大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
在上一篇我们介绍了 OpenSearch —— 那个因协议争议而诞生的开源搜索分支。今天,我们把目光转向国内,聊聊极限科技研发的一款轻量级搜索引擎:Easysearch。
引言
在搜索技术的世界里,从 Lucene 的出现到 Solr、Elasticsearch 的崛起,搜索引擎技术已经发展了二十余年。然而,随着开源协议的变更与国际形势的变化,国产自主搜索引擎的需求愈发迫切。在这样的背景下,Easysearch 作为一款自主可控、轻量高效、兼容 Elasticsearch 的分布式搜索引擎应运而生,为国内企业带来了全新的选择。
![]()
Easysearch 概述
Easysearch 是一款分布式搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析、AI 集成等。Easysearch 衍生自开源协议 Apache 2.0 的 Elasticsearch 7.10 版本,并不断往前迭代更新,紧跟 Lucene 最新版本的更新。Easysearch 可以替代 Elasticsearch,同时添加和完善多项企业级功能。
诞生背景:为什么要有 Easysearch?
Easysearch 由极限科技(INFINI Labs)团队推出。项目的起点源于团队长期在搜索引擎和大数据领域的深厚实践积累,团队深刻认识到国内企业在使用 Elasticsearch 时普遍面临以下痛点:
- 开源协议变化带来的商业风险 —— Elastic 于 2021 年将许可更改为 SSPL,导致社区分裂,增加了企业在合规和商用上的不确定性;
- 高并发与高可靠性场景下对稳定可控方案的需求 —— 企业级应用亟需一个性能可靠、可深度优化的搜索基础设施;
- 技术栈自主可控的迫切需求 —— 随着国产化进程加快,国内生态中缺乏轻量化、易部署、且完全可控的搜索引擎产品;
- 本地化服务与快速响应能力的缺口 —— 国内企业更需要本地团队提供高效的技术支持与服务,对本土化、个性化功能需求能得到及时响应与反馈。
基于这些考虑,Easysearch 在设计之初就明确了目标:构建一款兼容 Elasticsearch API、简洁易用、性能出众且完全自主可控的国产搜索引擎。
核心特性
- 轻量级:安装包大小不到 60 MB,安装部署简洁,资源占用低,开箱即用;
- 跨平台:支持主流操作系统和 CPU 架构,支持国产信创运行环境;
- 高性能:针对不同场景进行的极致优化,可用更少硬件成本获得更高服务性能,降本增效。
- 稳定可靠:修复大量内核问题,解决内存泄露,集群卡顿、查询缓慢等问题,久经严苛业务环境考验。
- 安全增强:默认就提供完整的企业级安全功能,支持 LDAP/AD 集成,支持索引、文档、字段粒度细权管控。
- 兼容性强:兼容 Elasticsearch 7.x 的 REST API 和数据格式,迁移成本低;
- 可视化运维:无需 Kibana 即可通过内置 Web UI 插件界面管理索引、节点与监控指标等。
对比优势
| 对比维度 |
Easysearch |
Elasticsearch |
OpenSearch |
| 用户协议 |
社区免费+商业授权 |
SSPL/AGPL v3 |
Apache 2.0 |
| API 兼容性 |
高度兼容 ES |
原生 |
高度兼容 ES |
| 最小安装体积 |
57MB |
482MB |
682MB |
| 部署复杂度 |
简单 |
中等 |
相对复杂 |
| 信创环境支持 |
全面兼容 |
无 |
无 |
| 可视化管理 |
开箱即用管理后台 |
需独立部署 Kibana |
需独立部署 OpenSearch Dashboards |
| 本地化与中文支持 |
强 |
弱 |
弱 |
| AI 插件支持 |
较弱 |
强 |
较强 |
| 社区与生态 |
快速成长中 |
成熟广泛 |
活跃增长 |
由于笔者对于 Easysearch 的喜爱造成了明显的倾向性,以上对比仅供参考,萝卜白菜,各有所爱,其实都不错 :)
快速开始:5 分钟体验 Easysearch
1. 使用 Docker 启动
# 直接运行镜像使用随机密码(数据及配置未持久化)
docker run --name easysearch \
--ulimit memlock=-1:-1 \
-p 9200:9200 \
infinilabs/easysearch:1.15.4
2. 验证集群状态
curl -ku "username:password" -X GET "https://localhost:9200/"
返回结果示例:
{
"name": "easysearch-node",
"cluster_name": "easysearch-6yhwn91v80gf",
"cluster_uuid": "Gfu_fuF1QViJfeUWVbiFCA",
"version": {
"distribution": "easysearch",
"number": "1.15.4",
"distributor": "INFINI Labs",
"build_hash": "9110128946b0af3de639966cfa74b5498346949d",
"build_date": "2025-10-14T03:30:41.948590Z",
"build_snapshot": false,
"lucene_version": "8.11.4",
"minimum_wire_lucene_version": "7.7.0",
"minimum_lucene_index_compatibility_version": "7.7.0"
},
"tagline": "You Know, For Easy Search!"
