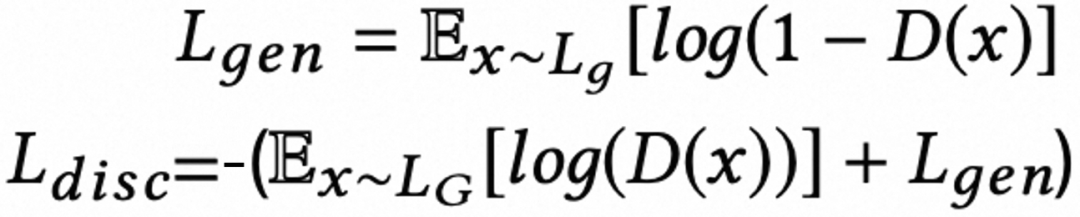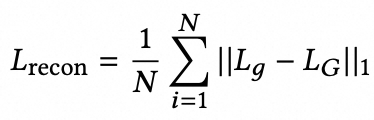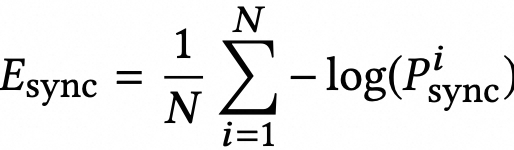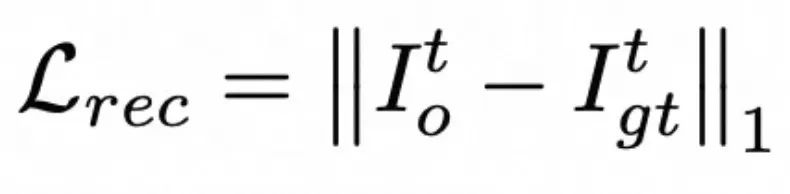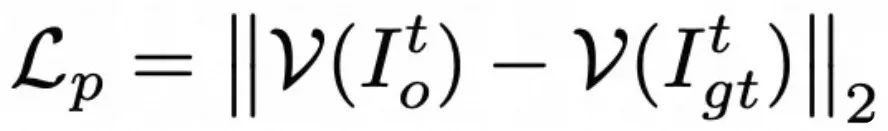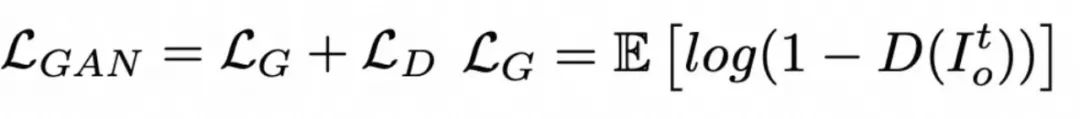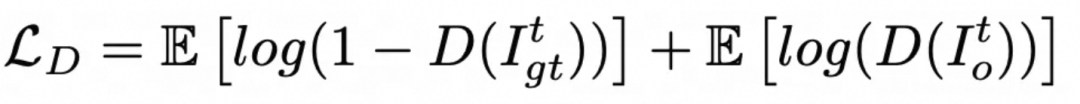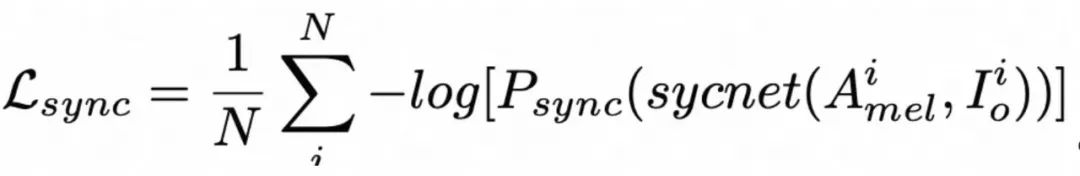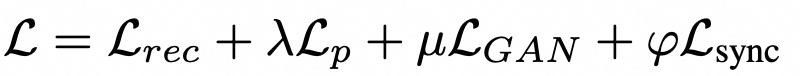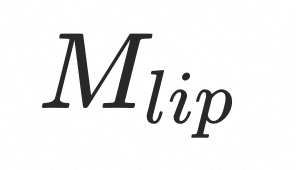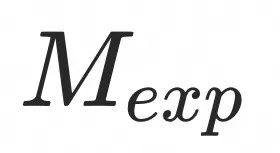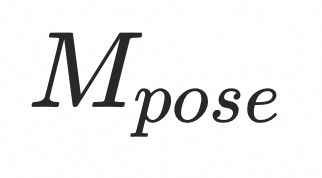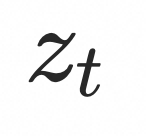一种新的商品表现形态,内容几乎存在于手淘用户动线全流程,例如信息流种草内容、搜索消费决策内容、详情页种草内容等。通过低成本、高时效的AIGC内容生成能力,能够从供给端缓解内容生产成本高的问题,通过源源不断的低成本供给倒推消费生态的建立。过去一年,我们通过在视频生成、图文联合生成、个性化文案、人设Agent等核心技术上的持续攻关,AIGC内容生成在手淘多个场景取得了规模化落地价值。本专题《淘宝的AIGC内容生成技术总结》是我们摸索出的一部分实践经验,我们将开启一段时间的内容AI专题连载,欢迎大家一起交流进步。
多模态驱动的人物视频生成技术具有重要的应用价值和发展前景。在商业领域中,虚拟主播与数字员工正逐步改变传统的营销和服务模式。通过提供不间断的智能客服、直播带货等服务,它们显著提升了运营效率和用户体验。此外,在教育、医疗及文化娱乐产业等领域内,人物也有着广泛的应用场景。
然而,要实现上述丰富应用场景,则需掌握并突破一系列关键的技术瓶颈。为了深入理解人物视频生成技术的发展现状及其工作机制,本文首先回顾了该领域的关键技术,包括口唇驱动、头部驱动以及肢体驱动,并选取每项技术中的两篇代表性研究进行详细介绍。随后,文章进一步探讨了人物视频生成技术在淘天业务场景中的应用形式与效果,为推动人物视频生成技术的实际落地提供了新的启示。
