![]()
本文发布于「NebulaGraph 公众平台」,更多产品资讯请访问「NebulaGraph 官网」
一、精准测试介绍
什么是精准测试?
目前业内尚未形成统一的精准测试实践方案,对其也有多种定义:
(1)精准测试是一套计算机测试辅助分析系统。精准测试的核心组件包含的软件测试示波器、用例和代码的双向追溯、智能回归测试用例选取、覆盖率分析、缺陷定位、测试用例聚类分析、测试用例自动生成系统,这些功能完整的构成了精准测试技术体系。
(2)精准测试是一种测试方法,旨在通过优化测试过程和测试结果,提高软件质量和可靠性。该测试方法结合了自动化和手动化测试技术,以尽可能地覆盖所有的功能和边缘情况,从而减少潜在的缺陷和错误。
为什么要做精准测试?
精准测试是为了解决测试的质量和效率问题。
传统测试主要依赖测试人员的自身经验结合具体需求,分析出可能涉及的功能模块以和受影响的功能模块,从而评估出测试范围。如果想提高精准度,则需要沉浸到代码中去寻找答案,不仅提高了人力成本,更是对测试同学提出了更高的要求,更不适用于敏捷迭代中。
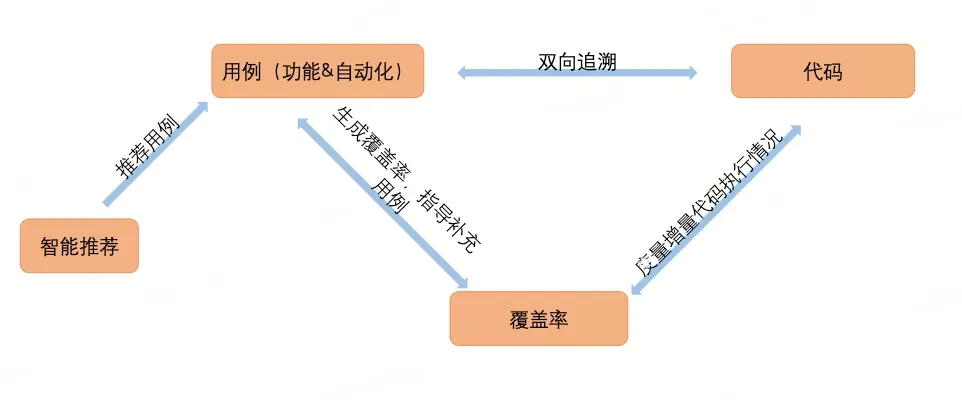
常见的精准测试方案
精准测试核心有两方面:精准推荐(用例推荐、接口、方法等)、测试度量(度量代码被测情况即代码覆盖率)
![]()
二、得物精准测试平台介绍
得物精准测试平台主要负责推荐精准测试范围,减少盲测、漏测、冗测现象。并将 “精准推荐 + 用例执行 + 结果度量”结合形成有机整体,在测试前、测试中、测试后帮助质量团队保质量、提效率。
目前平台已提供服务端 Java/Golang 应用和前端 H5 应用的精准推荐能力。
相比于上文提到的精准测试的定义,其实我们更关注它能给我们带来什么帮助,我们期望精准测试实现以下目标:
![]()
三、得物精准推荐平台的实现方案
得物精准测试平台主要由“精准测试平台”和“推荐引擎(链路分析器、差异分析器、知识库、推荐引擎)”两部分构成。
整体思路是建立由“代码行”反推“代码方法”并逆向追踪“API接口”,以“API接口”为枢纽,推荐“自动化用例、功能用例、资损用例等内容”的精准推荐体系。
我们建立完链路分析器后,会输出完整的方法调用链原数据和 API 入口方法标记信息,即建立了方法与方法、方法与类、类与类、类与接口(interface)、接口(interface)与接口(interface)之间的第一层关系,如:当前方法调用了哪些方法以及当前方法被哪些方法调用了。
但仅有原数据还不能进行变更接口推荐,因为原数据中只维护了一层调用关系,需要借助图数据库来把这些原数据串成一张调用链关系网。
为什么是图数据库?
