马斯克:希望下个月毫无保留地开源 X 平台全部代码
马斯克近日在 X 平台发文透露, X 在向人们展示“引人入胜的内容 ” 这一方面进展迅速,希望下个月就能开源 X 的全部代码,毫无保留。 马斯克此次回复的帖子来自博主 Robert Scoble ,大意是 “X 上的氛围正在发生变化。 因为 AI 在全球的重要性不断提升,而 X 已经成为 AI 行业的核心阵地。” 此前,马斯克今年已陆续开源了 Grok 2.5 模型及自家的百科平台 Grokpedia。
美团 LongCat 团队正式发布并开源 LongCat-Image 模型,通过高性能模型架构设计、系统性的训练策略和数据工程,以6B参数规模,成功在文生图和图像编辑的核心能力维度上逼近更大尺寸模型效果。
根据介绍,LongCat-Image 采用文生图与图像编辑同源的架构设计,并结合渐进式学习策略,在仅 6B 的紧凑参数规模下,实现了指令遵循精准度、生图质量与文字渲染能力的高效协同提升。尤其在单图编辑的可控性和文字生成的汉字覆盖度方面独具优势。
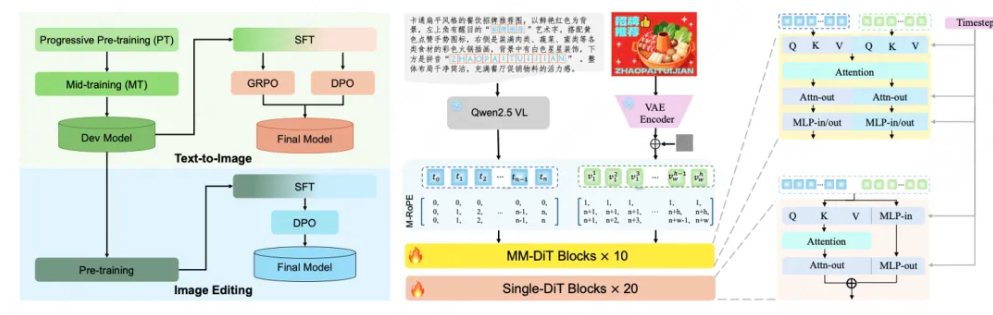
LongCat-Image 在图像编辑领域的多个重要基准测试中(如GEdit-Bench、ImgEdit-Bench)均达到开源SOTA水平,实现性能突破的背后在于一套紧密协同的训练范式和数据策略。为有效继承文生图模型的知识和美感,同时避免文生图后训练阶段收窄的状态空间对编辑指令多样性的限制,基于文生图Mid-training阶段模型进行初始化,并采用指令编辑与文生图多任务联合学习机制,深化对复杂多样化指令的理解。此外通过预训练阶段的多源数据及指令改写策略,以及SFT阶段引入人工精标数据,最终实现了指令遵循精准度、泛化性和编辑前后视觉一致性的共同提升。
针对中文文本渲染这一行业痛点,LongCat-Image 通过课程学习策略来提升字符覆盖度和渲染精准度:预训练阶段基于千万量级合成数据学习字形,覆盖通用规范汉字表的8105个汉字;SFT 阶段引入真实世界文本图像数据,提升在字体、排版布局上的泛化能力;RL 阶段融入 OCR 与美学双奖励模型,进一步提升文本准确性与背景融合自然度。此外通过对 prompt 中指定渲染的文本采用字符级编码,大幅降低模型记忆负担,实现文字生成学习效率的跨越式提升。通过该项能力加持,有效支持海报设计、商业广告作图场景中复杂笔画结构汉字的渲染,以及古诗词插图、对联、门店招牌、文字Logo等设计场景的生僻字渲染。