▐ 口唇驱动
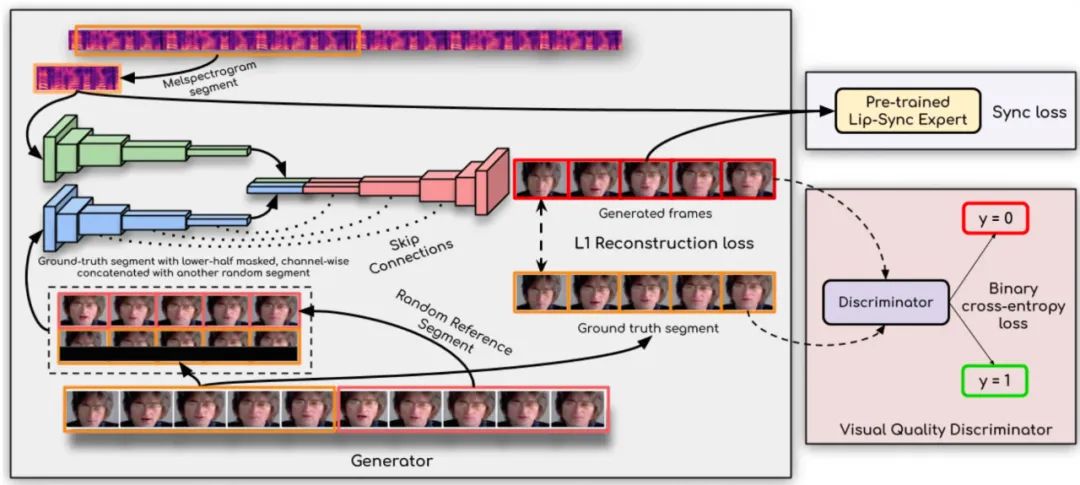
在口唇驱动领域的一个经典工作是由印度研究人员在 MM20 上发表的 Wav2Lip[1]。该方法目前在 GitHub 上已获得了超过 10,700 次 star 的关注。Wav2Lip 是一个基于生成对抗网络(GAN)的语音驱动口唇方案,采用逐帧独立输出的方式。其流程结构如下图所示:
![]()
Wav2Lip 主要包括三个核心模块:Speech Encoder、Identity Encoder 和 Face Decoder。对于一段待驱动口唇的视频,首先提取其中的音频并进行切片处理,使得每个音频片段能够与具体的视频帧对应起来。将这些音频片段转换成梅尔频谱,并输入到 Speech Encoder 中以获取音频特征。同时,遮住待驱动帧的下半部分图像,并随机选择一帧作为参考图。这两张图片通过通道拼接的方式输入到 Identity Encoder 中,提取出图像特征。接下来,将得到的音频特征和图像特征进行拼接并传递给 Face Decoder,最终生成具有唇形变化的一帧视频。
Wav2Lip 的训练损失函数较为复杂,这是该工作的主要创新点之一。具体来说,它包含一个判别器用于评估生成图像的视觉保真度,这是一个典型的 GAN 损失项。
![]()
此外,Wav2Lip 还在像素空间中计算 L1 损失。
![]()
然而,由于口唇区域在整个脸部所占的比例很小(约 4%),重建损失对口唇部分的影响相对较小;同时,GAN 的主要目标是生成逼真的图像,而不是专注于特定细节的同步度。因此,Wav2Lip 引入了一种称为同步损失(Sync Loss)的技术,并在此基础上加入了时间约束。
![]()
具体而言,在训练过程中一次性引入了![]() 连续帧。在前向推理时,这些帧的形状为
连续帧。在前向推理时,这些帧的形状为![]() ,而在计算损失时将
,而在计算损失时将![]() 帧通过通道拼接得到一个整体输入,与对应的音频一起输入到预训练好的 SyncNet 中以计算同步度损失。实验表明,当
帧通过通道拼接得到一个整体输入,与对应的音频一起输入到预训练好的 SyncNet 中以计算同步度损失。实验表明,当![]() 时,效果明显优于单帧的同步度计算。SyncNet 是一个在 Wav2Lip 训练之前预先训练好的网络,在后续训练中不会进行更新。
