技术背景
自动驾驶领域对高效且实时的数据处理能力提出了极高要求。如何优化深度学习模型的训练与推理流程,提升计算资源利用率,缩短模型迭代周期,并在保证精度的同时,实现低延迟、高吞吐量的部署,始终是行业面临的核心挑战。针对这些难题,PAI-TurboX为自动驾驶场景中的复杂数据预处理、离线大规模模型训练和实时智能驾驶推理,提供了全方位的加速解决方案。这些方案不仅显著提升了感知、规划、控制等多模块系统的训练与推理效率,还有效加速端到端和世界模型的开发进程,助力自动驾驶技术不断迈向更高水平。 ![]()
自动驾驶系统结构示例图(Autonomous Driving Small-Scale Cars: A Survey of Recent Development,https://arxiv.org/pdf/2404.06229)
自动驾驶面临的两大难题
核心技术亮点
![]() PAI-TurboX从系统、数据、模型三个方面针对自动驾驶面临的两大难题进行优化。
PAI-TurboX从系统、数据、模型三个方面针对自动驾驶面临的两大难题进行优化。
在系统侧,TurboX通过优化CPU亲和性、优化垃圾回收机制、动态编译、流水线并行和操作系统优化等方案,提升模型训练推理效率。
-
系统级性能调优,深度集成CPU Affinity亲和性优化方案,精准控制进程与 CPU 核绑定,减少上下文切换开销;优化Python垃圾回收机制,重构垃圾回收管理策略,降低 GC 频率与延迟抖动;以及HugePage 内存加速技术,结合 HugePage 提升内存访问效率,显著降低 I/O 延迟,全面提升训练与推理任务的稳定性与吞吐能力。
-
支持模型动态编译技术,实时优化计算图结构,按需高效执行代码,显著提升模型的训练和推理速度与硬件利用率,实现性能与灵活性的双重突破。
-
流水线并行执行 ,在训练和推理过程中,高性能的GPU训练推理计算前后,往往伴随着密集的CPU算子计算,将CPU计算和GPU计算流水并行调度执行,能够大幅减少GPU等待时间,提升整个计算Job的吞吐。 ![]()
-
操作系统(OS)优化:针对智驾场景下系统运行的特点,使用阿里云操作系统团队提供的高效动态内存管理、系统运行参数自适应调优、系统资源防争抢等优化能力,保障智驾相关模型训练和推理的运行效率。
-