此外,LongCat-Image通过系统性的数据筛选与对抗训练框架,实现了出图纹理细节和真实感的提升。预训练和中期训练阶段严格过滤AIGC数据,避免陷入“塑料感”纹理的局部最优;在SFT阶段,所有数据均经过人工精筛来对齐大众审美;在RL阶段,创新性地引入AIGC内容检测器作为奖励模型,利用其对抗信号逆向引导模型学习真实世界的物理纹理、光影和质感。
基准测评结果表明,在图像编辑任务中,ImgEdit-Bench(4.50分)、 GEdit-Bench 中英文得分(7.60/7.64分)均达到开源SOTA水平,且逼近头部闭源模型水平;在文字渲染方面,ChineseWord 评测以 90.7 分的成绩大幅领先所有参评模型,实现常用字、生僻字的全量精准覆盖;文生图任务上,GenEval 0.87 分、DPG-Bench 86.8 分的表现,使其在生图基础能力上相比头部开源与闭源模型依然具备强竞争力。
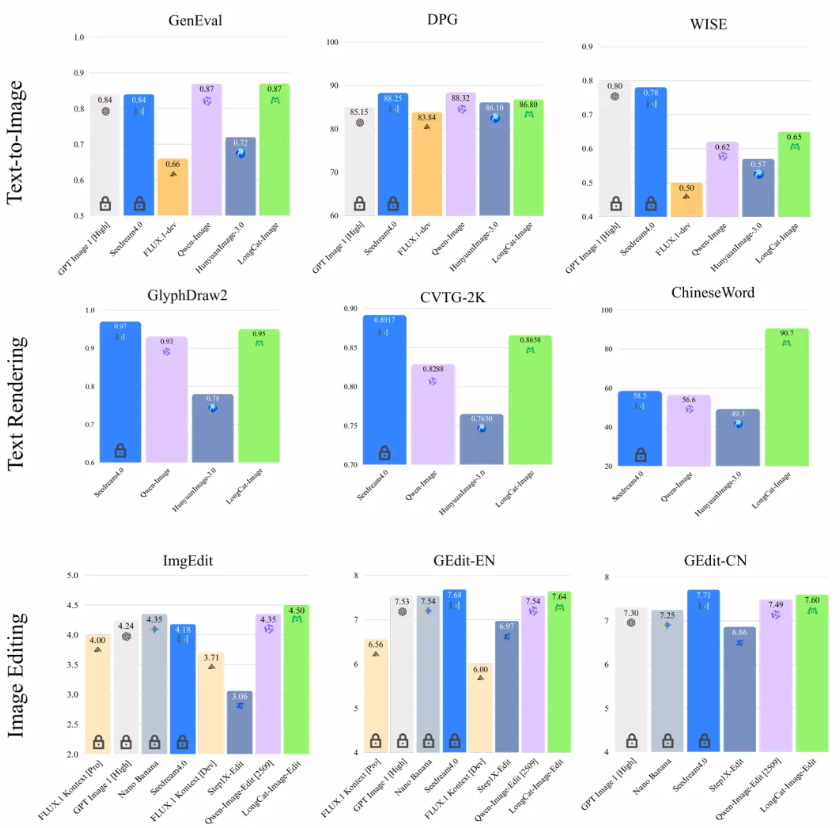
在文生图方面采用大规模的人工主观评分(MOS)方法,核心覆盖 文本-图像对齐、视觉合理度、视觉真实度、美学质量4个维度,LongCat-Image 的真实度相比主流开闭源模型表现出色,同时在文本-图像对齐与合理度上达到开源SOTA水平。
在图像编辑方面采用严格的并列对比评估(Side-by-Side, SBS)方法,聚焦于综合编辑质量、视觉一致性这两个用户体验的维度,评测结果表明,LongCat-Image 虽然与 Nano Banana、Seedream 4.0 等商业模型存在一定差距,但显著超越了其他开源方案。

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Spring框架(Spring Framework)是由Rod Johnson于2002年提出的开源Java企业级应用框架,旨在通过使用JavaBean替代传统EJB实现方式降低企业级编程开发的复杂性。该框架基于简单性、可测试性和松耦合性设计理念,提供核心容器、应用上下文、数据访问集成等模块,支持整合Hibernate、Struts等第三方框架,其适用范围不仅限于服务器端开发,绝大多数Java应用均可从中受益。
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。
WebStorm 是jetbrains公司旗下一款JavaScript 开发工具。目前已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273