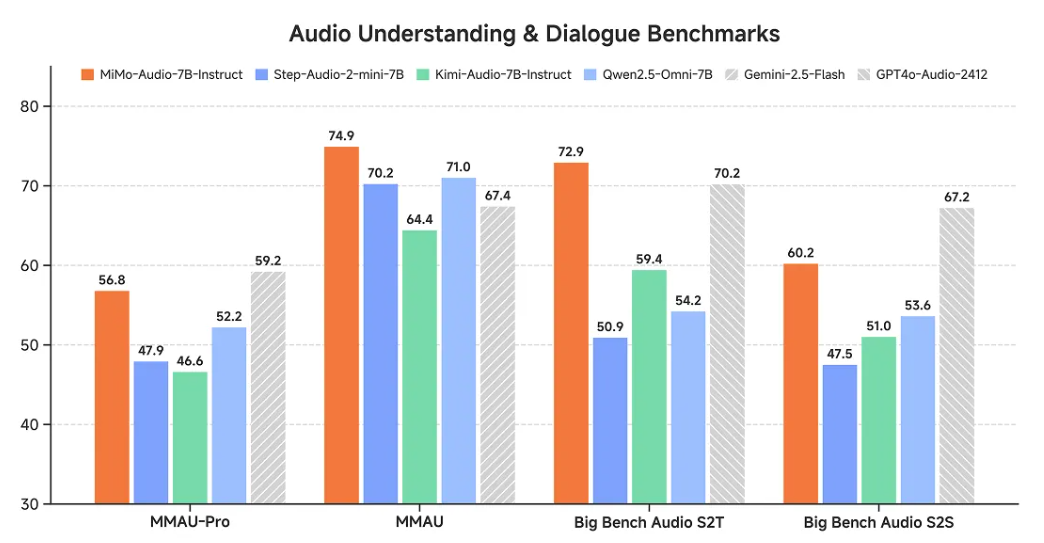

开放签企业版电子签章系统正式开源!
2025年9月19日,开放签团队正式宣布电子签章系统企业版开源,同步迎来资源律动公司成立6周年。感谢这六年里为项目付出技术心血的同事、提供场景支持的伙伴,以及每一位关注开放签成长的开发者!自2023年11月工具版开源以来,我们与社区共同打磨产品,累计收获1100+ Star、600+ Fork,并服务200+企业用户。此次企业版开源,标志着开放签正式迈入全栈开源阶段——通过代码透明化与社区协作,推动电子签行业从“技术黑盒”向“可信普惠”转型。 开源核心价值:让电子签回归“简单与可信” 技术透明:消除“电子签=神秘黑盒”的顾虑 开放签企业版完整开源所有核心代码(包括签名引擎、文档处理、权限管理等模块),开发者可自主审查安全逻辑、修改适配业务需求,彻底打破传统电子签系统“封闭性”的壁垒。无论是小型创业团队还是大型企业,都能通过代码了解“电子签是如何工作的”,真正实现“技术自主可控”。 合规可信:符合国标与国际规范,签署具备法律效力 企业版严格遵循《信息安全技术—安全电子签章密码技术规范》(GB/T 38540-2020)等国密标准,采用SM2国密算法(非对称加密,安全性高于国...