大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
前两篇我们探讨了搜索技术的基石 Apache Lucene 和企业级搜索解决方案 Apache Solr。今天,我们来聊聊一个真正改变搜索游戏规则,但也充满争议的产品 — Elasticsearch。
![]()
引言
如果说 Lucene 是幕后英雄,那么 Elasticsearch 就是舞台中央的明星。借助 REST API、分布式架构、强大的生态系统,它让搜索 + 分析成为“马上可用”的服务形式。
在日志平台、可观察性、安全监控、AI 与语义检索等领域,Elasticsearch 的名字几乎成了默认选项。
Elasticsearch 概述
Elasticsearch 是一个开源的分布式搜索和分析引擎,构建于 Apache Lucene 之上。作为一个检索平台,它可以实时存储结构化、非结构化和向量数据,提供快速的混合和向量搜索,支持可观测性与安全分析,并以高性能、高准确性和高相关性实现 AI 驱动的应用。
起源:从食谱搜索到全球“流量明星”
Elasticsearch 的故事始于以色列开发者 Shay Banon。2010 年,当时他在学习厨师课程的妻子需要一款能够快速搜索食谱的工具。虽然当时已经有 Solr 这样的搜索解决方案,但 Shay 认为它们对于分布式场景的支持不够完善。
![]()
基于之前开发 Compass(一个基于 Lucene 的搜索库)的经验,Shay 开始构建一个完全分布式的、基于 JSON 的搜索引擎。2010 年 2 月,Elasticsearch 的第一个版本发布。
随着用户日益增多、企业级需求增强,Shay 在 2012 年创立了 Elastic 公司,把 Elasticsearch 不仅作为开源项目,也逐渐商业化运营起来,包括提供托管服务、企业支持,加入 Logstash 日志处理、Kibana 可视化工具等,Elastic 公司也逐渐从一个纯搜索引擎项目演变为一个更广泛的“数据搜索与分析”平台。
协议变更:开源和商业化的博弈
Elasticsearch 的发展并非一帆风顺。其历史上最具转折性的事件当属与 AWS 的冲突及随之而来的开源协议变更。
![]()
- 早期:Apache 2.0 协议
2010 年 Shay Banon 开源 Elasticsearch 时,最初采用的是 Apache 2.0 协议。Apache 2.0 属于宽松的自由协议,允许任何人免费使用、修改和商用(包括 SaaS 模式)。这帮助 Elasticsearch 快速壮大,成为事实上的“搜索引擎标准”。
- 协议变更:应对云厂商“白嫖”
随着 Elasticsearch 的流行,像 AWS(Amazon Web Services) 等云厂商直接将 Elasticsearch 做成托管服务,并从中获利。Elastic 公司认为这损害了他们的商业利益,因为云厂商“用开源赚钱,却没有回馈社区”。2021 年 1 月,Elastic 宣布 Elasticsearch 和 Kibana 不再采用 Apache 2.0,改为 双重协议:SSPL + Elastic License。这一步导致社区巨大分裂,AWS 带头将 Elasticsearch 分叉为 OpenSearch,并继续以 Apache 2.0 协议维护。
- 再次转向开源:AGPL v3
2024 年 3 月,Elastic 宣布新的版本(Elasticsearch 8.13 起)又新增 AGPL v3 作为一个开源许可选项。AGPL v3 既符合 OSI 真正开源标准,又能约束云厂商闭源托管服务,同时修复社区关系,Elastic 希望通过重新拥抱开源,减少分裂,吸引开发者回归。
Elasticsearch 从宽松到收紧,再到回归开源,是在社区生态与商业利益间寻找平衡的过程。
基本概念