}
3. 索引与搜索示例
# 写入文档
curl -ku "username:password" -X POST "https://localhost:9200/my_index/_doc" -H 'Content-Type: application/json' -d'
{
"title": "Easysearch 入门",
"content": "这是一个轻量级搜索引擎的示例文档。",
"tags": ["搜索", "国产", "轻量级"]
}'
# 搜索文档
curl -ku "username:password" -X GET "https://localhost:9200/my_index/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"content": "搜索引擎"
}
}
}'
4. 使用 Easysearch UI
Easysearch 提供了轻量级界面化管理功能,不再依赖第三方组件即可对集群进行管理,真正做到开箱即用。如果你安装了 Easysearch UI 插件或者下载捆绑包,可通过 https://localhost:9200/_ui/ 访问,进行节点、索引、分片、查询调试和监控查看等管理。
图1:系统登录
![]()
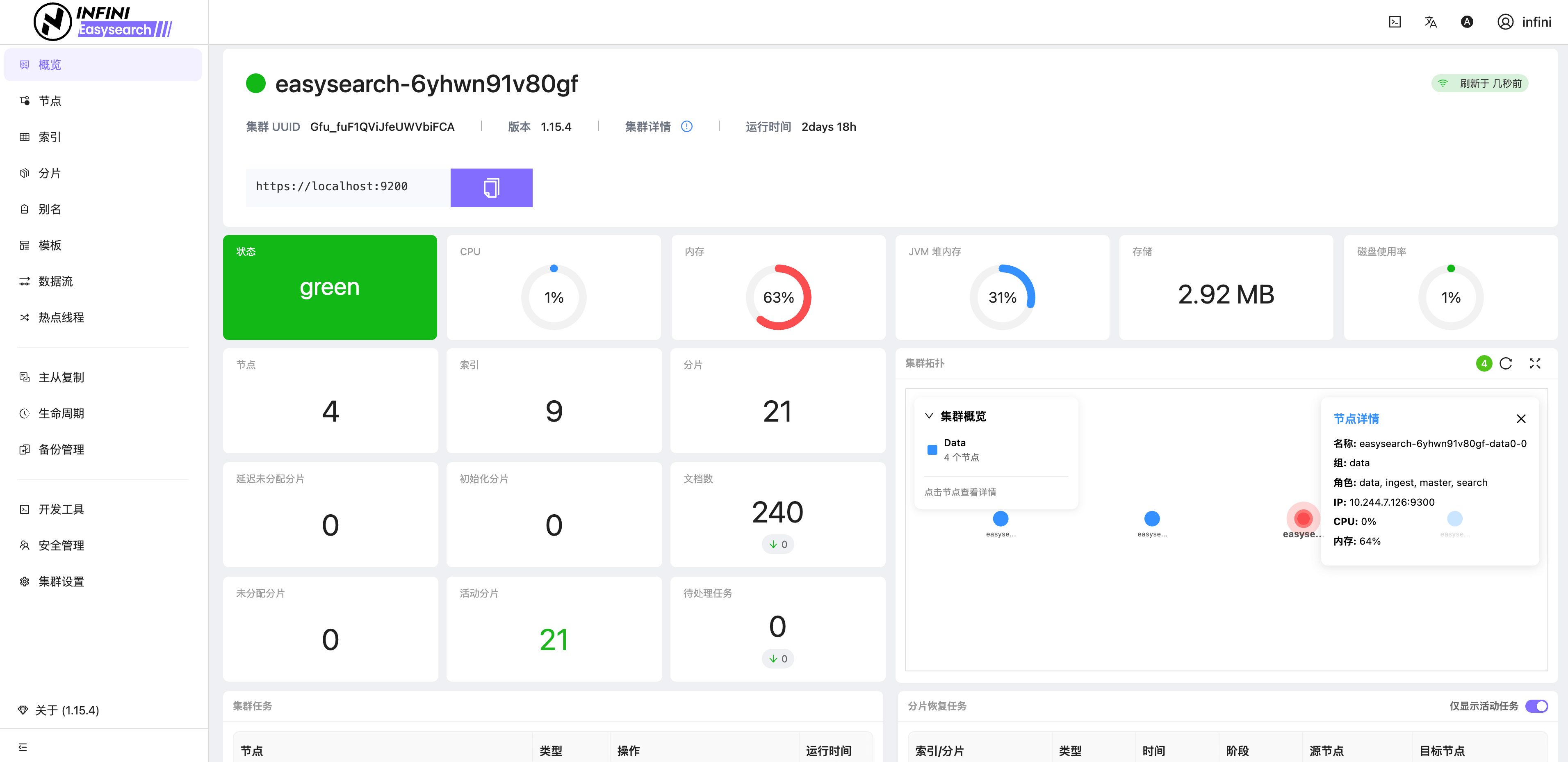
