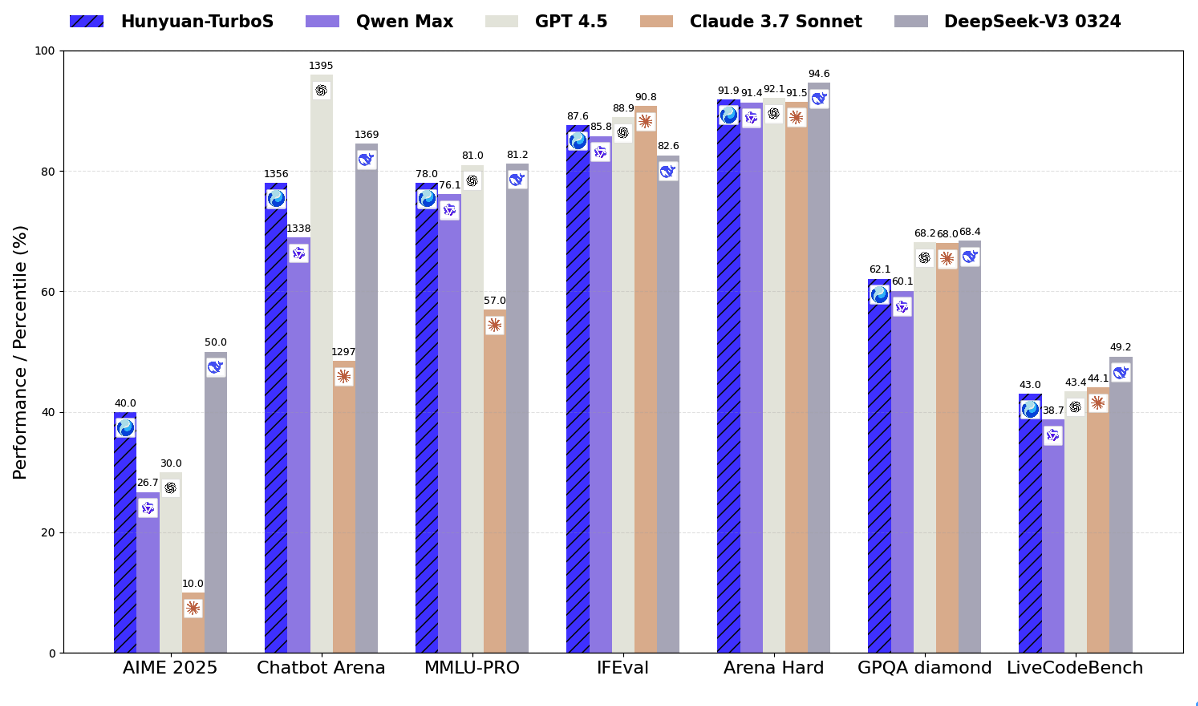


腾讯混元大模型矩阵全面升级并推出多款新品
腾讯混元宣布模型矩阵全面升级: 旗舰快思考模型混元TurboS、深度思考模型混元T1升级,并基于TurboS基座,腾讯新推出视觉深度推理模型T1-Vision和端到端语音通话模型混元Voice 腾讯混元图像2.0、腾讯混元3D v2.5及混元游戏视觉生成等一系列多模态模型同步“上新” 混元TurboS模型在全球公认的Chatbot Arena评测平台上已跻身前八名,在国内排名仅次于DeepSeek。其在代码和数学等理科领域的能力显著提升,得益于创新的预训练和后训练技术。 深度思考模型混元T1近期也迎来了新升级,在竞赛数学、常识问答和复杂任务的Agent能力上均有提升。 新发布的T1-Vision模型支持多图输入,具备原生长思维链,提高了图像理解的整体效果和速度。 混元Voice模型实现了低延迟语音通话,响应速度提升并增强了拟人性和情绪应用能力,目前已在腾讯元宝App灰度上线。 此外,腾讯同步更新了一系列多模态模型: 混元图像2.0实现了“毫秒级”生图和超高准确率。 混元3D v2.5凭借稀疏3D原生架构,在生成能力和可控性上取得突破,几何模型精度和纹理贴图大幅提升。 面向游戏领域,推出...