要学习 Elasticsearch,得先了解其五大基本概览:集群、节点、分片、索引和文档。
- 集群(Cluster)
由一个或多个节点组成的整体,提供统一的搜索与存储服务。对外看起来像一个单一系统。
- 节点(Node)
集群中的一台服务器实例。节点有不同角色:
- Master 节点:负责集群管理(分片分配、元数据维护)。
- Data 节点:存储数据、处理搜索和聚合。
- Coordinating 节点:接收请求并调度任务。
- Ingest 节点:负责数据写入前的预处理。
- 索引(Index)
类似于传统数据库的“库”,按逻辑组织数据。一个索引往往对应一个业务场景(如日志、商品信息)。
- 分片(Shard)
为了让索引能水平扩展,Elasticsearch 会把索引拆分为多个 主分片,并为每个主分片创建 副本分片,提升高可用和查询性能。
- 文档(Document)
Elasticsearch 存储和检索的最小数据单元,通常是 JSON 格式。多个文档组成一个索引。
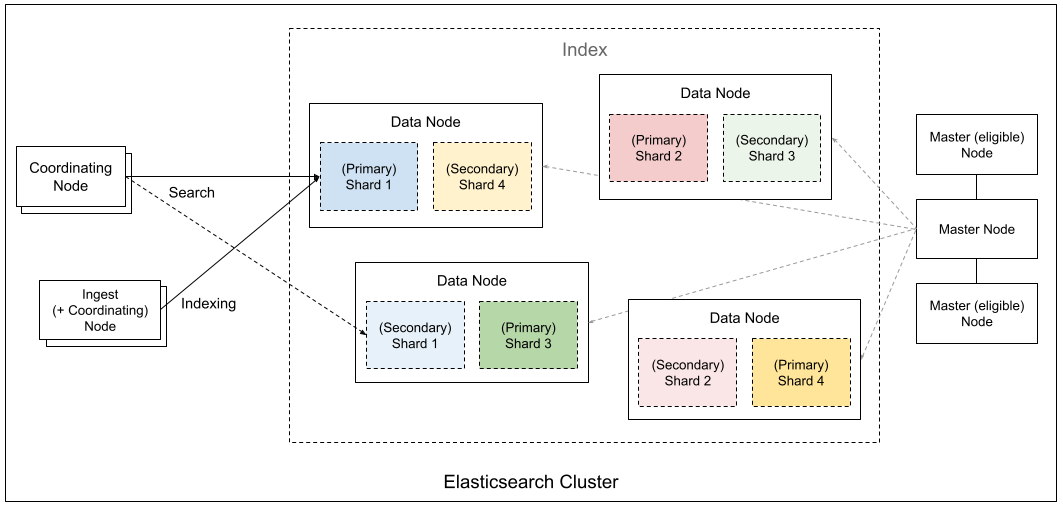
集群架构
![]()
Elasticsearch 通过 Master、Data、Coordinating、Ingest 等不同角色节点的协作,将数据切分成分片并分布式存储,实现了高可用、可扩展的搜索与分析引擎架构。
快速开始:5 分钟体验 Elasticsearch
1. 使用 Docker 启动
# 拉取最新镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:9.1.3
# 启动单节点集群
docker run -d --name elasticsearch \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e "xpack.security.enabled=false" \
docker.elastic.co/elasticsearch/elasticsearch:9.1.3
2. 验证安装
# 检查集群状态
curl -X GET "http://localhost:9200/"
![]()
3. 索引文档
# 索引文档
curl -X POST "http://localhost:9200/myindex/_doc" -H 'Content-Type: application/json' -d'
{
"title": "Hello Elasticsearch",
"description": "An example document"
}'
![]()
3. 搜索文档
# 搜索文档
curl -X GET "http://localhost:9200/myindex/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"title": "Hello"
}
}
}'
![]()
结语
Elasticsearch 是搜索与分析领域标杆性的产品。它将 Lucene 的能力包装起来,加上分布式、易用以及与数据可视化、安全监控等功能的整合,使搜索引擎从专业技术逐渐变为“随手可用”的基础设施。
虽然协议变动、与 OpenSearch 的分叉引发争议,但它在企业与开发者群体中的实际应用价值依然难以替代。
🚀 下期预告
下一篇我们将介绍 OpenSearch,探讨这个 Elasticsearch 分支项目的发展现状、技术特点以及与 Elasticsearch 的详细对比。如果您有特别关注的问题,欢迎提前提出!
💬 三连互动
- 你或公司最近在用 Elasticsearch 吗?拿来做了什么场景?
- 在 Elasticsearch 和 OpenSearch 之间做过技术选型?
- 对 Elasticsearch 的许可证变化有什么看法?
对搜索技术感兴趣的朋友,欢迎关注《搜索百科》专栏,一起探讨与学习!
✨ 推荐阅读
🔗 参考