作者:常高伟,智能体协议 ANP 发起人。
关于 ANP:Agent Network Protocol (ANP) 是一个开源的智能体通信协议,目标是成为智能体互联网时代的 HTTP。
核心观点:
-
构建面向消费者的个人助手,推理能力瓶颈正在快速解决,目前还有两个瓶颈,一个是成本,一个是信息获取。如何让AI获取所有信息需要智能体通信协议来解决。
-
当前行业智能体或AI相关的开源通信协议,在设计和实现上比较完备的,有Anthropic的MCP,以及我们设计的ANP。
-
MCP与ANP在协议架构、身份认证、信息组织三个方面存在大的差异。
-
MCP是典型的CS(客户端-服务端)架构,ANP是典型的P2P(点对点)架构。
-
MCP身份认证基于Oauth标准,让客户端方便的访问当前互联网的资源;ANP的身份认证基于W3C DID标准,重点解决智能体之间的跨平台互操作性问题,让所有智能体都能互联互通。
-
MCP的信息组织基于JSON-RPC技术,本质上是API调用;ANP的信息组织基于语义网的Linked-Data技术,目的是构建一个便于AI访问、便于AI理解的数据网络。
-
MCP与ANP最大的区别在于世界观的差异:
-
智能体需要什么样的通信协议,取决于未来智能体互联网(Agentic web)有那些特性。关于这点,我们与MCP有不同的看法,会坚定持续的投入ANP的研发。
智能体通信协议为什么重要
随着Deepseek R1的上线,以及OpenAI O3 Mini和Deep Research的上线,我们能够发现一个明显的趋势,阻碍智能体构建的核心瓶颈:复杂任务推理能力限制,正在加速消失。
Deep Research从本质上看,可以认为是面向知识工作者的个人助理。
