作者:来自 Elastic James Baiera 及 Graham Hudgins
了解失败存储,这是 Elastic Stack 的一项新功能,用于捕获和索引之前丢失的事件。
想获得 Elastic 认证吗?看看下一期 Elasticsearch Engineer 培训什么时候开始!
Elasticsearch 拥有丰富的新功能,帮助你为自己的用例构建最佳搜索解决方案。深入学习我们的示例笔记本,开始免费的云试用,或立即在本地运行 Elastic。
如果一棵树在森林里倒下,而周围没有人,它会发出声音吗?答案是会的。就像一条日志消息被发出但未能处理进你的可观测性平台时,这条日志确实发生了 —— 而且如果它很重要,你几乎肯定最终会听说它。
Elastic 能够适应系统发出的各种数据:日志、指标、跟踪、自定义遥测等。但当这些数据因为模式变化、代理配置错误或某个异常服务发出意外字段而不符合预期格式时,它可能无法处理,并会悄无声息地消失。
这种缺失本身就是一种信号。但它很难被检测、很难调试、也很难报告。更糟的是,它把问题甩给了客户端去查明原因。
这就是我们构建 失败存储 的原因:一种全新的方式,可以直接在 Elastic Stack 中捕获、调试和分析失败的事件。在这篇博客中,我们将介绍 Elastic 的失败存储,并解释它如何提供数据摄取问题的可见性、帮助调试模式变化、让团队能够监控数据质量并精准定位失败模式。
关于失败存储
失败存储让你能够看到以前只有发送数据的客户端和死信队列才能看到的失败事件。它通过将失败的文档捕获并索引到专用的::failures索引中来工作,这些索引与生产数据一起存在于你的数据流中。你可以按数据流启用它,也可以通过一个集群设置在多个数据流中启用。
重要性
团队通常处于真实数据源的下游。他们不写代码,只是维持系统运行。当上游团队发布的更改破坏了映射或引入了意外字段时,就会发生失败。但如果无法访问原始的失败数据,调试就只能靠猜。
更糟的是,当数据无法被索引时,它就不存在于你的索引中 —— 这意味着更难评估影响。你无法追踪哪个数据流失败最频繁,也无法量化管道损坏的程度。如果平台从未接收到这些数据,你当然无法对缺失内容发出告警(除了当数据缺失时的告警)。
故障存储使开发人员能够了解哪些数据索引失败以及失败原因,从而为可观测性工程师提供快速了解和修复数据提取故障所需的工具。由于故障存储在 Elasticsearch 中,因此分类也非常迅速,无需从远程客户端或数据采集器收集信息。
开始使用
为新的数据流进行设置…
PUT _index_template/my-index-template
{
"index_patterns": ["my-datastream-*"],
"data_stream": { },
"template": {
"data_stream_options": {
"failure_store": { // ✨
"enabled": true
}
}
}
}
…或为现有数据流启用
