背景
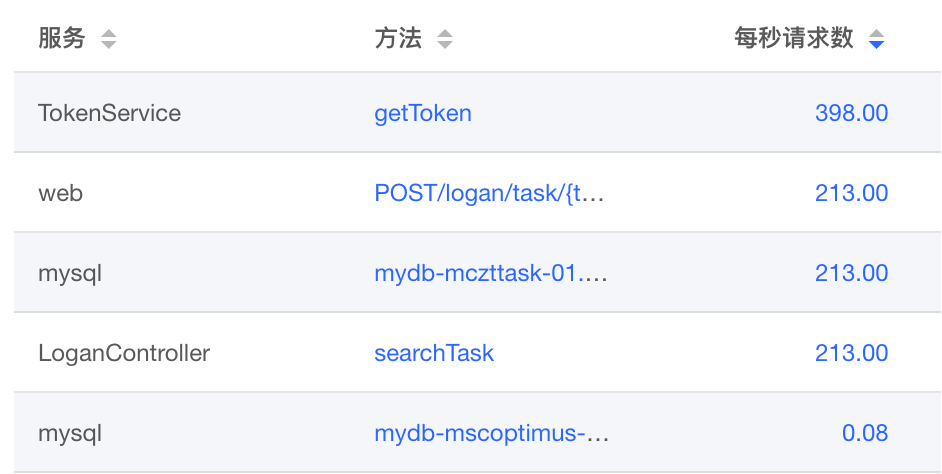
线上应用频繁出现超时告警(超时时间 1 s): getUiToken 接口异常状态码“-1”出现4037次(失败描述:业务请求异常),超过阈值50,协议:http,为服务端接口。当前失败率为0%,当前平均响应时间为150ms,TP50为2ms,TP90为896ms,TP99为1024ms,TP999为1152ms,MAX为1280ms。
环境信息
• 服务器配置为,Linux 4c8g 标配机器
• JVM 参数配置:
-server -Djava.library.path=/usr/local/lib -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/export/log -Djava.awt.headless=true -Dsun.net.client.defaultConnectTimeout=60000 -Dsun.net.client.defaultReadTimeout=60000 -Djmagick.systemclassloader=no -Dnetworkaddress.cache.ttl=300 -Dsun.net.inetaddr.ttl=300 -Xms5G -Xmx5G -XX:+UseG1GC -XX:G1HeapRegionSize=4m -Xloggc:/export/log/$APP_NAME/gc_detail.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=10m -XX:MaxTenuringThreshold=15 -XX:+PrintTenuringDistribution -XX:+PrintHeapAtGC
• 接口流量情况:
问题排查
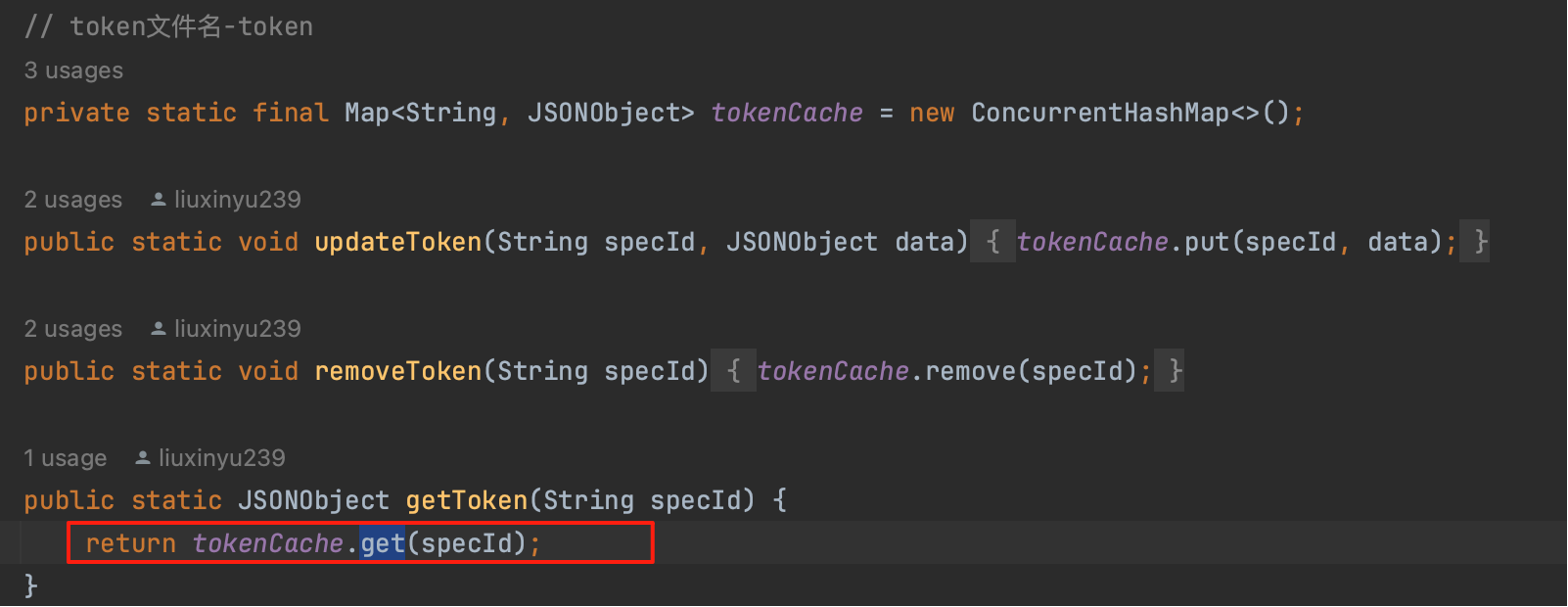
分析代码实现,getUiToken 只是简单的内存数据获取并返回,没有其他复杂操作,不存在有耗时操作
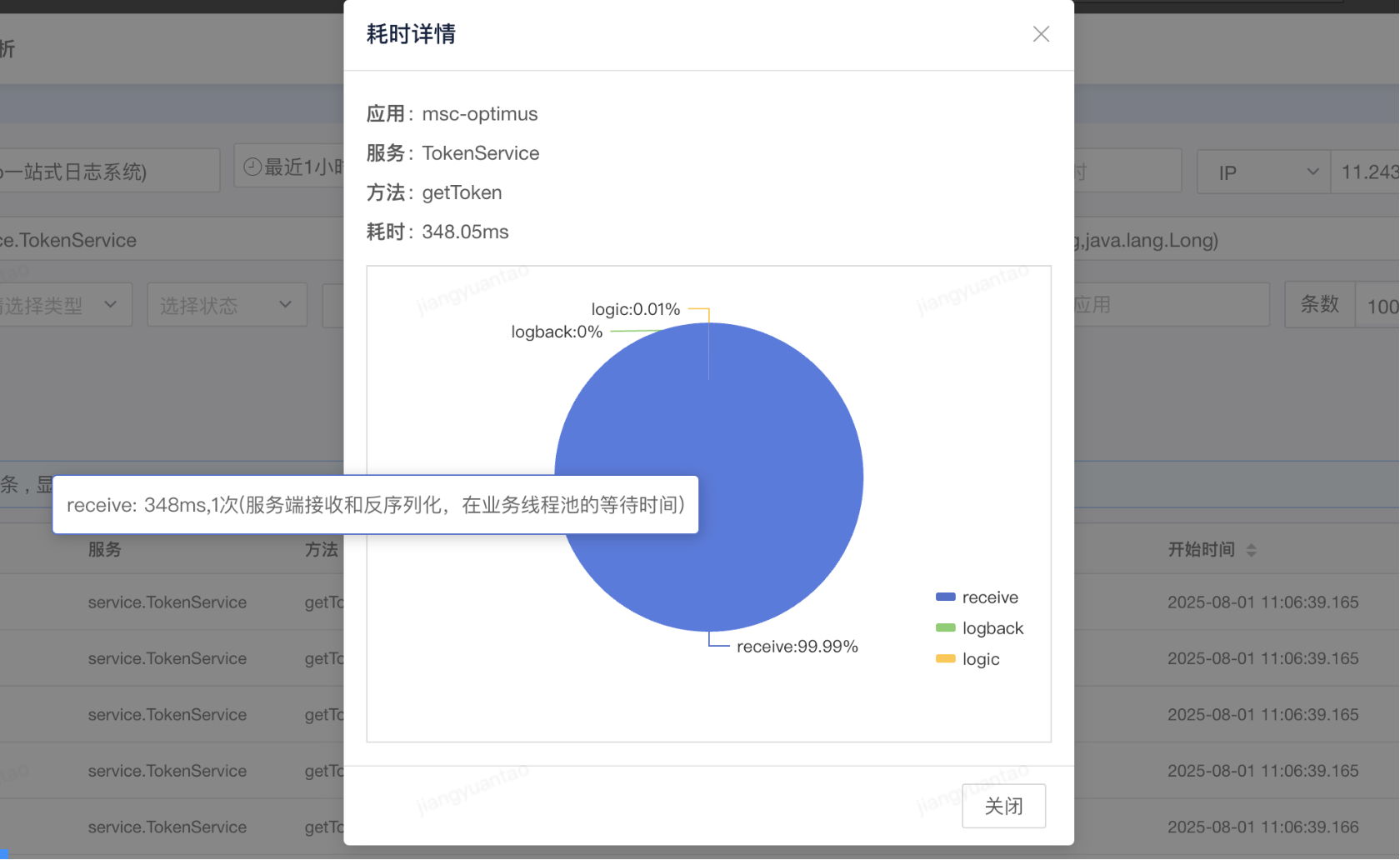
接着借助 SGM 监控平台分析下接口耗时情况,发现方法执行的耗时都处在等待中,为什么会有这多长的等待时间呢?