一方面,由于得物精准测试平台“服务端”推荐技术底层是依赖“方法调用链”的,需要提供多版本推荐和实时查看能力。
另一方面,热点应用总方法量大、方法调用关系复杂、应用数量多、代码版本多、链路收集频率高,传统关系型数据库无法满足这种复杂场景,所以需要寻找一款合适的数据库。
经过调研,得物最终选择使用 NebulaGraph 图数据库来作为底层存储库。
NebulaGraph
“图”在人们的日常生活中出现的频率非常高,开心时发个靓照到朋友圈、网购时看完卖家秀再去评论区看看买家秀,这些都涉及到“图”,也许你想象的图是这样的 ↓↓↓
![]()
但 NebulaGraph 的“图”并非日常生活中常指的“图”。日常说的图一般指的的图片(Image),这里所说的图( Graph)其实是一种“关系图”,更侧重体现事物之间的关系。
一张图(Graph)由一些小圆点(称为顶点或节点,即 Vertex 或 Node)和连接这些圆点的直线或曲线(称为边,即 Edge 或 Relationship)组成。
用 NebulaGraph 探索《权力的关系》人物关系图谱,最终呈现效果这样的 ↓↓↓
![]()
NebulaGraph 是一款开源的分布式高性能图数据库,在 DB-Engines 排名中位列全球图数据库第二,专门用于存储和处理巨大规模的图数据,擅长处理千亿节点万亿条边的超大规模数据集,并且提供毫秒级查询:
得物 NebulaGraph ORM
由于 NebulaGraph 对于 Python 没有提供符合我们预期的 ORM 库,返回的结果是原生的数据格式,使用起来比较麻烦,所以我们自研了轻量级的 NebulaGraph ORM.
我们的精准测试方法的调用链中,主要涉及到 2 种点类型和 4 种边类型,将方法和类(类或接口)设计成 2 种点类型,将方法与方法、类与类、方法与类、变更方法与类这四种关系设计成“边类型”,具体模型定义如下:
class JMethodTag(Tag):Java 方法-点类型,存储方法的相关属性信息
class JMethodTag(Tag):
"""
Java方法-点类型
"""
__NAME_PREFIX__ = 'tjm_'
__VID_PREFIX__ = 'tjm_' # vid前缀
vid = Vid('vid', String, nullable=False, comment='点ID')
name = Field('name', String, nullable=False, comment='简称')
sign = Field('sign', String, nullable=False, comment='签名(全称)', index_len=50)
type = Field('type', String, default='', nullable=False, comment='方法类型(method,constructor,static,get_set,field)')
pkName = Field('pkName', String, default='', nullable=False, comment='包名')
abs = Field('abs', Bool, default=False, nullable=False, comment='是否是抽象类')
api = Field('api', Bool, default=False, nullable=False, comment='是否是API接口', index_len=None)
aPtl = Field('aPtl', String, default='', nullable=False, comment='接口协议(http,dubbo,grpc)', index_len=20)
aPath = Field('aPath', String, default='', nullable=False, comment='API接口路径(http: /xx/xx, dubbo: com.xx.xx.Cxx::mxx, /grpc.CntCenterService/MGetTrendInfo)', index_len=100)
cName = Field('cName', String, default='', nullable=False, comment='所属类简称')
cSign = Field('cSign', String, default='', nullable=False, comment='所属类签名', index_len=50)
cType = Field('cType', String, default='', nullable=False, comment='所属类类型(class,interface,annotation,enum,unknown)')
parNames = Field('parNames', String, default='', nullable=False, comment='参数名(多个";"分割)')
parTypes = Field('parTypes', String, default='', nullable=False, comment='参数类型名(多个";"分割)')
retType = Field('retType', String, default='', nullable=False, comment='返回类型名')
calls = Field('calls', String, default='', nullable=False, comment='调用哪些方法调用(多个";"分割)')
usages = Field('usages', String, default='', nullable=False, comment='被哪些方法调用(多个";"分割)')
sLine = Field('sLine', Int, default=0, nullable=False, comment='开始行(从1开始)')
eLine = Field('eLine', Int, default=0, nullable=False, comment='结束行')
zsScan = Field('zsScan', String, default='', nullable=False, comment='资损字段')
class JClassTag(Tag):Java类-点类型,存储类/接口的相关属性信息
class JClassTag(Tag):
"""
Java类-点类型
"""
__NAME_PREFIX__ = 'tjc_'
__VID_PREFIX__ = 'tjc' # vid前缀
vid = Vid('vid', String, nullable=False, comment='点ID')
name = Field('name', String, nullable=False, comment='简称')
sign = Field('sign', String, nullable=False, comment='签名(全称)', index_len=50)
type = Field('type', String, default='', nullable=False, comment='类类型(class,interface,annotation,enum,unknown)')
pkName = Field('pkName', String, default='', nullable=False, comment='包名')
abs = Field('abs', Bool, default=False, nullable=False, comment='是否是抽象类')
dApi = Field('dApi', Bool, default=False, nullable=False, comment='是否是dubbo接口类')