图2:集群概览
![]()
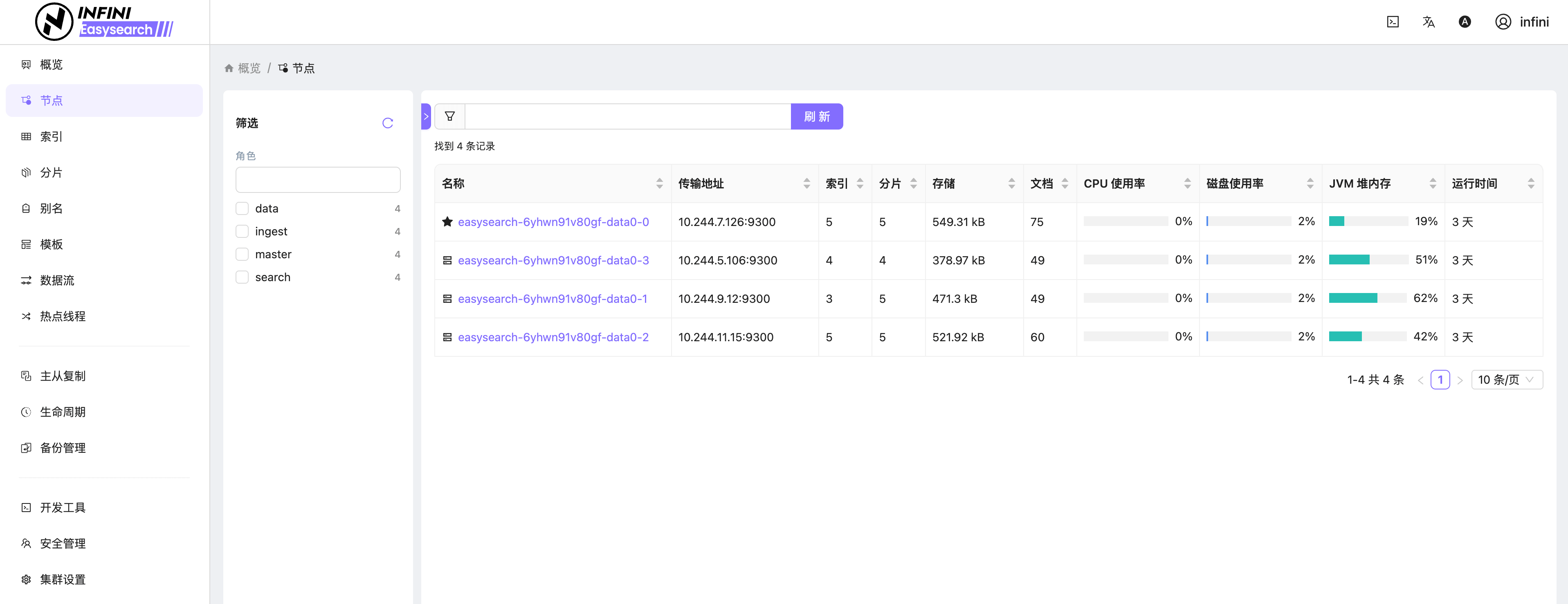
图3:节点列表
![]()
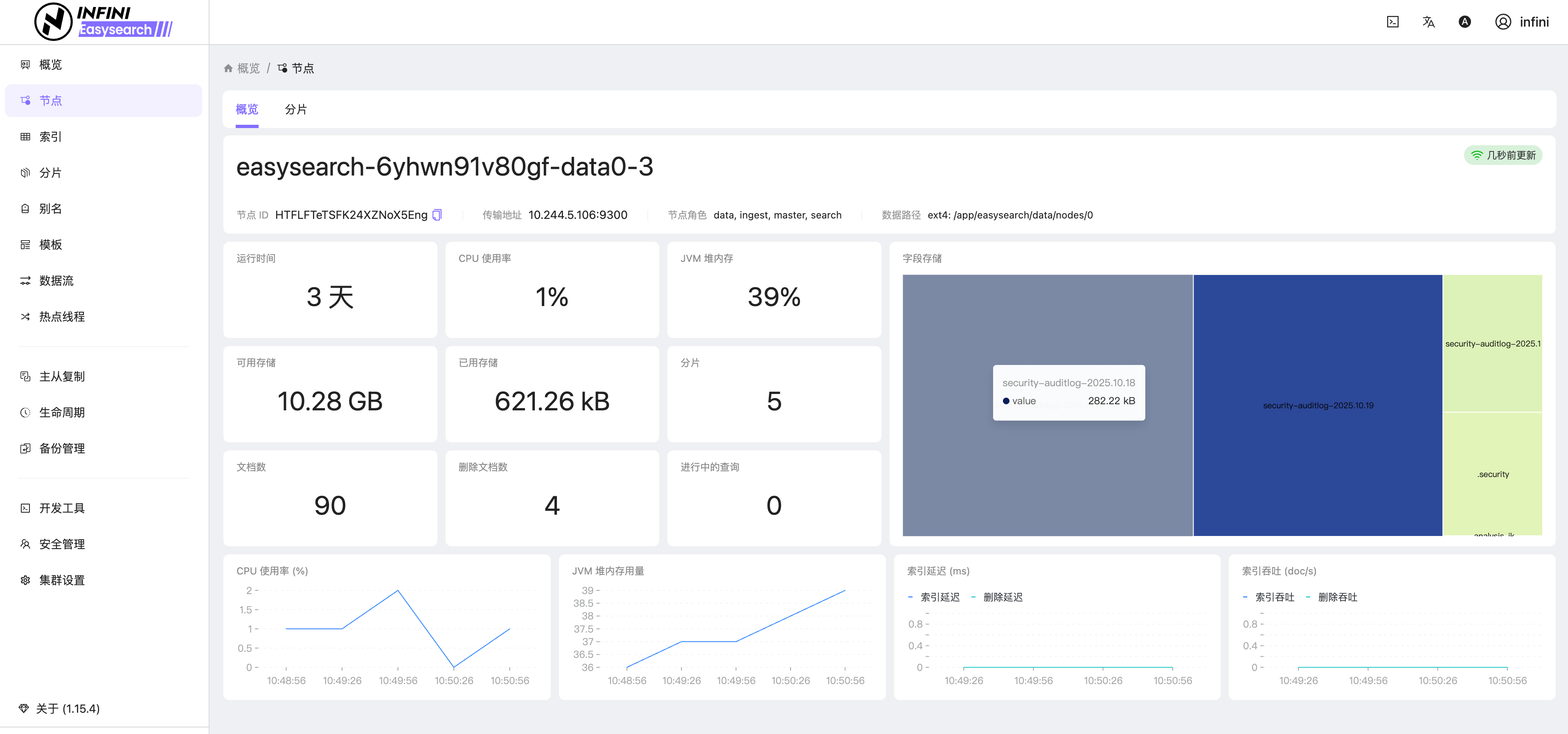
图4:节点概览
![]()
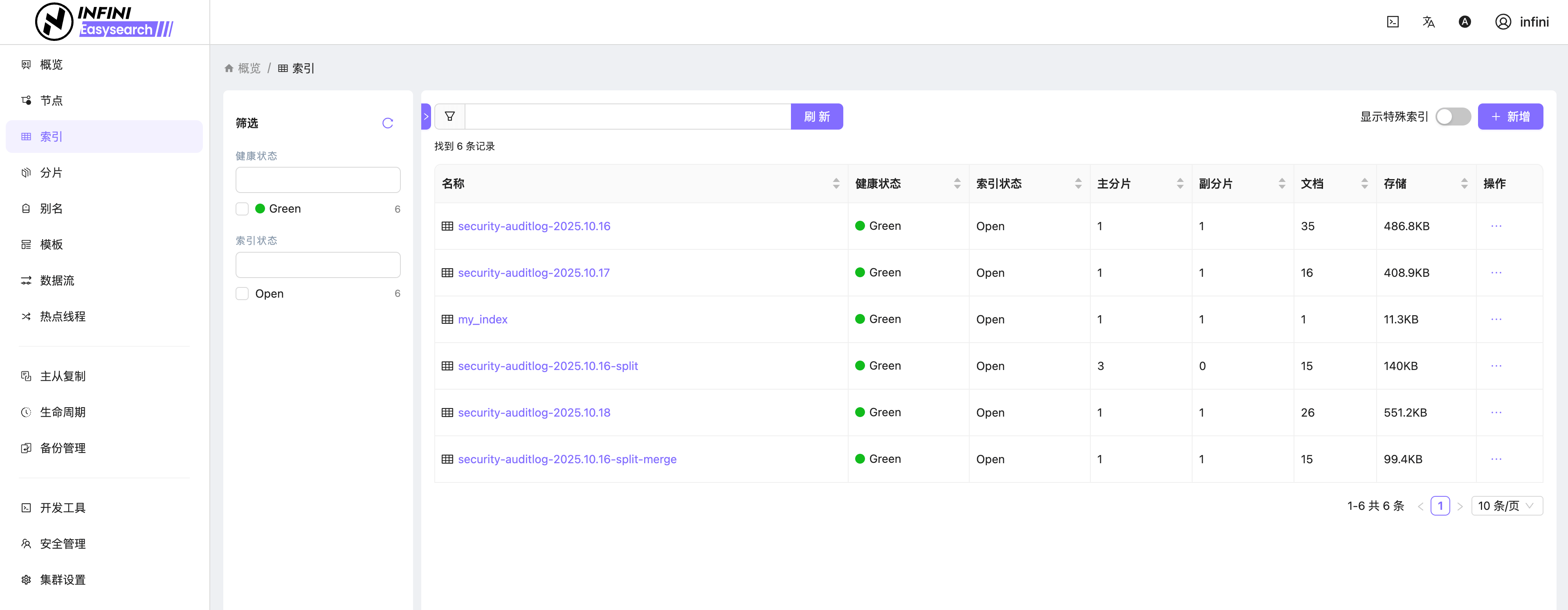
图5:索引列表
![]()
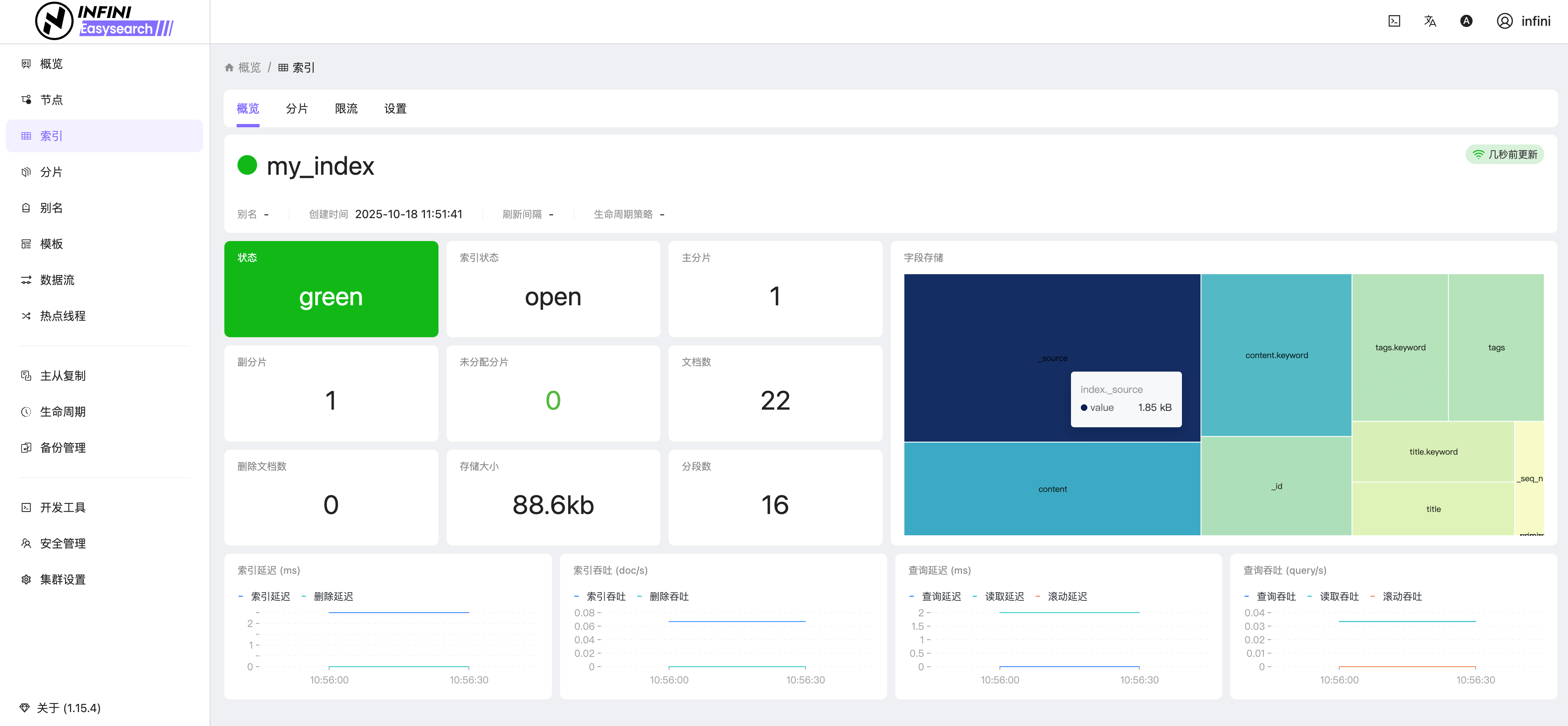