高效动态内存管理:通过自研的内核内存特性,降低系统动态内存管理所占用的CPU计算资源,解决大规模数据处理所引发的系统内存碎片化,从而提升模型训练、推理整体吞吐和稳定性。
-
系统参数自动调优:提供自动系统参数调优工具keentune,可以自动匹配出最适合模型训练的系统优化参数并完成自动设置,在用户无感的情况下自动提升模型训练效率。
-
系统资源防争抢:细粒度的系统资源监控与隔离能力,自动为高优先级的模型训练任务预留计算、存储、带宽等资源,缓解训练数据的在线处理对训练吞吐负面影响。
在数据侧,PAI-TurboX提出了高性能的DataLoader引擎、优化了数据预处理流程和实现了智能训练样本分组,有效提升了数据处理效率。
-
高性能DataLoader引擎:通过循环加载数据,避免训练时等待数据,利用锁页内存,加快数据从CPU到GPU的传输效率,实现训练的快速启动。
-
深度重构预处理流程:涵盖智能调整大小、精准裁剪等核心环节,构建高效统一的数据增强与加载流水线,显著降低预处理延迟,提升数据吞吐能力。
-
智能训练样本分组:采用智能分组采样引擎,精准聚合同类样本,突破传统随机采样的局限,并减少分组的多次拷贝,实现按类别或特征对样本进行精准聚合,实现高性能训练。