时,效果明显优于单帧的同步度计算。SyncNet 是一个在 Wav2Lip 训练之前预先训练好的网络,在后续训练中不会进行更新。
基于这一 GAN 方案,Wav2Lip 能够生成唇部同步较好的视频,但在图像清晰度方面仍存在一定限制,这主要是由于其网络结构设计等因素所致。为此,近期提出了一个改进方案 MuseTalk,以进一步提升 Wav2Lip 的性能和效果。
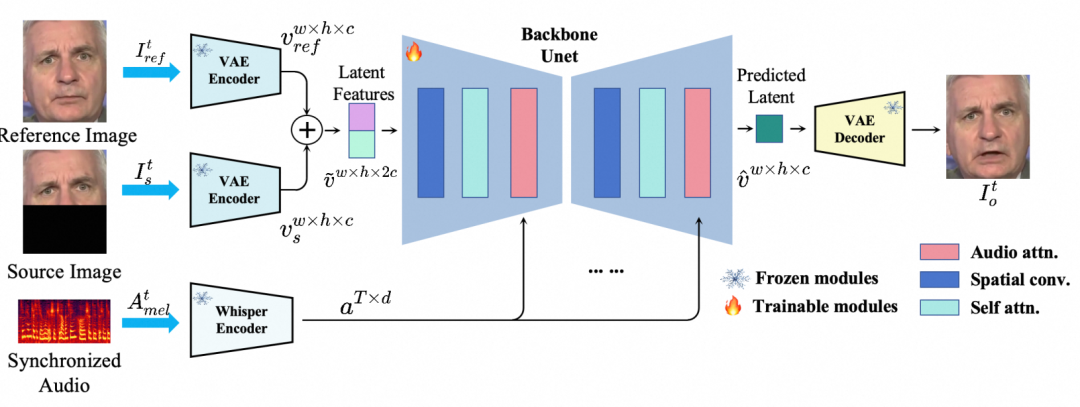
MuseTalk[2] 是腾讯于 2024 年初提出的方案,其实质是一个基于图像修复(inpainting)模型,并且不采用迭代式的扩散(Diffusion)方法,因此具备准实时性能,尽管其网络结构和信息注入参考了当前的 Diffusion 方案。MuseTalk 的架构如下图所示:
首先,将一个参考人脸图像与遮挡下半部分的目标图像通过变分自编码器(VAE)进行编码,生成潜在空间中的特征表示,并将其拼接后作为 UNet 模型的输入。对于驱动音频,在时刻![]() 对应的音频片段被提取并通过Whisper 模型进行音频特征编码。然后在不同尺度上将这些音频特征与视觉特征融合。最后,通过 VAE 解码器将融合后的特征解码回像素空间,生成一帧口型同步的说话人脸图像。这种方案不仅提高了唇部同步度,还保持了较高的图像清晰度和实时性。
对应的音频片段被提取并通过Whisper 模型进行音频特征编码。然后在不同尺度上将这些音频特征与视觉特征融合。最后,通过 VAE 解码器将融合后的特征解码回像素空间,生成一帧口型同步的说话人脸图像。这种方案不仅提高了唇部同步度,还保持了较高的图像清晰度和实时性。
MuseTalk 的目标函数设计较为复杂,与 Latent Diffusion Model 在潜空间计算 MSE loss 不同的是,MuseTalk 在像素空间中计算重建损失 ![]() ,这一点和 Wav2Lip 相同。此外,MuseTalk 使用 VGG19 作为特征提取器来计算感知(Perception)损失
,这一点和 Wav2Lip 相同。此外,MuseTalk 使用 VGG19 作为特征提取器来计算感知(Perception)损失 ![]() ,并且同步训练判别器以引入完整的 GAN 损失