图6:索引概览
![]()
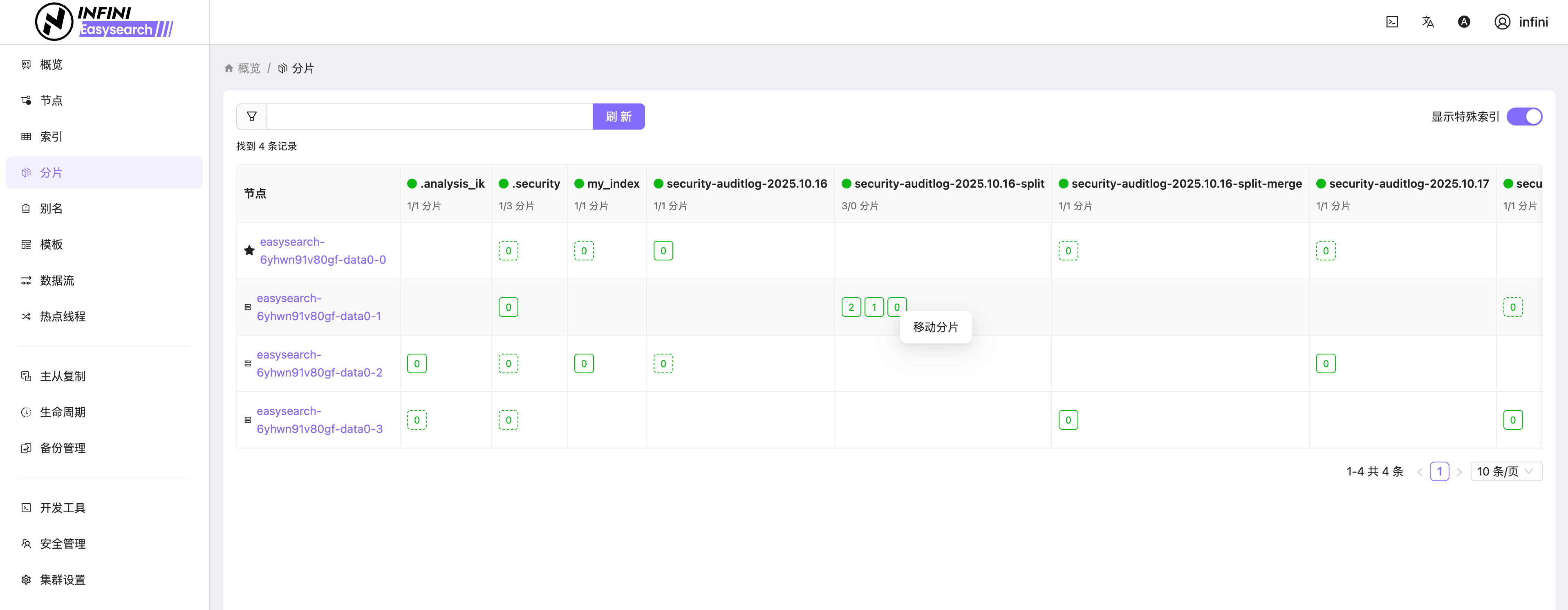
图7:分片管理
![]()
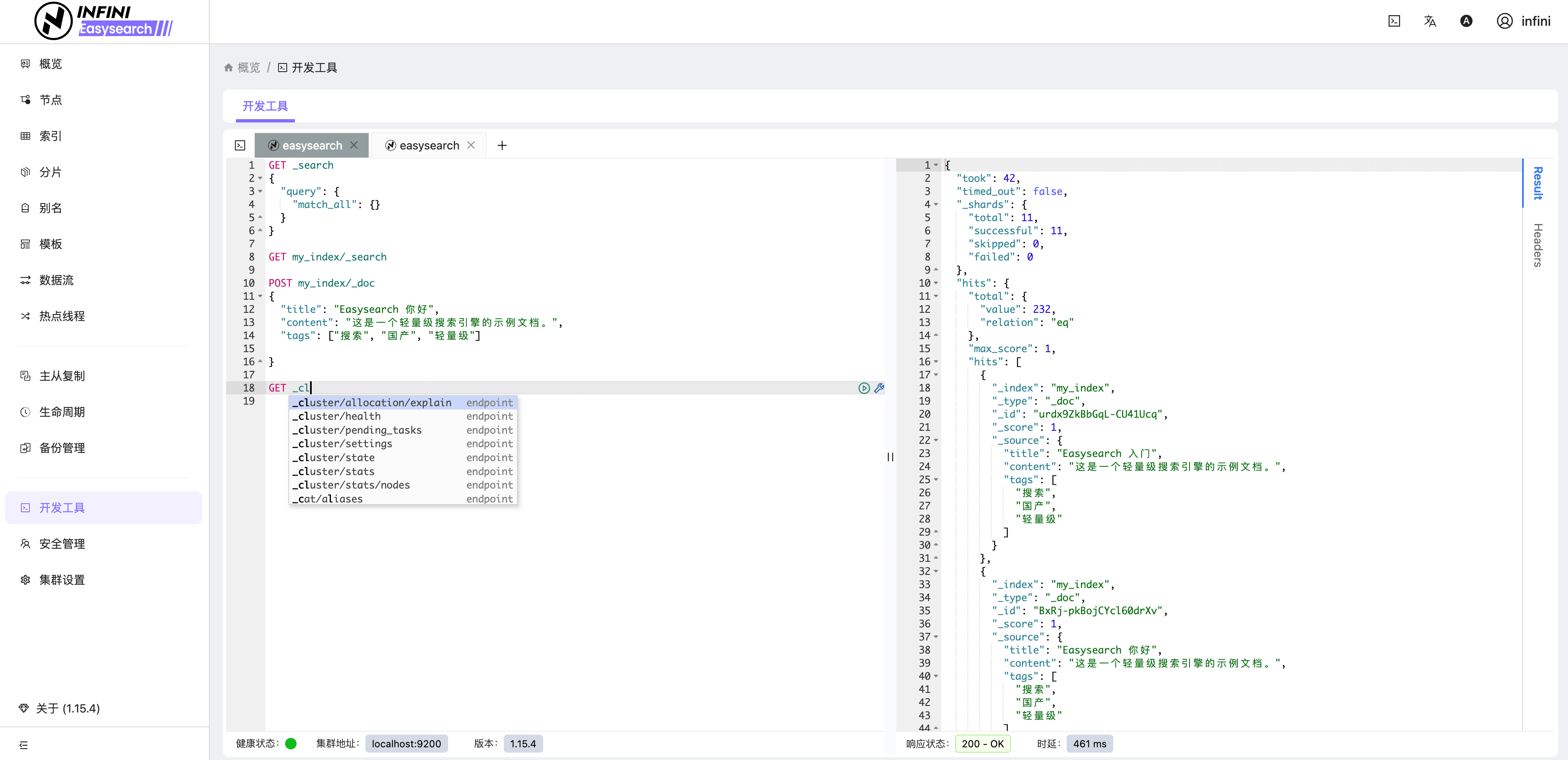
图8:开发工具
![]()
以上仅列出了一些基本功能,其他如安全管理、主从复制、备份管理、生命周期管理等更多高级功能由于篇幅限制不一一展示,有兴趣的朋友可自行部署探索。
结语
Easysearch 的诞生,不仅填补了国产搜索引擎在分布式与轻量化领域的空白,也让更多企业在面对开源协议变动与外部技术依赖时,拥有了更加安全、灵活、可控的选择。
它既是国产替代方案的有力代表,更是新一代搜索技术生态的积极探索者,为企业级实时搜索与分析带来新的可能。
🚀 下期预告
下一篇我们将介绍 一款 AI 驱动的现代搜索引擎 - Meilisearch,基于 Rust 构建的开源搜索引擎,性能高、部署简单。号称比 Elasticsearch 快 10 倍,真的这么牛吗?
💬 三连互动
- 你是否在使用或考虑国产搜索替代方案?
- 在实际项目中,你最看重搜索引擎的哪些特性?(性能、兼容性、运维、成本)
- 对 Easysearch 有什么功能上的期待?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
🔗 参考资源