业务代码很简单,只是内存级别的获取,序列化和反序列化也不可能耗时这么久, 难道是 GC 的原因 ? 因为 JVM 之前就配置了 -Xloggc 日志输出,所以先分析下 GC 日志情况,看看 GC 是否存在异常情况(工具 gcViewer)
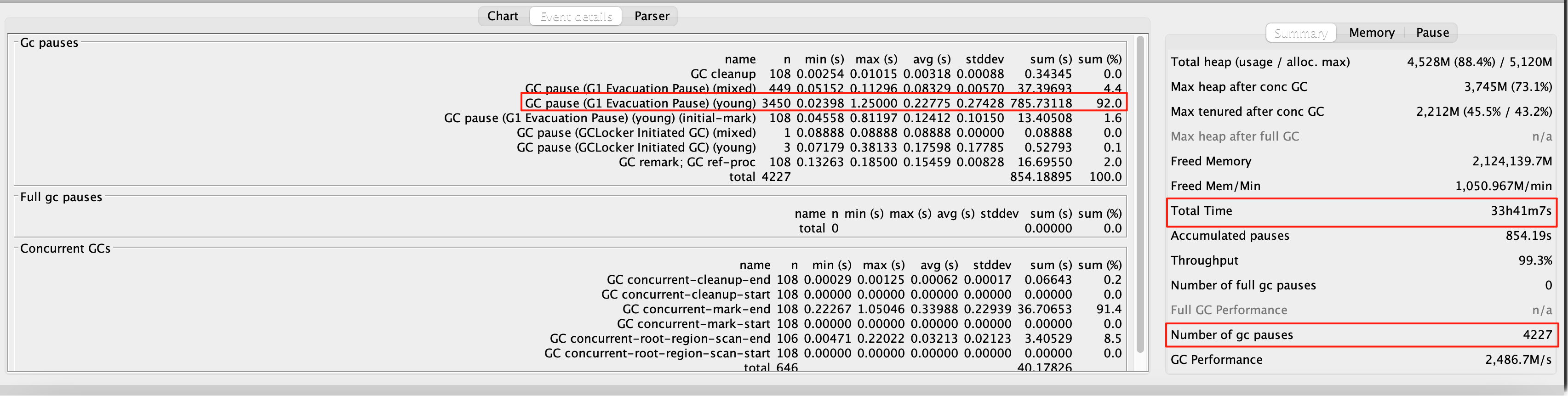
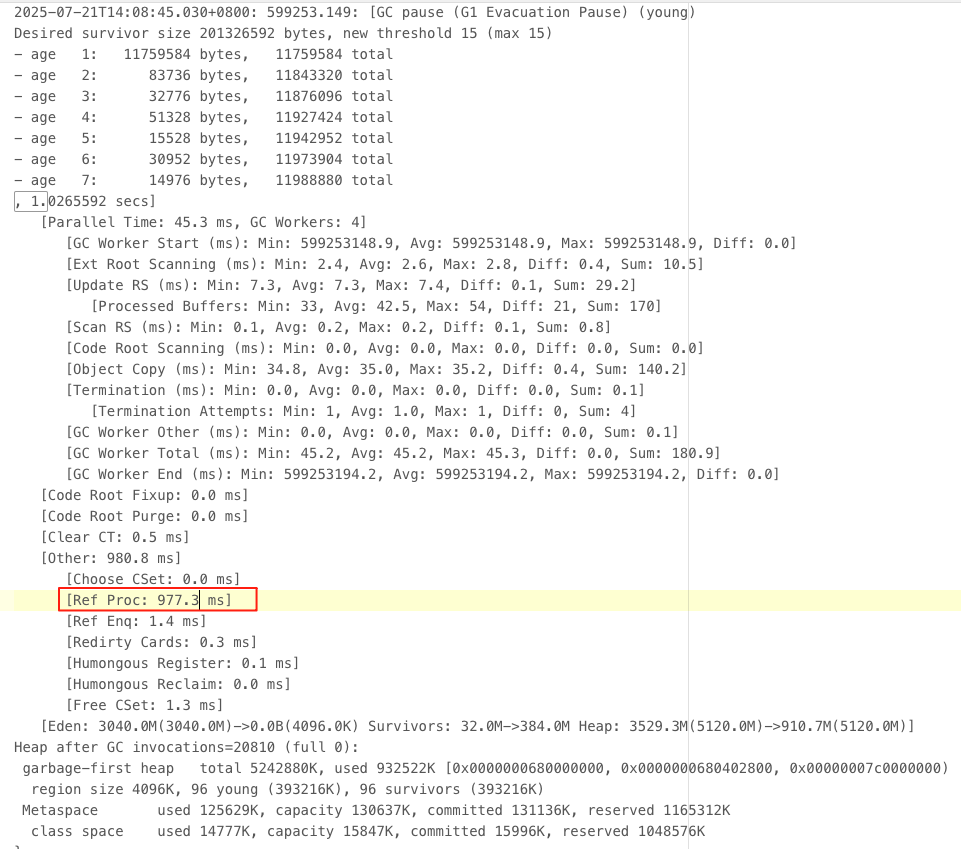
果然,光看吞吐量 99.3% 和 full gc 次数 0,感觉性能好像还不错的,但 4227 次 young gc (平均 20 多秒一次) 和 max 1.25 秒的耗时,就有点离谱,分析 GC 日志详情
随机搜查了一个 GC 耗时在 1s 以上的日志,发现 1.02 s 的 gc 有 977.3 ms 是在处理 Ref Proc,为什么这个耗时会这么长 ?