在模型侧,PAI-TurboX从算子、Module、优化器、优化策略、量化、CPU和GPU设备的自动切换等多个角度显著提升模型训练与推理的速度。
-
高性能算子优化:针对常见的自动驾驶感知任务中的核心算子进行了深度优化,实现了高效体素化cuda kernel,提升point cloud体素化的效率;通过shared memory优化nms kernel和deformable kernel的执行效率;通过CUDA重写并融合重复逻辑,去除冗余操作来优化稀疏卷积算子、矩阵求逆运算、坐标变换小矩阵乘法等常见的自动驾驶算子,显著减少访存延迟,大幅提升训练吞吐;
-
高性能Module优化:在多卡分布式训练中,批归一化层BatchNorm需要做同步处理SyncBN,去除了冗余的GPU->CPU同步,提升了自动驾驶场景BN同步阶段的执行效率。
-
Workload设备重映射: 将模型训练过程中适合CPU计算的部分迁移到dataloader部分预先计算,将计算密集型的数据处理迁移到gpu上计算,以降低cpu处理的压力、提升gpu的执行效率。
-
为提升模型推理效率:采用INT8量化、BF16/TF32半精度计算及自动混合精度(AMP)策略,结合硬件特性对算子进行细粒度精度优化,在保障精度的前提下显著降低计算开销与内存带宽需求,实现异构平台下的高性能推理部署。
-
优化器融合:通过融合优化器技术将动量更新、权重衰减与梯度下降操作合并为单一内核执行,降低了GPU内存访问压力并提升了整体训练性能。
-
训练策略优化:使用CudaGraph来优化多个kernel启动,比如将EMA 的更新逻辑整合进 CudaGraph 中,减少 Python 层对模型参数的逐层访问与更新。
实测性能速度提升
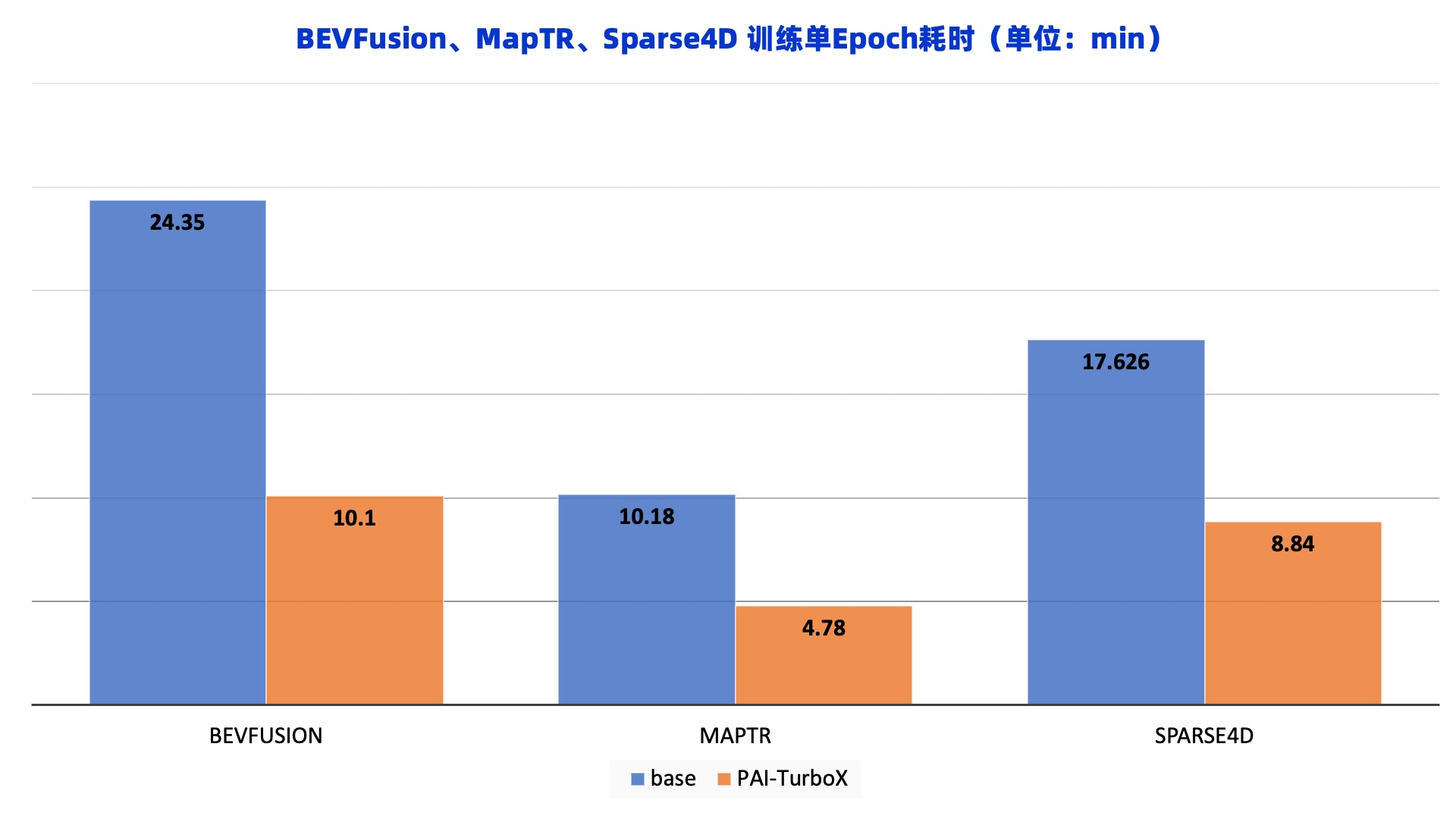
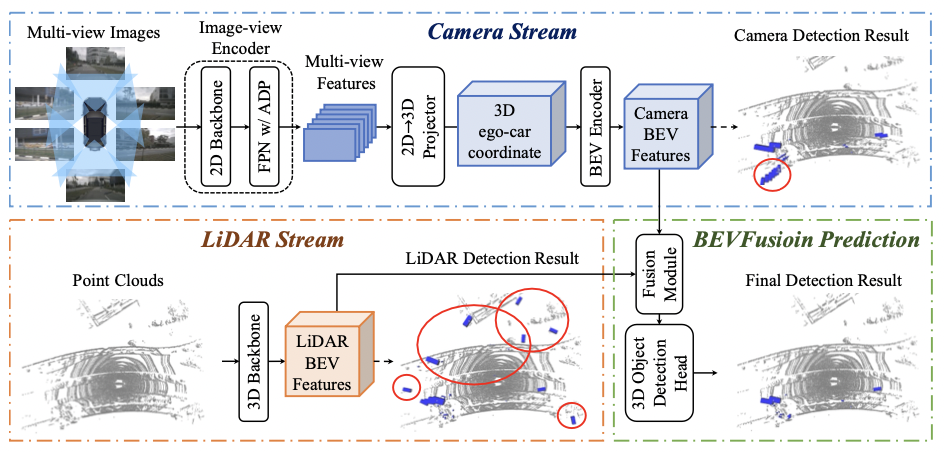
PAI-TurboX支持大量自动驾驶模型优化,如BEVFusion、BEVFormer、GameFormer、MTR、MapTR、MapQR、Open-Clip、Sparse4D、SparseDrive和OpenVLA等模型。 ![]() BEVFusion流程图(BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework)