在 Kibana 的 Stack 管理中为单个数据流启用失败存储,或使用 _data_stream API:
PUT _data_stream/my-existing-datastream/_options
{
"failure_store": {
"enabled": true
}
}
通过集群设置启用失败存储
如果你有大量现有数据流,可能希望在一个地方统一启用它们的失败存储。无需单独更新每个数据流的选项,只需在集群设置中将 data_streams.failure_store.enabled 设置为索引模式列表。任何匹配这些模式的数据流都将启用失败存储。
PUT _cluster/settings
{
"persistent" : {
"data_streams.failure_store.enabled" : [ "my-datastream-*", "logs-*" ]
}
}
失败文档响应
启用失败存储后,以前会失败的请求现在会有不同的处理方式。客户端现在会收到 201 Created,而不是 400 Bad Request。特别是如果你使用自定义应用或我们的语言客户端,请确保相应更新代码。当文档进入失败存储时,响应中会包含failure_store: used属性。
{
"_index": ".fs-logs-generic.otel-default-2025.07.31-000010",
"_id": "2K9IYpgBfukt97YIaUPG",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1,
"failure_store": "used"
}
像处理其他日志一样搜索和筛选失败数据,支持 ES|QL 和 Kibana 工具:
FROM logs-generic.otel-default::failures
失败存储中的数据包含所有上下文信息,使调试更简单。每个 ::failures 索引都包含管道失败的信息,以及具体的错误消息、堆栈跟踪和错误类型,帮助你识别模式。
如果你遇到大量错误,不知道从哪里开始,可以使用 ES|QL 和 ML 功能。通过 ES|QL 暴露的数据,可以利用 ML 功能(如CATEGORIZE)分析错误,帮助解析错误并提取模式。在我们的文档中可以阅读更多关于数据修复的技术。
使用你已经用于其他数据的数据流生命周期来控制成本和保留时间。如果没有自定义保留策略,失败存储数据将保留 30 天。
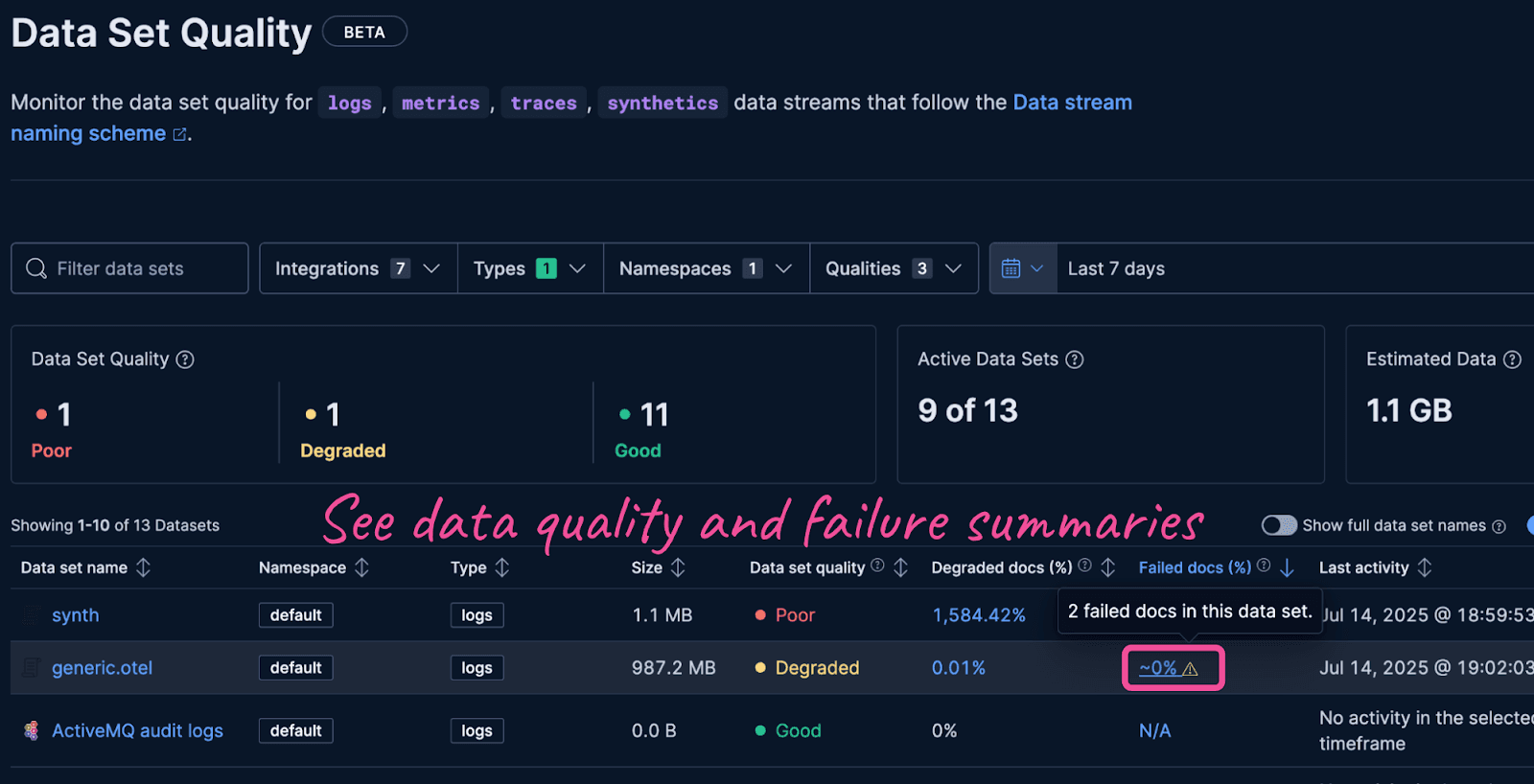
通过失败指标和按失败百分比可排序的仪表板随时间监控数据质量,发现需要调查的新问题区域。在文档中可以阅读更多关于数据质量监控的内容。
了解更多
失败存储从 Elastic 9.1 和 8.19 开始可用,并将在即将发布的版本中默认在 logs-*-* 索引上启用。想了解更多,请查阅文档获取设置说明和最佳实践。
原文:Failure store: see what didn’t make it - Elasticsearch Labs