构建面向消费者的智能体,当前还存在两个瓶颈。一个是成本,预计2025年仍然会有一到两个数量级降低。另外一个就是信息:怎么让面向消费者的个人助理,能够获得足够的信息?
面向知识工作者的信息,很多都保存在开放的数据库、或者网站上,AI能够非常方便的获取。面向消费者的信息则复杂的多,受限于当前互联网的数据孤岛现象,这些信息当前是非常割裂的,而且开放性很差。
如何让面向消费者的个人助理能够方便、高效的获得消费者所需要的信息(工具能力也可以理解为一种信息),是智能体通信协议要解决的问题。
备注:至于为什么是通信协议而不是“Computer Use”,可以参考这篇文章:智能体互联网有什么不同。
MCP与ANP简介
MCP(Model Context Protocol ):模型上下文协议(MCP)是一个开放协议,使LLM应用能够与外部数据源和工具无缝集成。无论是构建AI驱动的IDE、增强聊天界面,还是创建自定义AI工作流,MCP都提供了一种标准化方式,将LLM与所需的上下文连接起来。
MCP:https://spec.modelcontextprotocol.io/
AgentNetworkProtocol(ANP)是为智能体网络(Agentic Web)设计的开放协议框架。ANP实现了去中心化的身份认证,能够让任意两个智能体进行连接。同时设计了一个智能体描述规范,让智能体之间能够进行更加高效的数据交换与协作。
ANP:https://github.com/chgaowei/AgentNetworkProtocol
ANP可能是全网最早发布的面向智能体的开源通信协议。我们是先发布的代码,协议在飞书文档,后来协议迁移到了github。
如果你知道其他不错的开源项目,也欢迎介绍给我。
MCP与ANP的区别