BEVFusion流程图(BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework)
下面的图像展示了在PAI-TurboX在自动驾驶各类模型上都有着充分的速度提升。BEVFusion模型主要是融合激光雷达点云和图像特征,产生一个多模态的BEV特征,以支持各种3D感知任务,应用PAI-TurboX可以将训练时间缩短58.5%。MapTR一个结构化的端到端框架,用于高效的在线矢量高清地图构建,应用PAI-TurboX可以将训练时间缩短53.0%。Sparse4D是一个高性能高效率的长时序纯稀疏融合感知算法,应用PAI-TurboX可以将训练时间缩短49.8%。 ![]()
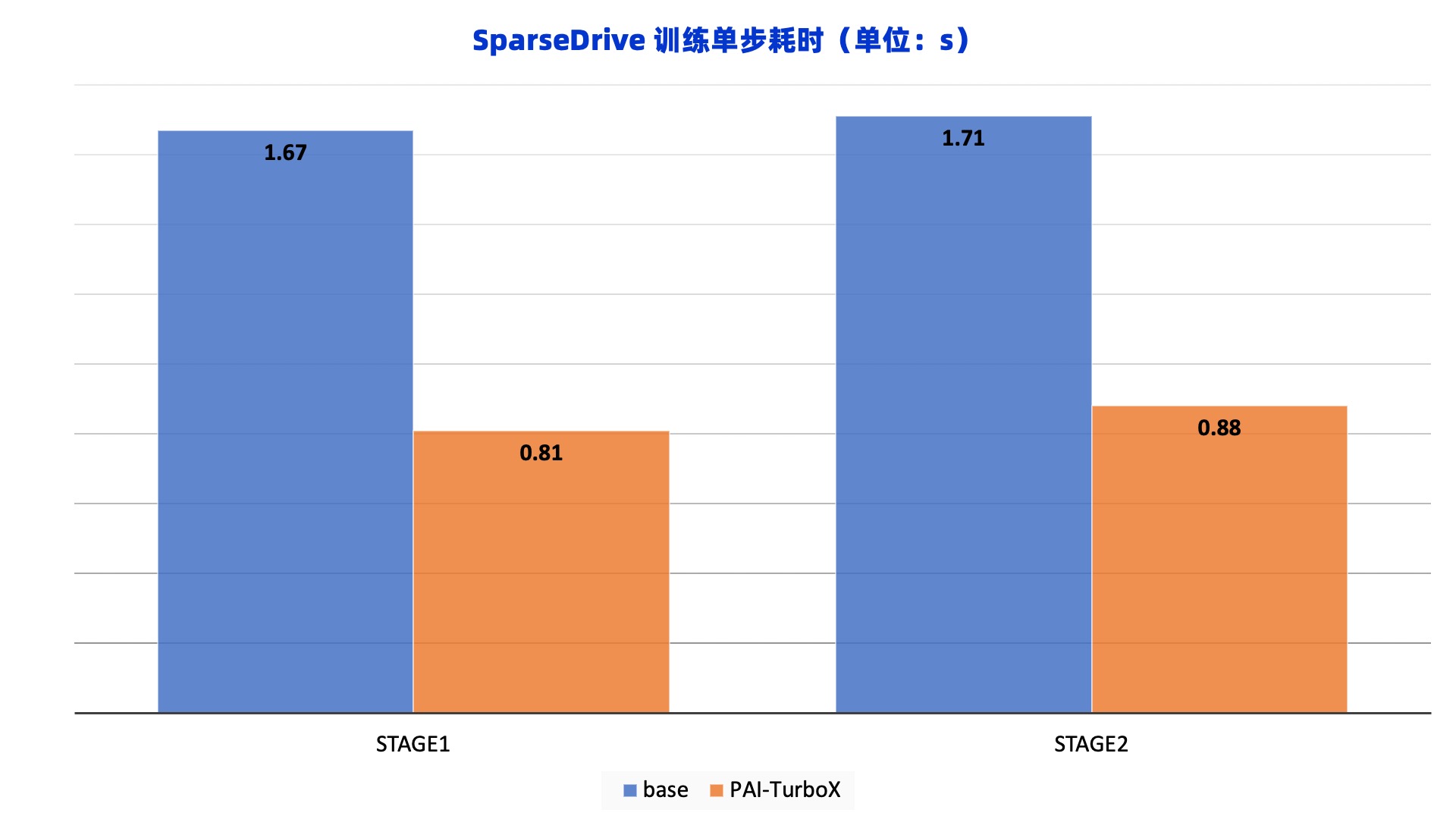
SparseDrive是一个通过稀疏场景表示实现了端到端自动驾驶的模型,应用PAI-TurboX可以在这个算法的两个训练阶段获得明显的训练速度提升,相同训练步数下两个阶段的时间可以分别缩减51.5%和48.5%。 ![]()
在PAI平台中使用PAI-TurboX