ref-proc 是对各种软弱虚引用等的处理,处理 soft、weak、phantom、final、JNI 等等引用的时间
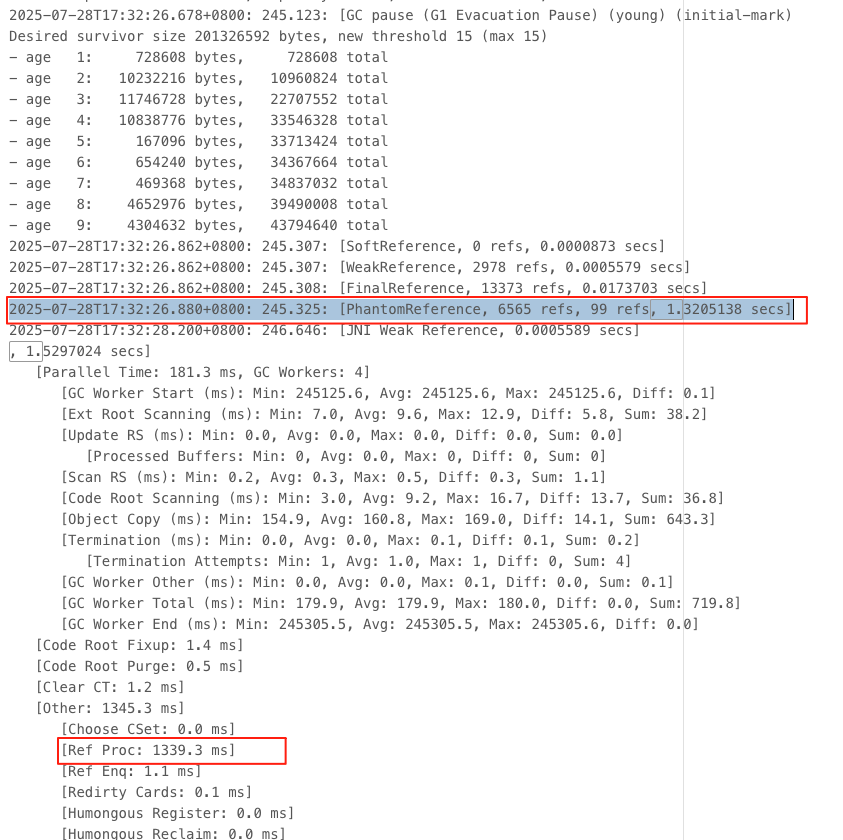
具体是那种引用类型的耗时长,可以通过增加 JVM 参数 -XX:+PrintReferenceGC 打印引用GC类型 ,重新上线一段时间后观察GC日志
发现耗时基本都在 PhantomReference 类型的对象上,为什么会有这么多这个对象?
PhantomReference 是什么? 1、虚引用也称为“幽灵引用”,它是最弱的一种引用关系。 2、如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。 3、为一个对象设置虚引用关联的唯一目的只是为了能在这个对象被收集器回收时收到一个系统通知。 4、当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在垃圾回收后,将这个虚引用加入引用队列,在其关联的虚引用出队前,不会彻底销毁该对象。所以可以通过检查引用队列中是否有相应的虚引用来判断对象是否已经被回收了。
为了搞清楚 PhantomReference 具体都是哪些对象,我们需要 dump 堆文件查看对象的分布(内存分析工具 MAT),dump 时最好将流量摘除后操作,以免影响线上。查看直方图中的对象发现有 4340 个虚引用对象,和GC日志中的数量基本对的上。
那为什么会有这么多 ConnectionPhantomReference 对象呢 ? 这个东西有什么用呢 ? 源码如下 (mysql-connector-java 版本 5.1.44)
// 相关的核心逻辑
public class NonRegisteringDriver implements java.sql.Driver {
protected static final ConcurrentHashMap<ConnectionPhantomReference, ConnectionPhantomReference> connectionPhantomRefs = new ConcurrentHashMap<ConnectionPhantomReference, ConnectionPhantomReference>();
protected static final ReferenceQueue<ConnectionImpl> refQueue = new ReferenceQueue<ConnectionImpl>();
protected static void trackConnection(Connection newConn) {
ConnectionPhantomReference phantomRef = new ConnectionPhantomReference((ConnectionImpl) newConn, refQueue);
connectionPhantomRefs.put(phantomRef, phantomRef);
}
}
public class ConnectionImpl extends ConnectionPropertiesImpl implements MySQLConnection {
public ConnectionImpl(String hostToConnectTo, int portToConnectTo, Properties info, String databaseToConnectTo, String url) throws SQLException {
...