下面,我将从三个方面来详细的阐述MCP与ANP的区别,包括协议架构、身份认证、信息组织,最后讲下设计理念上的区别,以及为什么会有这些区别。
协议架构:CS VS P2P
MCP协议架构
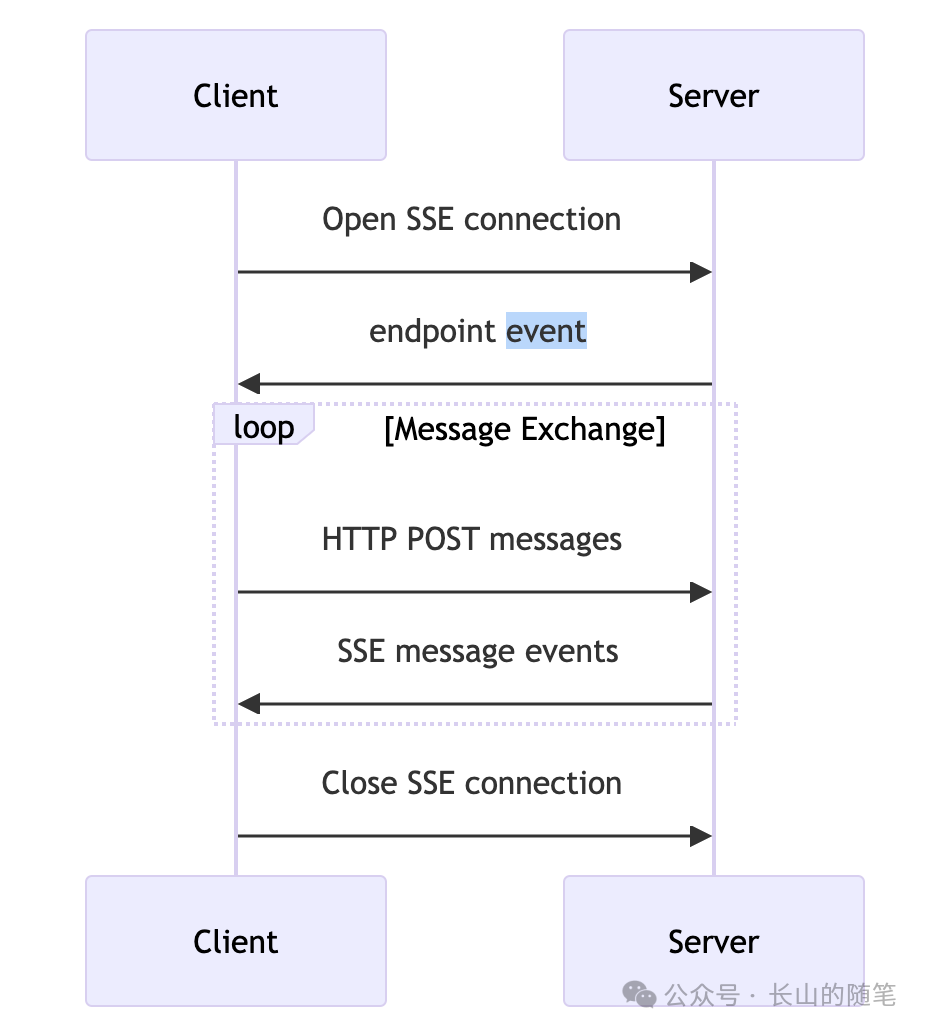
MCP是典型的客户端-服务端架构(Client-Server),客户端使用MCP协议连接到MCP Server,然后使用协议访问Server的各种信息以及工具能力。
client和Server之间可以通过stdio或者http建立双向通信链路。使用http的时候,Client使用http post发送消息,使用http sse接受服务端的事件通知。
ANP协议架构
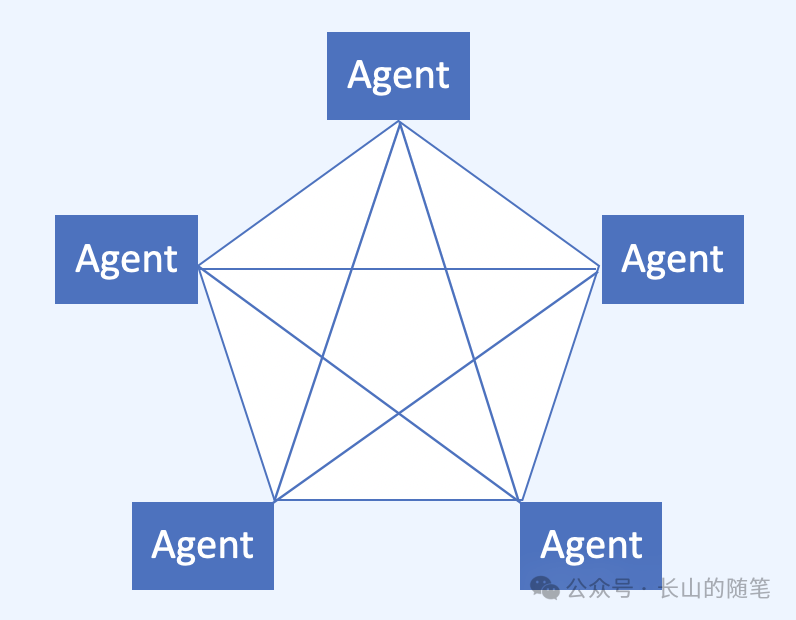
ANP是典型的P2P(peer-to-peer)架构,也就是说,任意一个智能体,都可以使用ANP,连接到另外一个智能体。
ANP当前在底层使用的是HTTP协议。一个智能体既可以使用HTTP连接其他的智能体,也通过HTTP接收其他智能体的消息。当然,websocket、私有传输层协议理论上也是支持的。
ANP选择使用P2P架构的主要原因,是为了让智能体既能够主动的向其他智能体发起请求,也能够随时接收其他智能体的请求。
MCP使用CS架构时,如果客户端没有连接到服务端,服务端是无法发送消息给客户端的。当然,如果一个客户端同时也可以做服务端,则MCP也可以看做是一个P2P架构,只是看起来会有些别扭。
真正的P2P架构,不单单物理连接是P2P,他们的角色与定位上也必须是P2P,这才是P2P的核心。
身份认证:Oauth VS DID
身份认证是智能体通信协议关键部分,同时也是最有挑战的部分。因为要解决一个难题:智能体之间如何进行跨平台身份认证。只有这样,智能体才能够与其他所有的智能体进行协作。