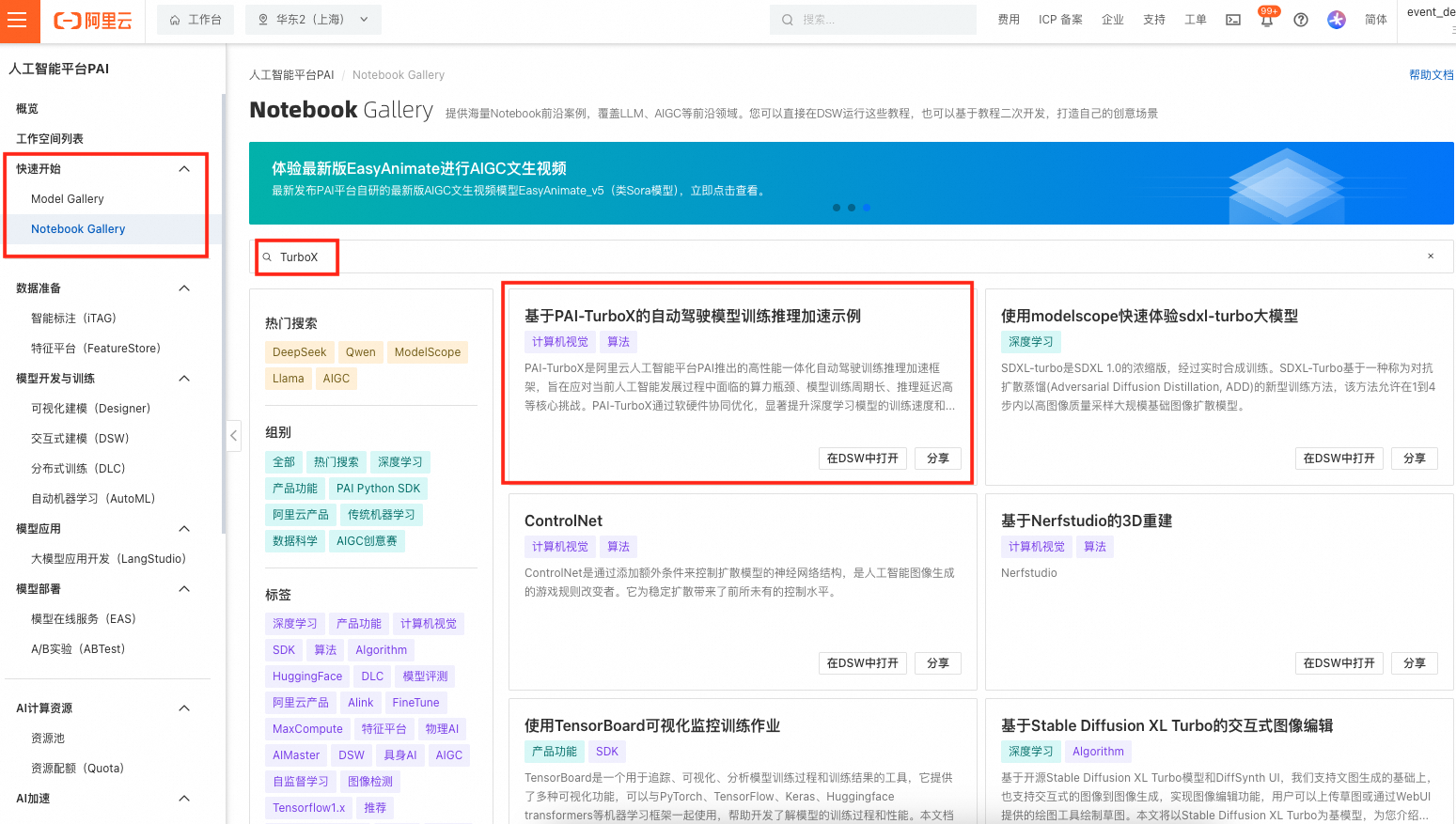
1、在PAI-Notebook Gallery广场找到PAI-Turbox加速例子的 Notebook,可以使用搜索框找到对应模型卡片或通过链接直达该模型:
https://pai.console.aliyun.com/#/dsw-gallery/preview/deepLearning/cv/turbox ![]()
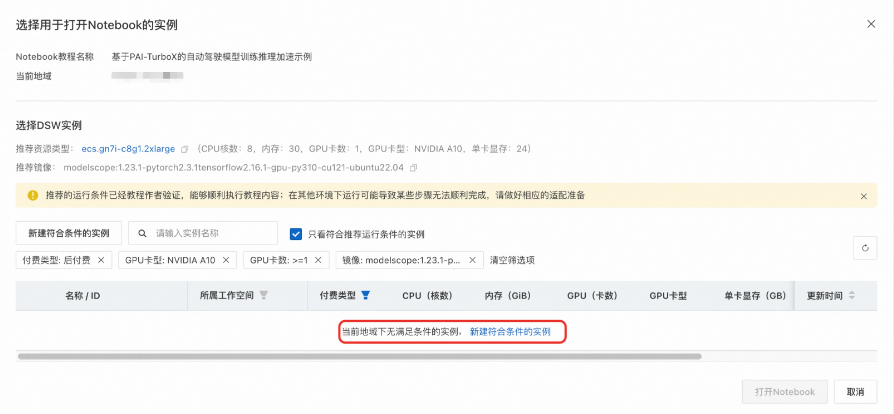
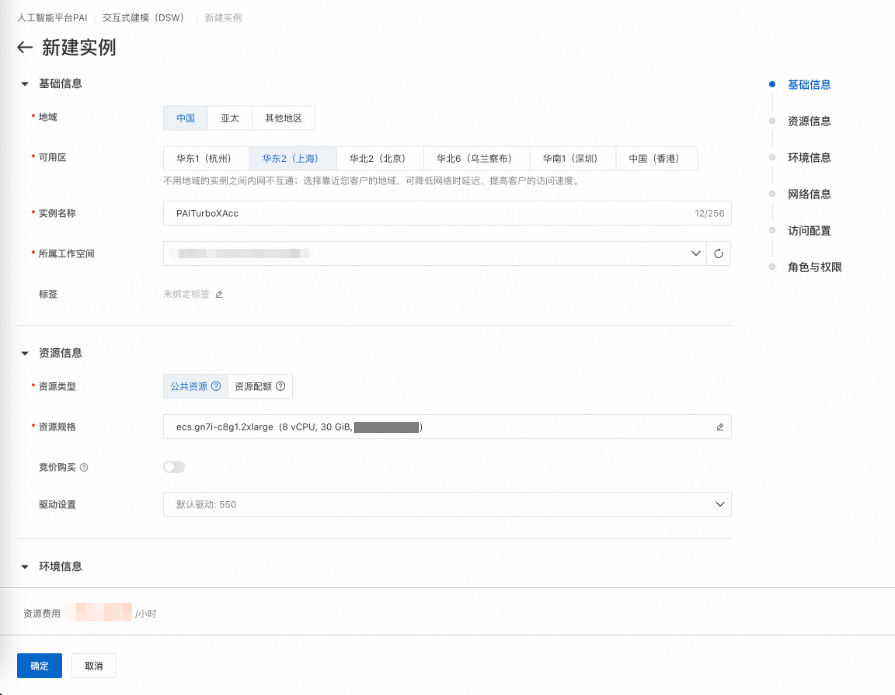
2、点击"在DSW中打开"按钮,创建对应所需的实例。 ![]()
3、填入实例所需的必填项后,完成实例的创建。 ![]()
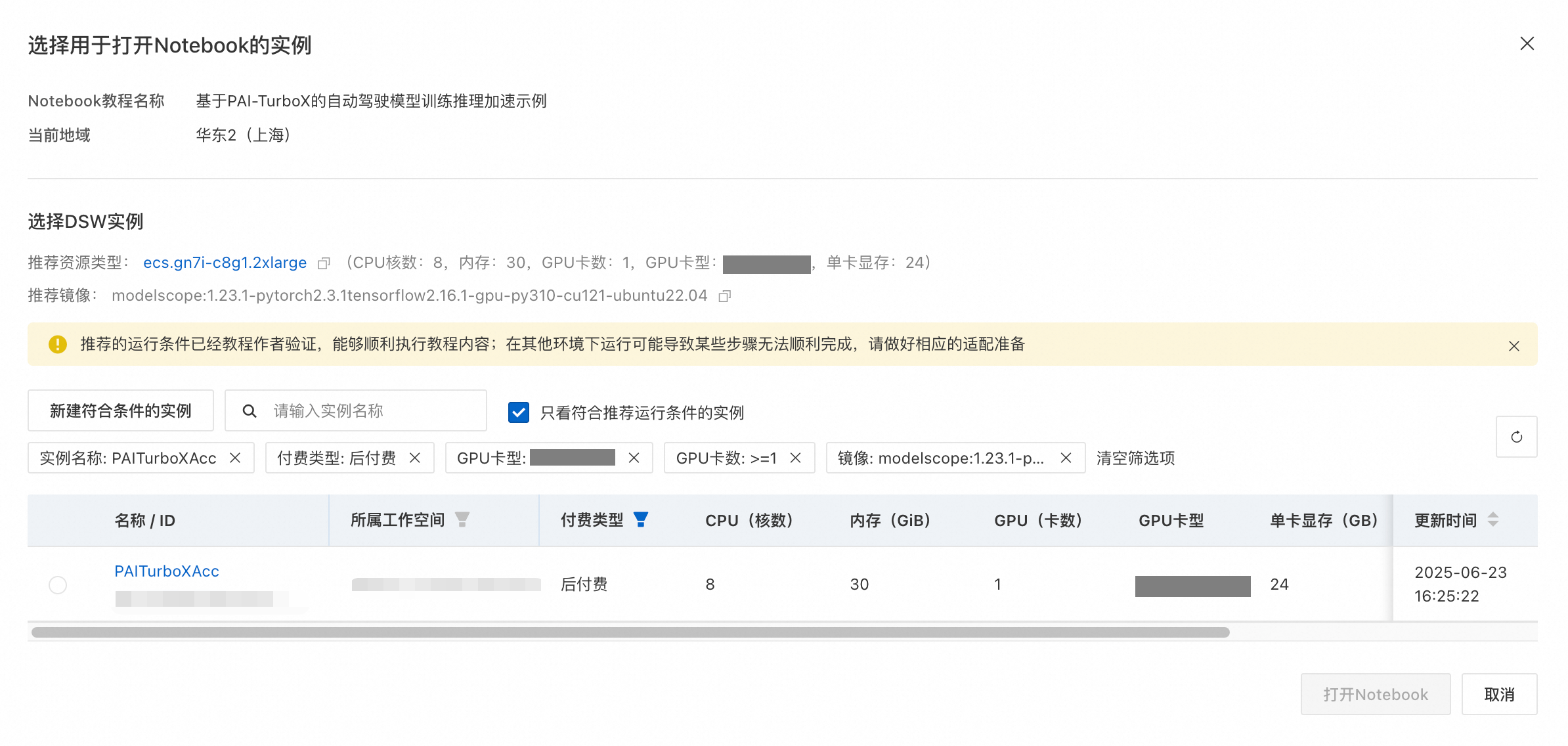
4、创建完成后,选择对应的实例进入Notebook。 ![]()
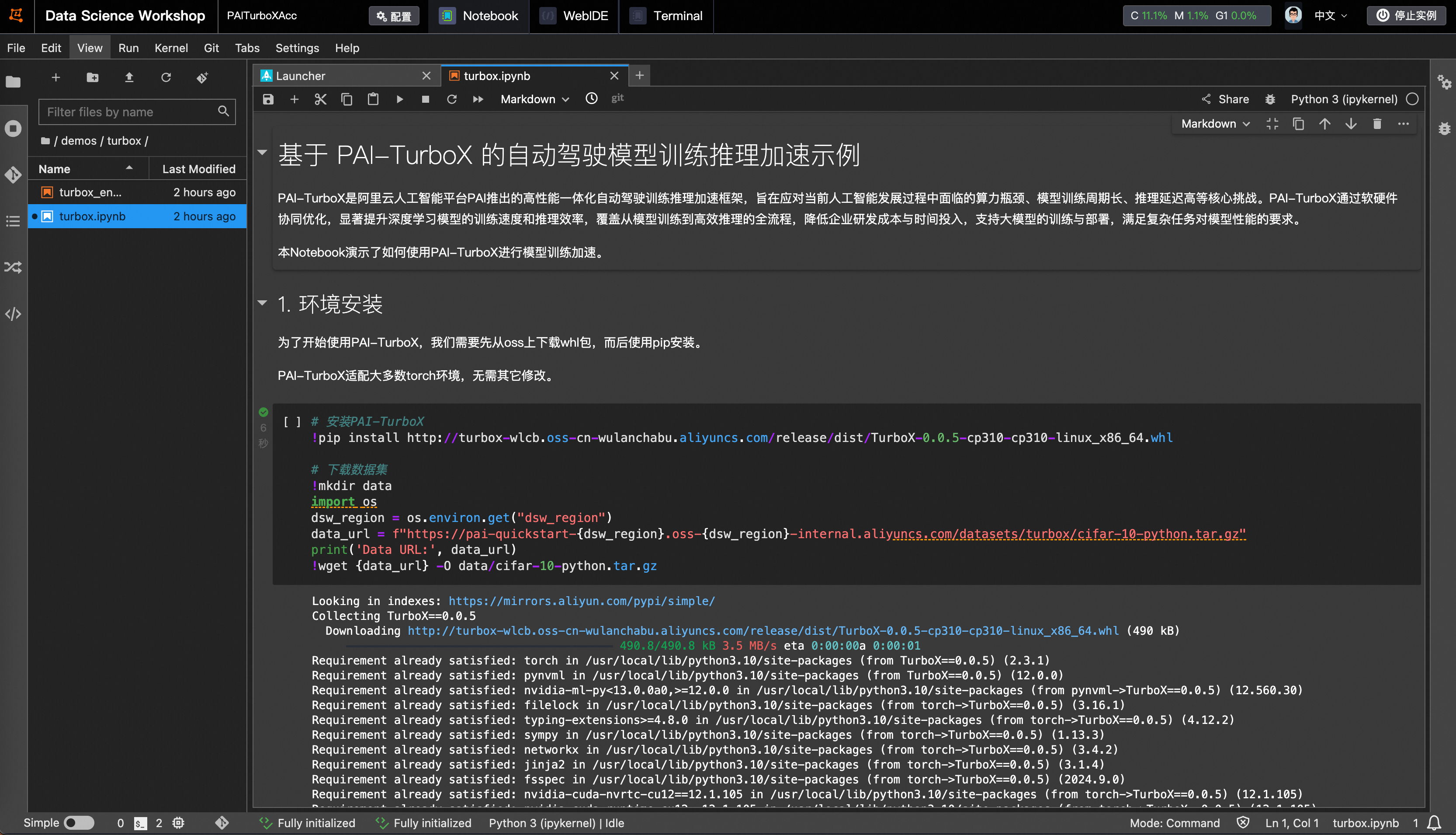
5、进入Notebook,按步骤进行点击,即可完成PAI-TurboX框架的拉起。 ![]()