NonRegisteringDriver.trackConnection(this);
}
}
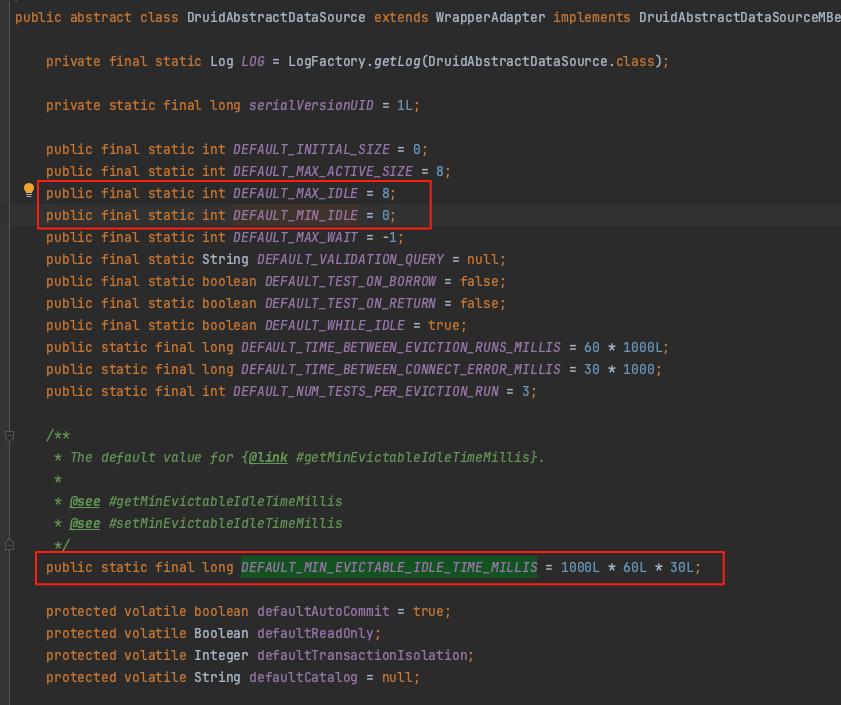
通过代码发现,每次新建数据库连接 Connection 时都会向 connectionPhantomRefs 存放一个对象,那么已经使用 druid (版本:1.0.15)线程池为什么还会生成这么多新链接 ? 接着查看项目中的数据库配置,发现数据源使用的是默认配置
# 线程池使用的默认配置
spring:
datasource:
url: jdbc:mysql://xxxxxxxxx?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&serverTimezone=GMT%2B8
username: xxxx
password: xxxx
driver-class-name: com.mysql.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
默认配置中,线程池中的连接存活时间为 30 分钟,最小闲置线程数为 0,因此虽使用了线程池也还是会不断的创建新的链接,并增加到 connectionPhantomRefs 集合中,累计一定量之后就会影响 ref-proc 耗时。
如何解决 ?
既然因为它累计的量大导致 gc 时长变高,那么我们分析下 connectionPhantomRefs 的作用到底是什么 ?
跟进 connectionPhantomRefs 引用处理对象,发现 connectionPhantomRefs 中的元素都是被 AbandonedConnectionCleanupThread 处理的
/**
* This class implements a thread that is responsible for closing abandoned MySQL connections,
* i.e., connections that are not explicitly closed.
* There is only one instance of this class and there is a single thread to do this task.
* This thread's executor is statically referenced in this same class.
*
* 该类实现了一个负责关闭被遗弃的MySQL连接的线程,即未显式关闭的连接。该类的实例只有一个,并且由单个线程执行此任务。该线程的执行器在此类中以静态方式引用。
*/
public class AbandonedConnectionCleanupThread implements Runnable {
private static final ExecutorService cleanupThreadExcecutorService;
static Thread threadRef = null;
static {
cleanupThreadExcecutorService = Executors.newSingleThreadExecutor(new ThreadFactory() {
public Thread newThread(Runnable r) {
Thread t = new Thread(r, "Abandoned connection cleanup thread");
t.setDaemon(true);
t.setContextClassLoader(AbandonedConnectionCleanupThread.class.getClassLoader());
return threadRef = t;
}
});
cleanupThreadExcecutorService.execute(new AbandonedConnectionCleanupThread());
}
public void run() {
for (;;) {
try {
checkContextClassLoaders();
Reference<? extends ConnectionImpl> ref = NonRegisteringDriver.refQueue.remove(5000);
if (ref != null) {
try {
((ConnectionPhantomReference) ref).cleanup();
} finally {
NonRegisteringDriver.connectionPhantomRefs.remove(ref);
}
}
} catch (InterruptedException e) {
threadRef = null;
return;
} catch (Exception ex) {
// Nowhere to really log this.