MCP身份认证
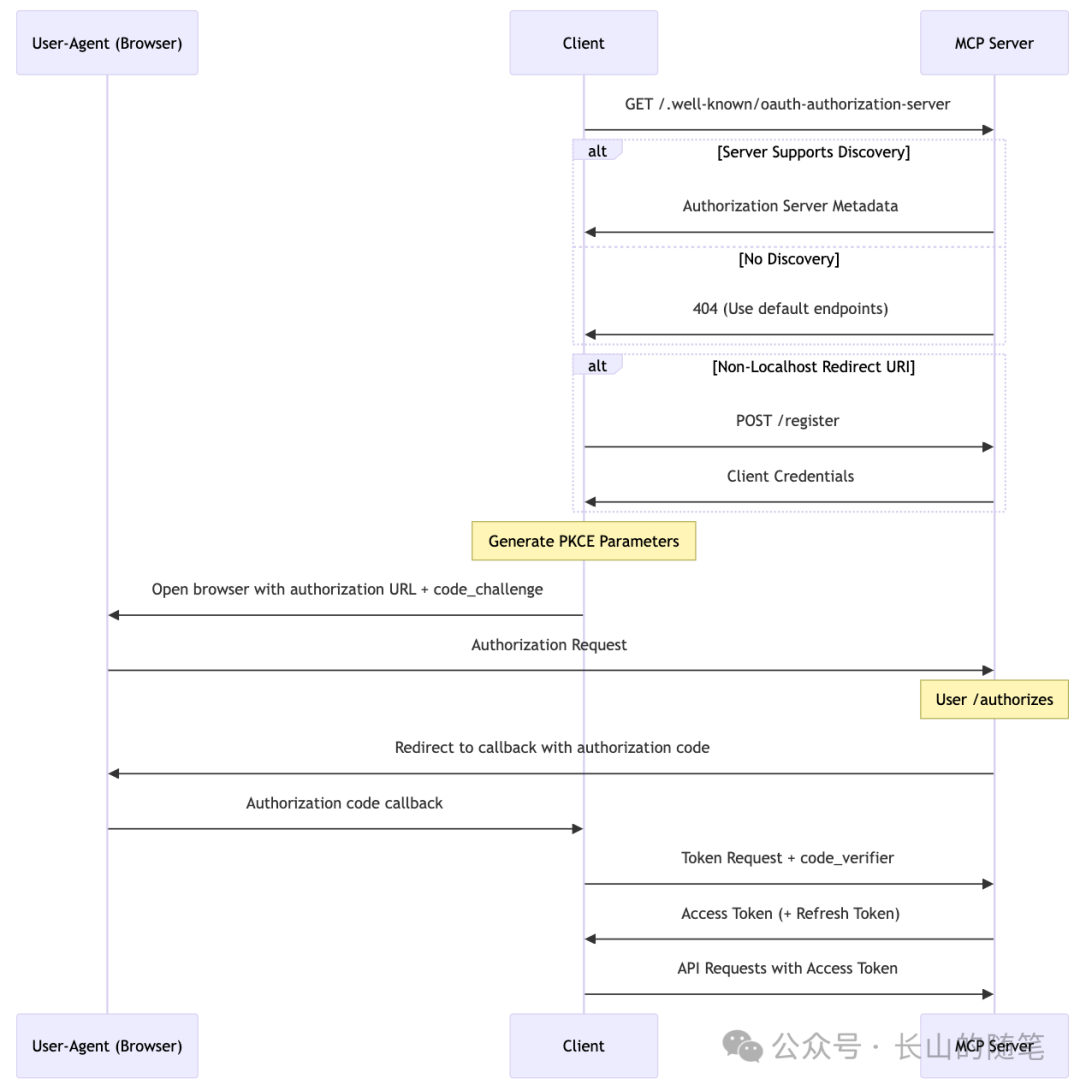
MCP最早发布的时候,是不支持身份认证的,导致它连接远程的server很不方便。最新的草案版本已经支持客户端和服务器之间的身份认证。
MCP的身份认证方案在技术上以Oauth2标准为核心。
OAuth是一种开放标准的授权框架,旨在为用户资源的访问提供一种安全、便捷且灵活的授权方式,使得第三方应用能够在用户授权的情况下访问用户在另一个服务提供商处存储的资源,而无需获取用户的用户名和密码等敏感信息。我们常用的使用Google、微信账户登录三方应用都是基于Oauth技术,它在互联网上应用的比较广泛。
MCP发布的协议草案是社区的第二个版本,相对第一个版本,它有以下的改进:
-
使用的是Oauth2.1(仍然处于草案状态),简化了协议,增强了安全性
-
支持授权服务器发现,使用OAuth 2.0 授权服务器元数据协议,让客户端能够自动发现和获取授权服务器的相关配置信息,如授权端点、令牌端点、支持的授权类型、加密算法等。
-
支持 OAuth 2.0动态客户端注册(DCR, Dynamic Client Registration Protocol ),客户端可以自动向服务器发起注册,而不需要前置手动登录server注册。简化客户端集成服务器的成本。
整体流程如下:
ANP身份认证
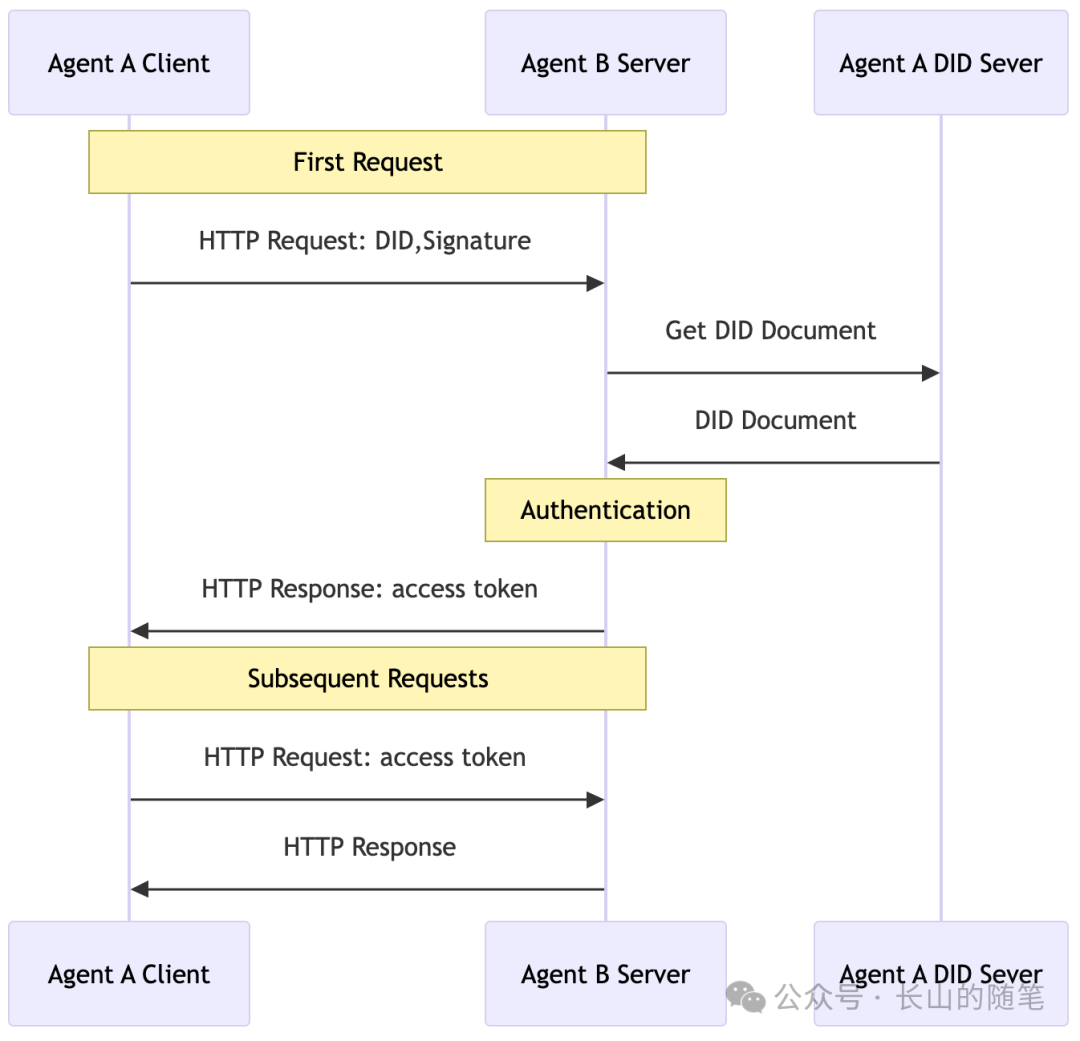
ANP的身份认证方案在技术上是以W3C的DID规范为核心。
W3C DIDs标准于2022年发布为W3C推荐标准,是一种支持可验证、去中心化数字身份的新型标识符。基于DIDs,可以让用户真正掌握自己的身份,也可以提高不同应用之间身份的互操作性。
目前已经有很多应用在使用W3C DID规范,比较知名的是最近比较火的bluesky,它的底层协议AT Protocol就使用了W3C DID作为身份认证方案。
ANP身份认证整体流程如下:
使用DID作为身份认证技术最大的好处就是身份的互操作性。不同平台的智能体可以使用DID互相进行身份认证,而不需要他们都用一个平台的账号,或者相互之间进行注册操作。
因为DID天生就是为了去中心化身份而设计。
关于ANP DID身份认证的相关文章:
对比MCP和ANP的身份认证,我们能够发现几点区别:
-
MCP的身份认证方案是AI连接到原有互联网的一个不错的选择,当前很多大的应用基本都支持Oauth。
-
ANP的使用的DID技术是一种比较新的规范,普及的程度没有Oauth广泛。需要应用修改代码来支持。
-
Oauth解决的是如何让模型访问用户在现有互联网应用上的资源。DID解决的是两个不同平台的智能体之间如何进行身份认证。
单纯从互操作性上来看,基于DID的方案要比基于Oauth的方案更加简单,交互更少:
究其根本原因,Oauth不是专门为身份的互操作性而设计的。DID则天然是一个去中心化身份技术,对互操作性更加的友好。
关于智能体的身份,这确实是一个非常有挑战的问题。当前还有很多问题需要持续解决:
-
在进行身份跨平台互相认证的时候,如何做到既不泄漏用户隐私,又能够获得必要的身份信息?
-
对于用户的权限,如何做到更加细颗粒度的权限控制?而不是用一个ID和所有的智能体通信。
-
如何判断一个智能体的请求,是否经过用户的人工授权?有些敏感的操作,智能体无权自主发起。
-
如何让用户彻底的掌握身份的所有权,而不是使用平台赋予的权限?
