的大幅下降直接提升了整个系统的响应速度:
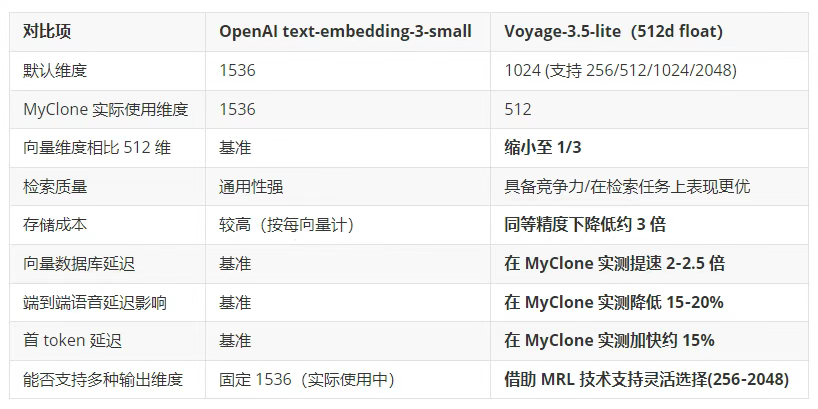
在数字人格平台中,用户满意度与助手在聊天对话和语音交互中是否响应迅速、回答精准密切相关。更低的向量维度能有效降低检索的尾延迟(tail latency),从而直接缩短"首 Token 延迟"(time to first token),让语音对话更流畅自然,减少了"机器人般的停顿感"。
与此同时,用户又期待数字人格能准确回忆自己上传的知识内容。这意味着,任何旨在节约成本的优化,都不能牺牲检索质量,也不能引发幻觉(hallucinations)。Voyage‑3.5‑lite 专为检索场景而设计,使 MyClone 能够在"轻量级检索架构"和"高保真知识锚定"之间取得理想平衡。
从产品与业务角度来看,这次嵌入模型的优化带来了多重优势:
对 MyClone 而言,这些收益是叠加放大的:每位用户的数字人格都能引用更多文档、响应更快、运行成本更低,同时始终忠于用户本人的语言风格、表达习惯与知识内容。
从 OpenAI 的 1536 维嵌入模型切换到 Voyage‑3.5‑lite 的 512 维嵌入模型,表明嵌入模型的选择本质上是一项产品决策,而不仅仅是基础设施细节。 通过将嵌入模型与大规模 RAG 的核心需求(快速、低成本、高语义质量的检索)对齐,MyClone 一举提升了用户体验与单位经济效益。
随着 RAG 系统走向成熟,像 Voyage‑3.5‑lite 这类明确针对"按需选用嵌入维度"、"支持多种量化方案"与"检索质量"进行优化的嵌入模型,将在数字人格这类对延迟敏感、知识密集型的产品中,成为默认选择。
END
本期互动内容 🍻
❓在你们的 RAG 系统中,选择嵌入模型时最优先考虑哪个指标?是延迟、成本、检索质量,还是易于集成?
原文链接:

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
马里奥是站在游戏界顶峰的超人气多面角色。马里奥靠吃蘑菇成长,特征是大鼻子、头戴帽子、身穿背带裤,还留着胡子。与他的双胞胎兄弟路易基一起,长年担任任天堂的招牌角色。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。
WebStorm 是jetbrains公司旗下一款JavaScript 开发工具。目前已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273