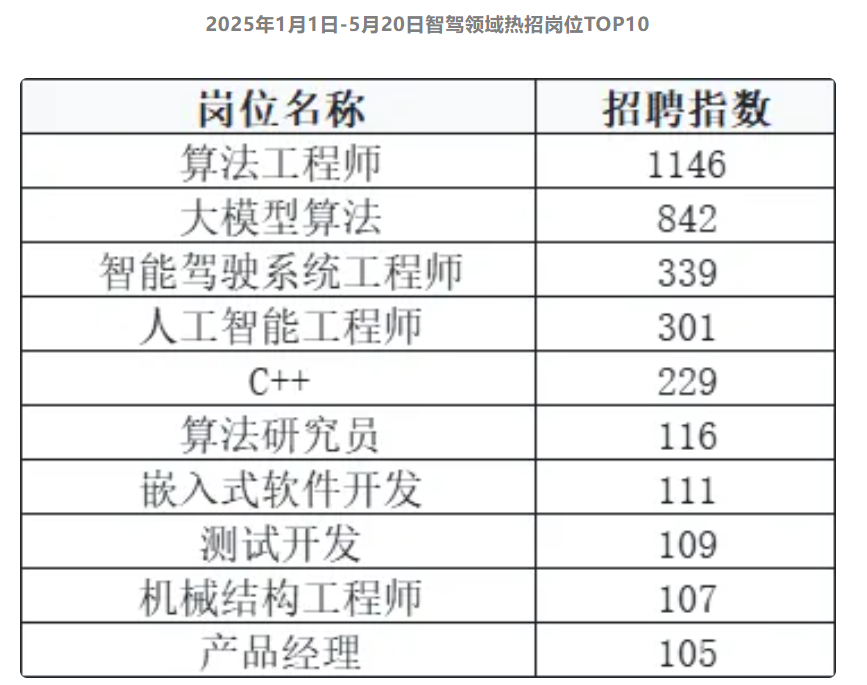
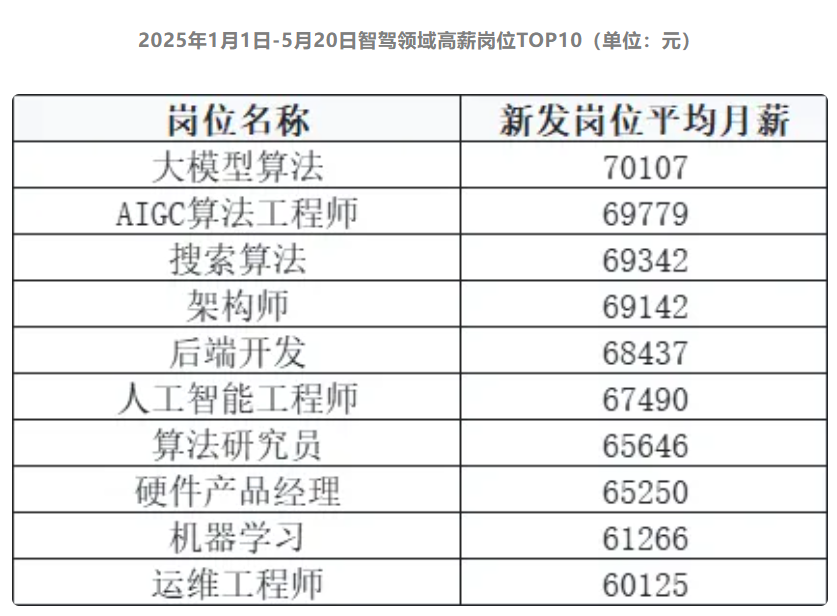

腾讯混元 TurboS 技术报告发布:560B 参数混合 Mamba 架构、自适应长短链融合
年初,腾讯混元 TurboS “快思考模型”正式发布,作为业界首款大规模混合 Mamba-MoE 模型,其在效果与性能上展现了出显著优势。这一突破得益于预训练阶段的 tokens 增训,以及后训练阶段引入长短思维链融合技术。 近日,腾讯混元 TurboS 发布了技术报告,其模型架构如下: 据介绍,腾讯混元 TurboS 核心创新体现在以下几个方面: 架构协同:巧妙地融合了Mamba架构处理长序列的高效性与Transformer架构卓越的上下文理解能力。这两种架构的结合,旨在取长补短,实现性能与效率的最大化。模型包含128层,采用了创新的“AMF”(Attention → Mamba2 → FFN)和“MF”(Mamba2 → FFN)模块交错模式。这种设计使得模型在拥有5600亿总参数(56B激活参数)的同时,保持了较高的运算效率。 自适应思维链 (Adaptive Long-short CoT):该机制是Hunyuan-TurboS的一大亮点。它借鉴了短思维链模型(如GPT-4o)的快速响应和计算友好特性,以及长思维链模型(如o3)强大的复杂推理能力。面对简单问题,TurboS自动激...