}
}
}
}
根据 com.mysql.jdbc.AbandonedConnectionCleanupThread 类注释信息,发现该类是 mysql 连接的兜底处理逻辑,负责关闭被遗弃的MySQL连接,主要有两种情况
1. 未显式关闭的连接(代码遗漏)
2. 异常未处理的连接(程序崩溃/未捕获异常/网络或事务超时导致的连接失效)
解决方案
1. 优化 druid 连接池连接数配置 (按实际流量情况评估),增加连接存活时长到 59 分钟(MySql wait_timeout 默认为 3600 秒),最大限度减少新连接生成
spring:
datasource:
url: jdbc:mysql://xxxxxxxxx?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&serverTimezone=GMT%2B8
username: xxxx
password: xxxx
driver-class-name: com.mysql.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
druid:
# 增加线程数
minIdle: 4
maxActive: 10
initialSize: 4
# 启动检测线程回收
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
validationQuery: select 1
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 3540000
2. 开启 ref-proc 并行处理:-XX:+ParallelRefProcEnabled , G1 官网建议
Reference Object Processing Takes Too Long Information about the time taken for processing of Reference Objects is shown in the Ref Proc and Ref Enq phases. During the Ref Proc phase, G1 updates the referents of Reference Objects according to the requirements of their particular type. In Ref Enq, G1 enqueues Reference Objects into their respective reference queue if their referents were found dead. If these phases take too long, then consider enabling parallelization of these phases by using the option -XX:+ParallelRefProcEnabled.
3. 由于 connectionPhantomRefs 只是作为异常情况出现的兜底处理,我们项目中使用的线程池都会自动处理资源释放的情况,不存在手动操作的情况,是不是可以定时清理这部分的内容或者不使用,目前使用最多的两种方式是
• 定时任务:清理虚引用列表数据
@Component
public class CleanPhantomRefsSchedule {
private static final ScheduledExecutorService CLEANER_EXECUTOR = Executors.newSingleThreadScheduledExecutor(r -> {
Thread t = new Thread(r, "mysql-phantom-ref-cleaner");
t.setDaemon(true);
return t;
});
@PostConstruct
public void doTask() {
