智元机器人团队宣布开源 VideoDataset,一个基于实际 AI 训练需求深度开发的高性能视频数据加载库。
- 极致性能: 通过将解码任务从传统的 CPU 转移到 GPU,充分挖掘硬件解码能力,吞吐量提升 4 倍。
- 随机访问: 解决了硬件解码通常不支持随机寻帧 (Random Seek) 的业界难题,专为 AI 训练设计的随机采样功能。
- 无缝集成: 兼容 PyTorch Dataset 接口,提供 Mixin 类,开发者改几行代码即可接入现有训练流。
![]()
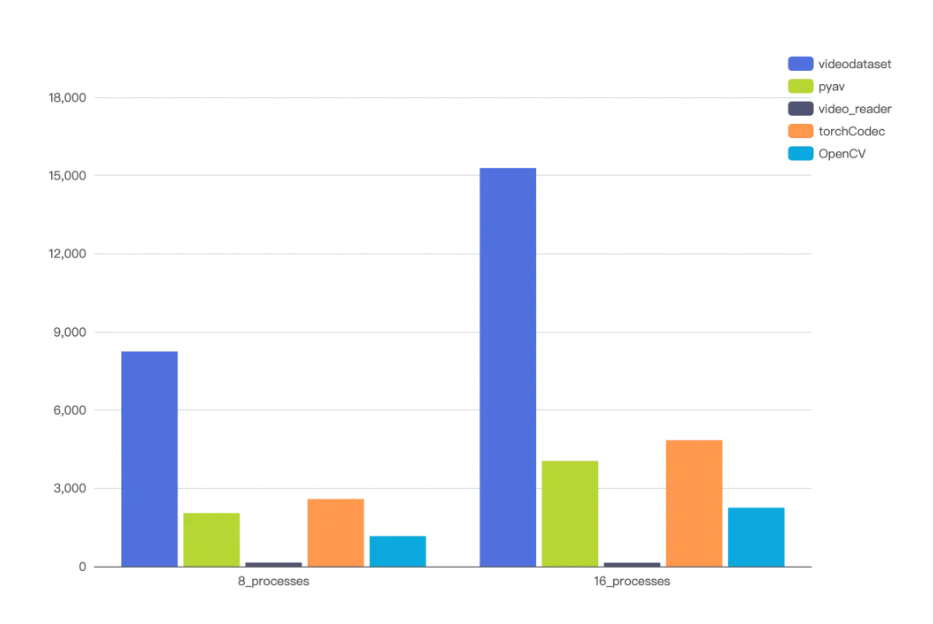
为了更直观地评估 VideoDataset 的表现,智元方面进行了 VideoDataset 与主流 CPU 软件解码方案的全面性能对比测试,测试对象包括 OpenCV、Torchvision(PyAV)、Torchvision(VideoReader)和TorchCodec。
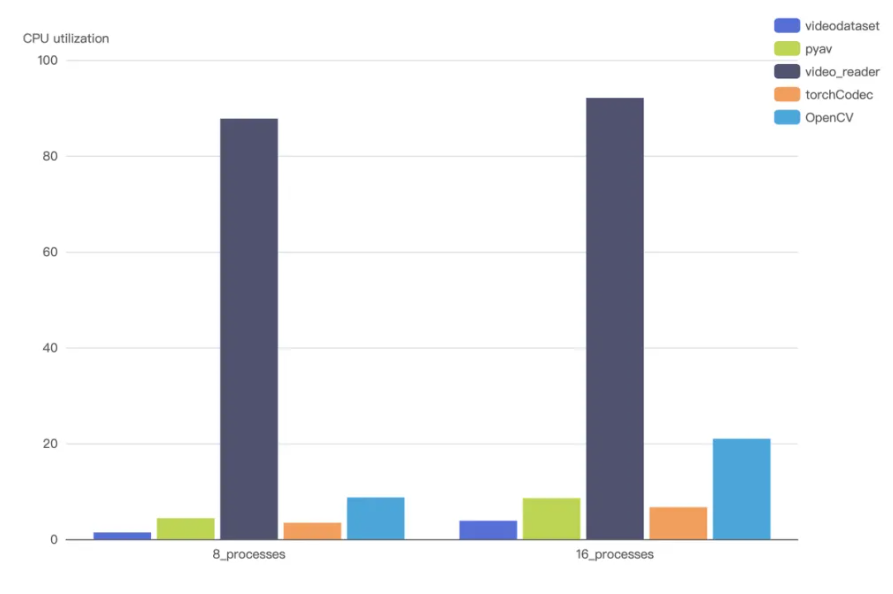
结果显示,VideoDataset与主流 CPU 软件解码方案对比,在解码吞吐量上提升了3到4倍。并且,它能更有效地分担计算负载,从而将解码任务近乎剥离CPU。这一优势使得 VideoDataset 在大规模视频数据训练中不仅能提供更高的解码效率,还能最大限度地利用GPU资源,提高整体训练效率。