未来规划
除了进一步优化当前的一些加速方案外,PAI-TurboX将进一步探索新的加速策略。随着单机GPU算力变得越来越强大,在自动驾驶模型的部分训练和推理场景中,GPU处理数据的速度比CPU加载和预处理数据的速度更快,为了充分利用GPU的算力资源,提出RemoteDataloader解决方案来将数据加载和预处理与GPU处理机器分离,通过其它节点预先加载和预处理数据。

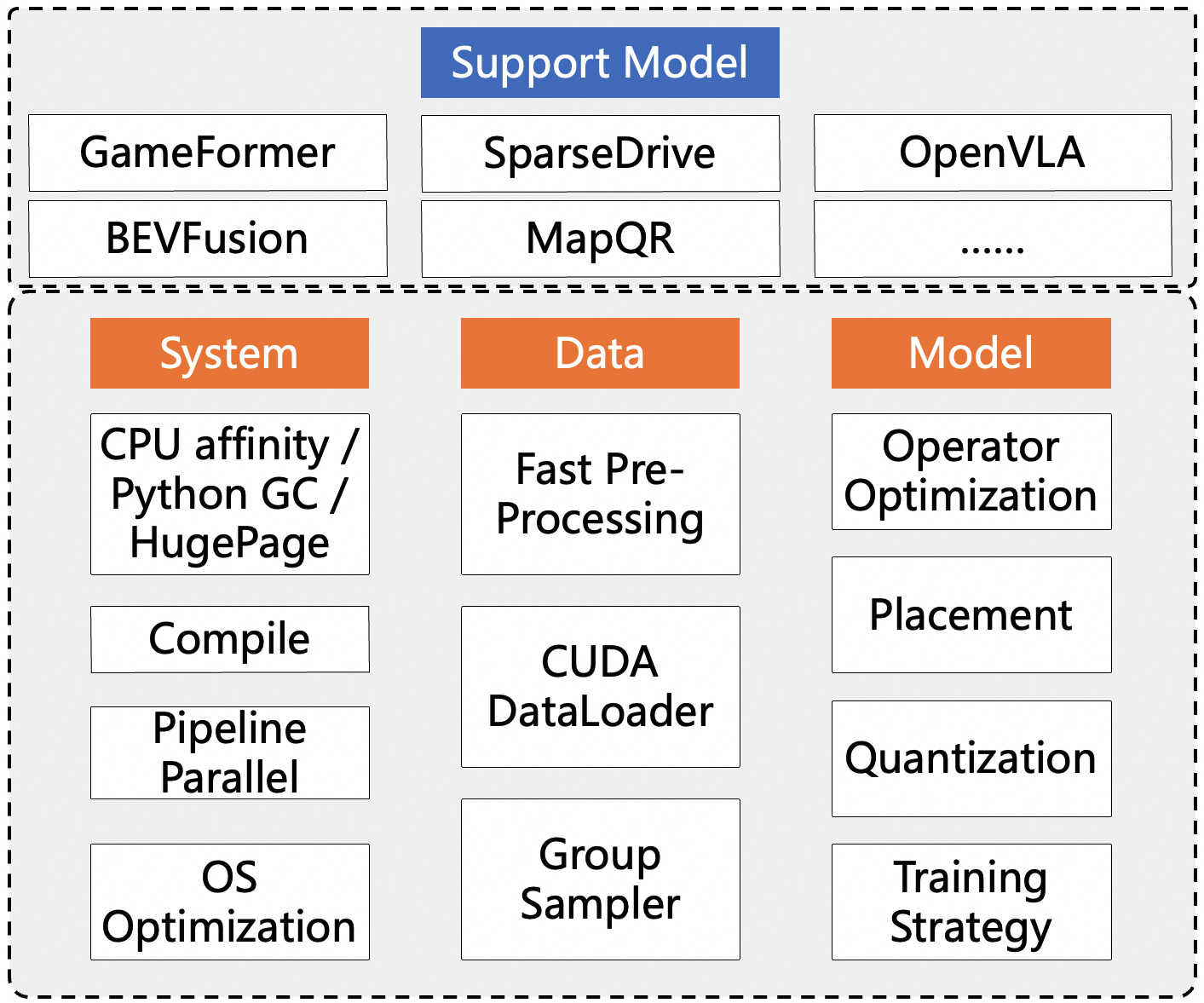 PAI-TurboX从系统、数据、模型三个方面针对自动驾驶面临的两大难题进行优化。
PAI-TurboX从系统、数据、模型三个方面针对自动驾驶面临的两大难题进行优化。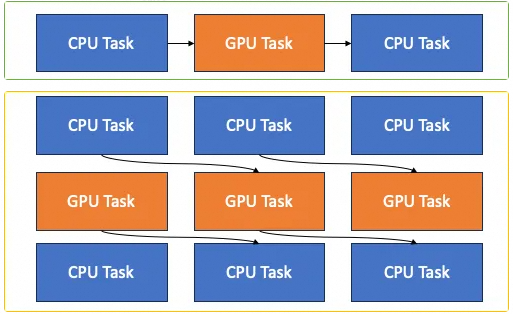
 BEVFusion流程图(BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework)
BEVFusion流程图(BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework)