随着大模型时代带来的各种新型应用探索,结合传统基于文本匹配的精确检索与语义检索所带来的增益日益显著,尤其在一些深度依赖关键字词匹配的场景中,这种需求变得尤为关键。目前,阿里云向量检索服务 Milvus 版(简称阿里云 Milvus)集成开源 Milvus2.5版本内核,在支持向量检索的基础上,新增支持原生全文检索、基于特定词汇的精准文本匹配等功能,在 RAG、多模态搜索等场景下搜索精度明显提升,使用体验大幅优化。
阿里云 Milvus 是一款全托管向量检索引擎,100%兼容开源 Milvus,提供大规模AI向量数据的相似性检索服务。凭借其开箱即用的特性、灵活的扩展能力和全链路监控告警,成为多样化 AI 应用场景的理想选择。本次2.5版本的上线,使得阿里云 Milvus 能够实现从文本输入到向量检索的端到端流程,在电商、法律、新闻等多行业搜索场景中发挥多模态融合和场景化增强的价值。
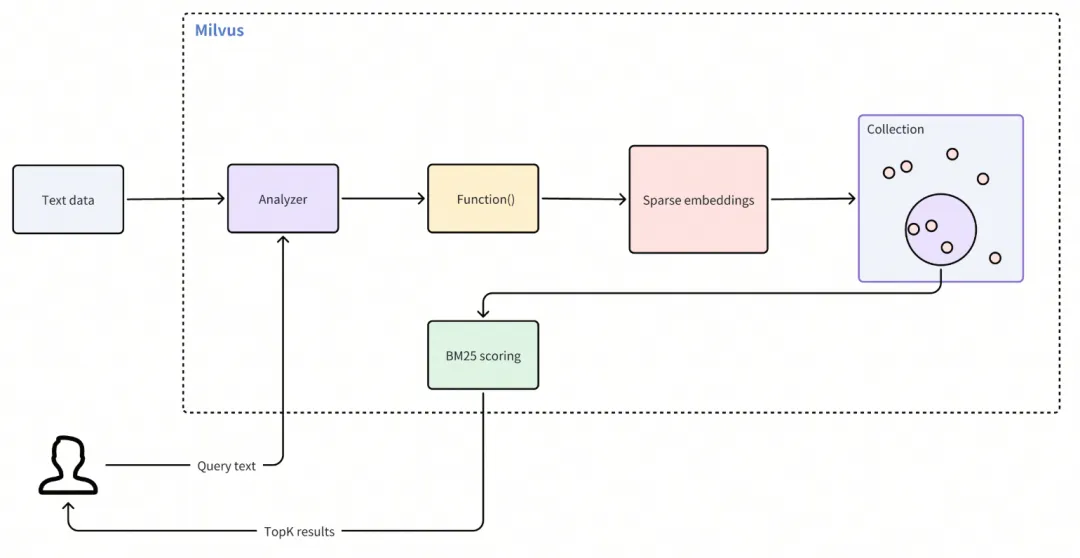
全文检索(Full Text Search)
全文检索能力基于内置的 Sparse-BM25 算法,首次实现原生全文检索功能,与现有的语义搜索能力形成完美互补。
核心能力:
-
内置分词器,无需额外预处理:通过内置分词器(Analyzer)与稀疏向量提取能力, 可直接接受文本输入,自动完成分词、停用词过滤与稀疏向量提取,无需依赖外部模型(如BGE-M3等)。
-
实时 BM25 统计:数据插入时动态更新词频(TF)与逆文档频率(IDF),确保搜索结果的实时性与准确性。
-
混合搜索性能增强:基于近似最近邻(ANN)算法的稀疏向量检索,性能远超传统关键词系统,支持亿级数据毫秒级响应,同时兼容与稠密向量的混合查询。
典型应用场景:
![]()
全文检索
实现全文检索功能主要步骤:
-
创建 Collections:设置带有必要字段的 Collections,并定义一个将原始文本转换为稀疏向量的函数
-
插入数据:将原始文本文档插入 Collections
-
执行搜索:使用查询文本搜索你的 Collections 并检索相关结果
代码示例如下:
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(uri="http://localhost:19530")
# 定义 Collection# id:作为主键,由auto_id=True 自动生成# text:存储原始文本数据,用于全文搜索操作。数据类型必须是VARCHAR ,因为VARCHAR 是 Milvus 用于文本存储的字符串数据类型。设置enable_analyzer=True 以允许 Milvus 对文本进行标记化# sparse:矢量字段:预留矢量字段,用于存储内部生成的稀疏嵌入,以进行全文搜索操作。数据类型必须是SPARSE_FLOAT_VECTORschema = client.create_schema()schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True)schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True)schema.add_field(field_name="sparse", datatype=DataType.SPARSE_FLOAT_VECTOR)
# 定义一个将文本转换为稀疏向量表示的函数bm25_function = Function( name="text_bm25_emb", # Function name input_field_names=["text"], # Name of the VARCHAR field containing raw text data output_field_names=["sparse"], # Name of the SPARSE_FLOAT_VECTOR field reserved to store generated embeddings function_type=FunctionType.BM25,)schema.add_function(bm25_function)
# 向量配置索引index_params = client.prepare_index_params()index_params.add_index( field_name="sparse", index_type="AUTOINDEX", metric_type="BM25")
# 创建 Collectionsclient.create_collection( collection_name='demo', schema=schema, index_params=index_params)
# 插入文本数据client.insert('demo', [ {'text': 'information retrieval is a field of study.'}, {'text': 'information retrieval focuses on finding relevant information in large datasets.'}, {'text': 'data mining and information retrieval overlap in research.'},])
# 执行全文搜索search_params = { 'params': {'drop_ratio_search': 0.2},}
client.search( collection_name='demo', data=['whats the focus of information retrieval?'], anns_field='sparse', limit=3, search_params=search_params)
文本匹配(Text Match)
支持基于特定词汇的精准文本匹配搜索,可结合标量过滤进一步细化查询结果,满足精确检索的需求。
核心能力:
-
词项预处理:利用分词器与索引技术,对文本进行标准化处理(如大小写转换、词干提取)。
-
混合查询模式:在向量相似性搜索的基础上,叠加标量条件过滤(如“日期 > 2023”),实现多维度精准检索。
-
性能优化:索引构建与查询执行效率提升,满足高并发场景下的低延迟需求。
典型应用场景:
实现本文匹配的代码示例如下,如若配置文本分析器后续便可结合标量过滤功能做文本匹配过滤以细化查询结果:
启用文本匹配
from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema(auto_id=True, enable_dynamic_field=False)
schema.add_field( field_name='text', datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True, # 是否启用该字段的文本分析 enable_match=True # 是否启用文本匹配)
可选:配置分析器
analyzer_params={ "type": "english"}
schema.add_field( field_name='text', datatype=DataType.VARCHAR, max_length=200, enable_analyzer=True, analyzer_params=analyzer_params, enable_match=True, )
使用文本匹配搜索
# Match entities with `keyword1` or `keyword2`filter = "TEXT_MATCH(text, 'keyword1 keyword2')"
result = MilvusClient.search( collection_name="YOUR_COLLECTION_NAME", anns_field="embeddings", data=[query_vector], filter=filter, search_params={"params": {"nprobe": 10}}, limit=10, output_fields=["id", "text"])
使用文本匹配查询
filter = "TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')"
result = MilvusClient.query( collection_name="YOUR_COLLECTION_NAME", filter=filter, output_fields=["id", "text"])
此外,阿里云 Milvus 2.5新增支持分页查询和标量过滤模板等功能,进一步提升了产品的易用性和性能。
立即体验
我们诚邀您立即体验阿里云向量检索服务Milvus 2.5版本的强大功能!
产品新用户可免费试用入门版8 vCPU 32 GiB1个月,领取地址(https://x.sm.cn/4AqoOSM)
此外,阿里云为了回馈新老用户,推出了重大优惠:
向量检索服务Milvus版 限时年付5折!
阿里云向量检索服务 Milvus 版,将持续打磨产品,不断优化产品的功能、性能和使用体验,为用户提供更加专业、灵活、高效的向量搜索引擎服务,助力企业轻松应对海量非结构化数据管理挑战,实现业务价值最大化,欢迎大家前往产品控制台购买体验!