这些新的问题,基于W3C DID可能会更加容易解决。很多问题我们已经有了初步的解法,后面会慢慢的完善、发布。
信息组织:RPC VS Linked-Data
在智能体对外输出信息的组织上,MCP和ANP采用了不同的技术。
MCP信息组织
MCP使用了JSON-RPC来读取/操作服务器的资源与工具能力,JSON-RPC(JavaScript Object Notation - Remote Procedure Call)是一种 基于 JSON 格式的远程过程调用(RPC)协议。它允许客户端调用远程服务器上的方法,并接收返回的 JSON 结果。
使用MCP,可以让服务器列出所有的资源或工具列表,然后读取指定资源,或者调用指定工具。客户端也可以订阅资源,在资源状态发生更改的时候服务器主动通知客户端。
资源或工具的格式是服务器自定义的,由模型决定读取、操作那些资源与工具。
MCP服务器对外提供信息输出的方式,本质上可以理解为一种特殊的API。
ANP信息组织
ANP在智能体对外输出信息的组织上以语义网的Linked-Data技术为核心。
Linked Data(关联数据) 是一种用于结构化数据共享和互联的技术,基于Web标准(如 RDF、SPARQL、URI),旨在通过唯一标识符(URI)连接不同来源的数据,使其可以被机器可读和语义理解。
在实现上,我们定义了一个智能体描述规范,用于描述智能体的身份、能力、实体信息、API接口等。
智能体描述文档采用JSON-LD格式,JSON-LD是一种基于JSON的Linked Data(关联数据)格式,可以使不同的数据链接成一个数据网络,同时便于机器理解。
比如,一个咖啡店的智能体描述文档描述了咖啡店的名称、所有人、位置、工作时间等信息,文档中也包含了多个在售产品信息URL,通过这些URL,AI可以继续访问产品的JONS-LD文档,获得产品的详细信息。同理,产品详细信息中也可能包含新的JSON-LD URL。
这样,只要有智能体描述文档,就可以获得这个智能体对外暴露的所有公开信息。从而可以构建一个全新的、使用JSON-LD链接在一起,便于AI访问的数据网络。对应我们现在已经存在的由web页面链接在一起,便于人访问的互联网,到时候会形成两张网络:一张网络为人访问而设计,另外一张网络为AI访问而设计。
除了数据连接,Linked Data技术还有一个核心特点:语义理解。我们设计的JSON-LD文档采用schema.org作为语义基础,schema.org定义了一套用于描述现代Web的语义模型,可以让两个智能体对同一个字段有同样的理解,提升了智能体之间信息理解的准确性,同时也便于程序处理。
使用Linked Data技术,智能体的公开信息可以方便的被搜索引擎爬取,用户可以先通过搜索引擎快速的找到能够提供服务的智能体,然后根据智能体描述文档,与智能体进行交互与协作。
对比MCP的信息组织方式,ANP基于语义网的方式继承了Web架构的开放性,搜索引擎可以对智能体的公开信息进行索引,智能体可以利用搜索引擎高效的检索信息,然后直接连接其他的智能体。
设计理念的区别
上面是MCP与ANP在设计细节上的区别。
如果更加抽象的总结一下,MCP与ANP最大的区别在于世界观的差异:
为什么会有这种不同?
最主要还是MCP与ANP的目的不同。
严格意义上来说,MCP并不是一个面向智能体的通信协议,从它的名字也能够看到,它是一个模型上下文协议,目的是为模型提供上下文能力,让模型能够更加方便的接入现在的互联网,丰富Chatbot产品的能力。
而我们设计ANP的时候,没有一个我们自己的产品,我们直接立足于未来,基于我们对未来Agentic web的理解,来设计ANP。我们的目的是构建一个全新的智能体网络,这个网络能够充分释放AI的能力。
智能体需要什么样的通信协议
我们认为MCP是一个非常不错的协议,也是当前模型访问互联网的最优解决方案,要比Computer Use方案更有生命力。Anthropic也用他们的影响力,让行业看到了这种方案的优势。
不过,我们认为MCP可能是一种过渡形态,是当下AI访问互联网的最优解。如果互联网因为智能体而发生大的改变,MCP未必是最优解。
所以,智能体需要什么样的通信协议,取决于未来智能体互联网(Agentic web)有那些特性。我们总结了几点(详细可以看这篇文章:智能体互联网有什么不同):
-
智能体会渗透到互联网的各个角落,一个人或组织可能有多个智能体为其服务
-
所有智能体之间都可以互联互通,这是释放AI能力的必要条件
-
个人助手成为互联网的新入口,智能体之间的连接远大于人与智能体之间的连接
-
网络更加扁平化,智能体之间可以直接连接,无需三方平台
上面的这几点是我们设计ANP的核心基础。
当然,MCP也可能会进化、迭代,我们乐见其成。任何一个组织或个人都无法独立完成一个如此重要的行业标准,我们也一样,我们愿意与行业所有的人合作。
几个常见的问题
关于和MCP的关系,经常会有人问几个问题:
联系我们
我们正在开发一个用于智能体通信的开源标准协议:AgentNetworkProtocol(ANP),项目地址:https://github.com/chgaowei/AgentNetworkProtocol
AgentNetworkProtocol的目标是成为智能体互联网时代的HTTP。我们的愿景是定义智能体之间的连接方式,为数十亿智能体构建一个开放、安全、高效的协作网络。
同时我们也在开发智能体连接的基础设施,让智能体相互之间能够进行去中心化的身份认证、高效的数据通信与协作。
如果你也对智能体通信协议感兴趣,或者有类似的需求,欢迎联系我们:
-
微信:flow10240
-
邮箱:chgaowei@gmail.com
如果你对智能体通信协议感兴趣,也欢迎加入我们开源社区贡献代码。