dInf = Field('dInf', String, default='', nullable=False, comment='dubbo接口interface值')
hPrefix = Field('hPrefix', String, default='', nullable=False, comment='http接口路径前')
faces = Field('faces', String, default='', nullable=False, comment='被我实现的接口(多个";"分割)')
impls = Field('impls', String, default='', nullable=False, comment='实现我的接口(多个";"分割)')
p = Field('p', String, default='', nullable=False, comment='我继承的父类')
subs = Field('subs', String, default='', nullable=False, comment='继承我的子类(多个";"分割)')
sLine = Field('sLine', Int, default=0, nullable=False, comment='开始行(从1开始)')
eLine = Field('eLine', Int, default=0, nullable=False, comment='结束行')
zsScan = Field('zsScan', String, default='', nullable=False, comment='资损字段')
class JClassClassEdge(Edge):Java类->类-边类型
classJClassClassEdge(Edge):
"""
Java类->类-边类型
"""
__NAME_PREFIX__ = 'ejcc_'
FACE_RELATION = 'face'
PARENT_RELATION = 'parent'
src_vid = Vid('src_vid', String, nullable=False, comment='起始点ID')
dst_vid = Vid('dst_vid', String, nullable=False, comment='目的点ID')
relation = Field('relation', String, default='', nullable=False, comment='类->类关系(face: 我实现的接口, parent: 我的父类)')
class JMethodMethodEdge(Edge):Java方法->方法-边类型
classJMethodMethodEdge(Edge):
"""
Java方法->方法-边类型
"""
__NAME_PREFIX__ = 'ejmm_'
CALL_RELATION = 'call'
REWRITE_RELATION = 'rewrite'
HEAVY_LOD_RELATION = 'heavy_load'
src_vid = Vid('src_vid', String, nullable=False, comment='起始点ID')
dst_vid = Vid('dst_vid', String, nullable=False, comment='目的点ID')
relation = Field('relation', String, default='', nullable=False, comment='方法->方法关系(call: 调用, rewrite: 重写,heavy_load:重载)')
api = Field('api', Bool, default=False, nullable=False, comment='src(开始)点是否是接口')
class JMethodClassEdge(Edge):Java方法->类-边类型
classJMethodClassEdge(Edge):
"""
Java方法->类-边类型
"""
__NAME_PREFIX__ = 'ejmc_'
MYC_RELATION = 'myc'
src_vid = Vid('src_vid', String, nullable=False, comment='起始点ID')
dst_vid = Vid('dst_vid', String, nullable=False, comment='目的点ID')
relation = Field('relation', String, default='', nullable=False, comment='方法->类关系(myc: 我的类)')
class JChangeClassMethodEdge(Edge):Java变更(类->方法)-边类型
classJChangeClassMethodEdge(Edge):
"""
Java变更(类->方法)-边类型
- 推荐接口任务产生的增量方法和类
"""
__NAME_PREFIX__ = 'ejccm_'
src_vid = Vid('src_vid', String, nullable=False, comment='起始点ID')
dst_vid = Vid('dst_vid', String, nullable=False, comment='目的点ID')
contrast_v = Field('contrast_v', String, default='', nullable=False, comment='对比版本(commit)')
调用链展示
![image|690x195]()
![image|690x448]()
使用 NebulaGraph 获取调用链信息
获取到变更类下面的方法
(先获取目标点ID,再根据点ID查询点数据性能最佳),查询语句如下:
MATCH (v:{tag_name}) WHERE v.{tag_name}.cSign IN [{cSignsStr}] RETURN id(v);
MATCH (v:{tag_name}) WHERE id(v) IN [{tag_name_vid_str}] RETURN v;
使用点 ID 根据“JMethodMethodEdge 边”遍历找出调用链中是接口的入口方法
这里使用 GO 语句,并设置 1 到 50 跳来遍历(即从原始点开始找 50 层关系,如:a() -> b() -> c(),则a()到b()是 1 跳,b()到c()是 1 跳,a()到c() 是 2 跳
GO 1 TO 50 STEPS FROM {vid_str} OVER {edge_name} REVERSELY WHERE properties(edge).api == true YIELD DISTINCT src(edge);
查找增量类和增量方法
通过“JChangeClassMethodEdge 边”的属性“contrast_v”的值来判断哪些是目标增量边,根据增量边的起始点 ID 和结束点 ID 来获取最终的增量方法和增量类
MATCH (v_c:{c_tag_name})-[e:{ccme_name}]->(v_m:{m_tag_name}) RETURN e, v_m;
如:获取增量变更方法
defget_add_java_method(self, **kwargs) -> ResponseResult:
"""获取增量变更方法"""
app_name = kwargs.get('app_name')
current_version = kwargs.get('current_version')
contrast_version = kwargs.get('contrast_version')
zs_scan = kwargs.get('zs_scan')
...
tag_handler = TagHandler(app_name, current_version)
c_tag_name = tag_handler.get_tag_name(JClassTag)
m_tag_name = tag_handler.get_tag_name(JMethodTag)
edge_handler = EdgeHandler(app_name, current_version)
ccme_name = edge_handler.get_edge_name(JChangeClassMethodEdge)
# 模版 MATCH (v_c:tag_name1)-[e:edge_name]->(v_m:tag_name2) RETURN e, v_m;
n_gql = f"MATCH (v_c:{c_tag_name})-[e:{ccme_name}]->(v_m:{m_tag_name}) RETURN e, v_m;"
_res = edge_handler.session.execute_json(n_gql)
if type(_res) is bytes:
_res = _res.decode(encoding='utf-8')
# Nebula Graph Studio前端客户端工具报【-1009:SemanticError: PlanNode(Start) not support to append an input.】错是客
# 户端版本不匹配,代码里可以支持
res: dict = json.loads(_res)
if res['errors'][0]['code'] != 0:
err = f"{res['errors'][0]['code']}:{res['errors'][0].get('message')}"
return ResponseResult.fail_response(message='获取增量变更方法失败', err=err)
# 筛选&组装数据
raws = res['results'][0]['data']
res_class_zs = []
res_method_rows = []
class_zs_dict = {}
for raw in raws:
_inner_row = raw['row']
# 对比版本commitID只取前8位
if _inner_row[0]['contrast_v'][:8] == contrast_version[:8]:
_new_row = {
"meta": [{
"type": "vertex",
"id": raw['meta'][1]['id']
}],
"row": [_inner_row[1]]
}
res_method_rows.append(_new_row)
method_tags: List[JMethodTag] = tag_handler.convert_raw_to_tag_model(res_method_rows, JMethodTag)
# 获取类的资损标签
if zs_scan and method_tags:
cSign_set = set()
# 获取增量类
for method_tag in method_tags:
_fsr_cSign = String.fsr(method_tag.cSign)
if _fsr_cSign notin cSign_set:
cSign_set.add(_fsr_cSign)
n_gql = f'MATCH (v:{c_tag_name}) ' \
f'WHERE v.{c_tag_name}.zsScan != "" AND v.{c_tag_name}.sign IN [{",".join(cSign_set)}] ' \
f'RETURN v.{c_tag_name}.sign, v.{c_tag_name}.zsScan;'
_res = edge_handler.session.execute_json(n_gql)
if type(_res) is bytes:
_res = _res.decode(encoding='utf-8')
# 户端版本不匹配,代码里可以支持
res: dict = json.loads(_res)
if res['errors'][0]['code'] != 0:
err = f"{res['errors'][0]['code']}:{res['errors'][0].get('message')}"
return ResponseResult.fail_response(message='获取增量变更方法失败', err=err)
raws = res['results'][0]['data']
for raw in raws:
_row = raw['row']
class_zs_dict[_row[0]] = {
'class_sign': _row[0],
'zs': _row[1]
}
class_infos = []
class_tag_info_dict = {}
class_n = 0
for method_tag in method_tags:
class_tag_info = class_tag_info_dict.get(method_tag.cSign)
if class_tag_info isNone:
class_tag_info = class_tag_info_dict[method_tag.cSign] = {
'class_sign': method_tag.cSign,
'class_zs': ''if class_zs_dict.get(method_tag.cSign) isNoneelse class_zs_dict.get(method_tag.cSign)['zs'],
'methods': []
}
class_infos.append(class_tag_info)
class_n += 1
# 转化成JSON
_method_tag = method_tag.__dict__.copy()
_calls = _method_tag['calls']
_method_tag['calls'] = _calls.split(';') if _calls else []
_usages = _method_tag['usages']
_method_tag['usages'] = _usages.split(';') if _usages else []
class_tag_info['methods'].append(_method_tag)
return ResponseResult.success_response(data={'class_n': class_n, 'method_n': len(method_tags),
'class_infos': class_infos})
四、总结与展望
精准测试是一套有效提高软件测试质量和效率的技术体系,可以有效解决传统测试中的盲测、漏测、冗测等现象提升测试效率和准确性,前置暴露风险,保障上线质量。
精准测试从理念走向落地的关键,在于能否构建一条高效、可靠的“数据驱动链”,而 NebulaGraph,正是锻造这条链条的核心引擎 。凭借其卓越存储与关联查询能力,NebulaGraph 将原本散落、静态的代码方法,编织成一张动态、立体的调用关系网。
未来,我们期待能与 NebulaGraph 开源社区更紧密地协同共建,将得物在复杂业务场景下的实战经验反哺社区,共同推动图技术的创新与应用。
本文发布于「NebulaGraph 公众平台」,更多产品资讯请访问「NebulaGraph 官网」
本文转自「得物技术」公众号⬇️
得物精准测试平台设计与实现
推荐阅读
NebulaGraph 全球图数据库排名第二
复杂关系场景,图数据库为何是首选?
开源版、企业版怎么选?产品对比+选型指南奉上~