log.info("CleanPhantomRefsSchedule#doTask start");
try {
Field field = NonRegisteringDriver.class.getDeclaredField("connectionPhantomRefs");
field.setAccessible(true);
// 定时轮训
CLEANER_EXECUTOR.scheduleAtFixedRate(() -> {
try {
Map<?, ?> connectionPhantomRefs = (Map<?, ?>) field.get(null);
// 这里我设置的稍微大一些,对 gc 没太大影响时不进行干预
if (connectionPhantomRefs != null && connectionPhantomRefs.size() > 500) {
connectionPhantomRefs.clear();
log.info("Cleared MySQL phantom references (count={})", connectionPhantomRefs.size());
}
} catch (Exception e) {
log.error("connectionPhantomRefs clear error!", e);
}
}, 1, 1, TimeUnit.HOURS);
} catch (NoSuchFieldException e) {
throw new IllegalStateException("Failed to initialize MySQL phantom refs field", e);
}
}
@PreDestroy
void shutdown() {
CLEANER_EXECUTOR.shutdownNow();
}
}
• 升级 mysql-connector-java 版本(8.0 以上),可以通过参数 -Dcom.mysql.cj.disableAbandonedConnectionCleanup=true 禁用虚引用生成
private static boolean abandonedConnectionCleanupDisabled = Boolean.getBoolean("com.mysql.cj.disableAbandonedConnectionCleanup");
protected static void trackConnection(MysqlConnection conn, NetworkResources io) {
if (!abandonedConnectionCleanupDisabled) {
···
ConnectionFinalizerPhantomReference reference = new ConnectionFinalizerPhantomReference(conn, io, referenceQueue);
connectionFinalizerPhantomRefs.add(reference);
···
}
}
我采用的是定时任务这种方式,因为项目升级 mysql-connector-java 版本会存在兼容性问题,其次是在虚引用量比较小的情况我希望这种兜底策略依旧可以生效,所以定时任务中只有在 connectionPhantomRefs.size() > 500 时才会干预清理,而不是直接杜绝使用
验证优化结果
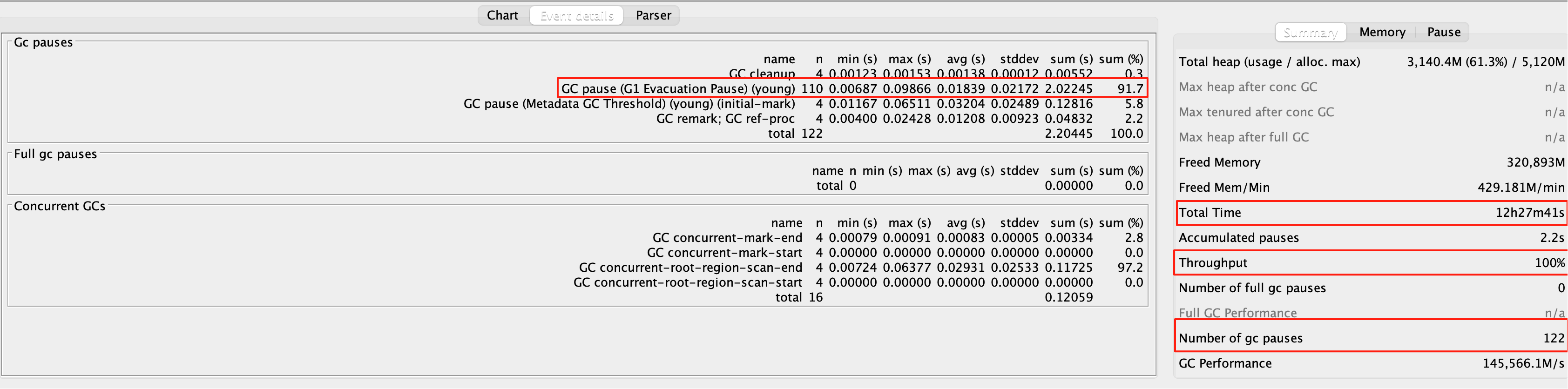
代码及配置调整完成后再次上线,等待一天后,继续分析 GC日志和堆转储文件
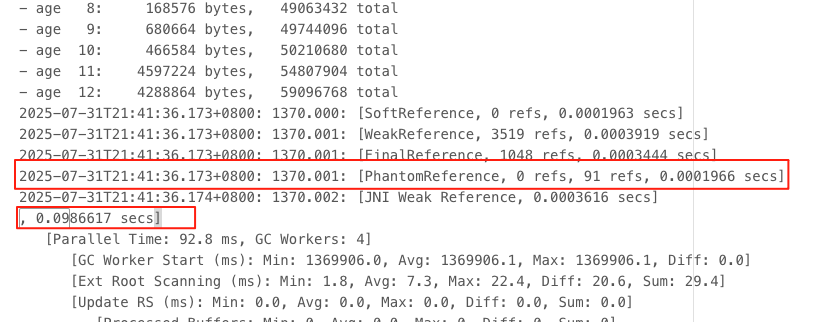
结论:上线后近 12 小时数据,GC 时间最大停顿时间由原先 1.25 降低至 0.1 秒,young gc 频率由原先的 20 秒一次优化到 6 分钟一次,PhantomReference 引用耗时缩减到 0.0001966 s, 持续观察几天,线上服务无超时告警且系统响应正常,优化符合预期结果。