![]()
![]()
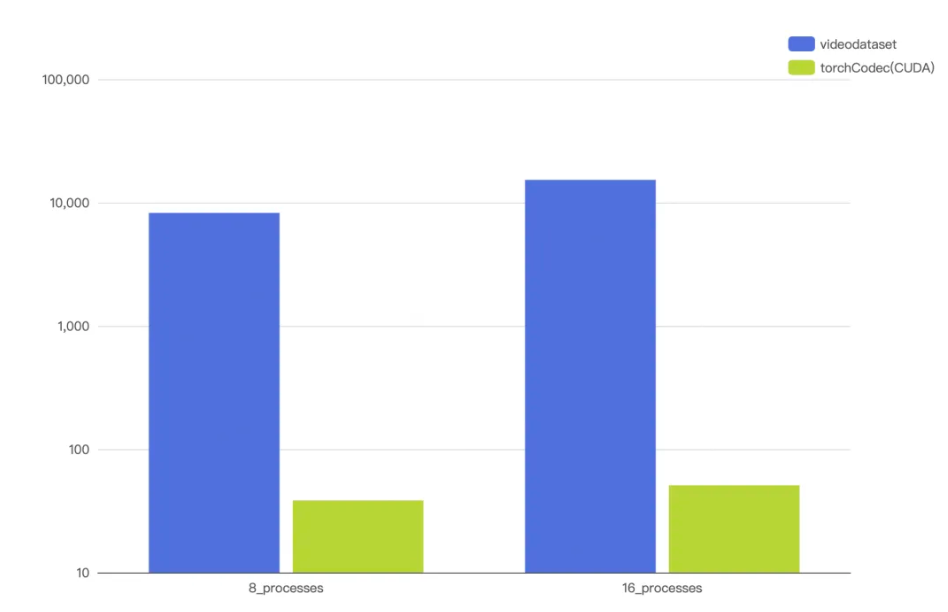
同时,由于支持多解码器复用,在面对实际训练中海量视频随机解码的场景下,VideoDataset 的解码吞吐量相比主流 GPU 硬件解码方案同样也有明显的优势。
![]()
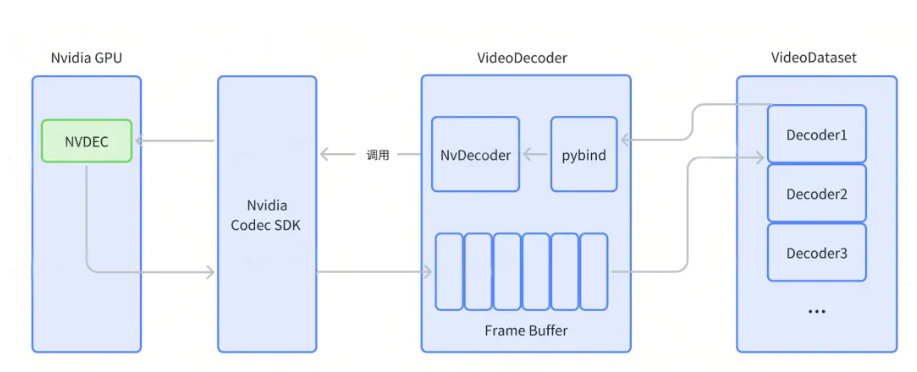
VideoDataset 基于 NVIDIA Video Codec SDK 进行封装,通过多解码器(Decoder)调度和生产者—消费者模型等多种手段实现了解码与训练的完全异步流水线,使解码器利用率达到 90% 以上,提升了解码性能和吞吐量。
并通过将视频进行 GOP 级切分,支持快速定位到关键帧。这样,解码器无需解码整个 GOP,只需要解码到目标帧即可停止,从而实现了高效的随机寻帧。还解决了 Python 多进程(spawn/fork)与 CUDA Context 的冲突,确保在 DataLoader 多 worker 模式下稳定运行。
公告透露,VideoDataset 接下来的版本更新将包括:
- 支持多级流水线优化,提升训练流程的灵活性与效率;
- 完全支持Lerobot,推动生态系统的互联互通;
- 面向PB级数据的分布式存储加载,处理海量数据不再是难题;
- 更多视频格式的兼容,助力与HuggingFace生态深度集成。