,并且同步训练判别器以引入完整的 GAN 损失 ![]()
![]() 。与 Wav2Lip 类似,MuseTalk 同样使用了基于 SyncNet 打分的同步损失
。与 Wav2Lip 类似,MuseTalk 同样使用了基于 SyncNet 打分的同步损失![]() 。这些不同的损失函数在训练过程中被综合起来进行优化。
。这些不同的损失函数在训练过程中被综合起来进行优化。
![]()
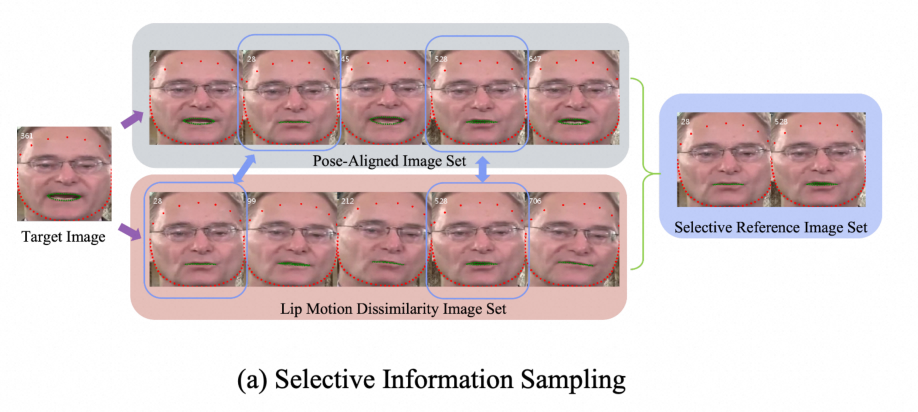
特别值得注意的是,在训练阶段引入了 Selective Information Sampling (SIS) 模块:选择头部姿态接近但口唇差异大的样本作为参考图像,从而让模型更加专注于生成高质量的口唇部分。
![]()
在实验效果方面,MuseTalk 确实优于 Wav2Lip,主要原因包括以下几个因素:
-
音频特征提取:MuseTalk 使用 Whisper 提取更高质量的音频特征,提升了口唇同步性能。
-
跨模态融合机制:MuseTalk 通过 cross-attention 融合音频和图像特征,相比简单的空间拼接方法更能捕捉到多模态信息之间的复杂关系。
-
网络结构优化:采用基于 Latent Diffusion Model (LDM) 的 UNet 网络结构,并引入了注意力层(attention layers),增强了模型在生成高质量图像时的表示能。
-
参考图片选择机制:通过 SIS 机制选择头部姿态接近但口唇差异大的样本作为参考图片,使得模型更加专注于生成高质量的口唇部分。
-
损失函数改进:引入了基于 VGG19 特征提取器计算的感知损失,进一步提升图像质量。
-
VAE 编解码:通过采用 VAE 进行编解码操作,可以实现更高质量和更高分辨率的图像生成。
▐ 头部驱动
尽管口唇同步是人物视频生成领域的一个关键研究方向,但诸如头部动作、目光和眨眼等细节特征的一致性对于生成视频的真实度同样具有重要影响。因此,业界正在积极研究完整的头部驱动技术,这些方法通常能达到更高的效果上限。
阿里通义实验室的EMO [13] 在头部驱动技术方面处于领先地位,其逼真的结果激发了一系列基于StableDiffusion方案的研究工作,但EMO本身并未开源。本文将重点介绍两种开源的头部驱动代表性作品,它们与EMO的工作流程大致相似。
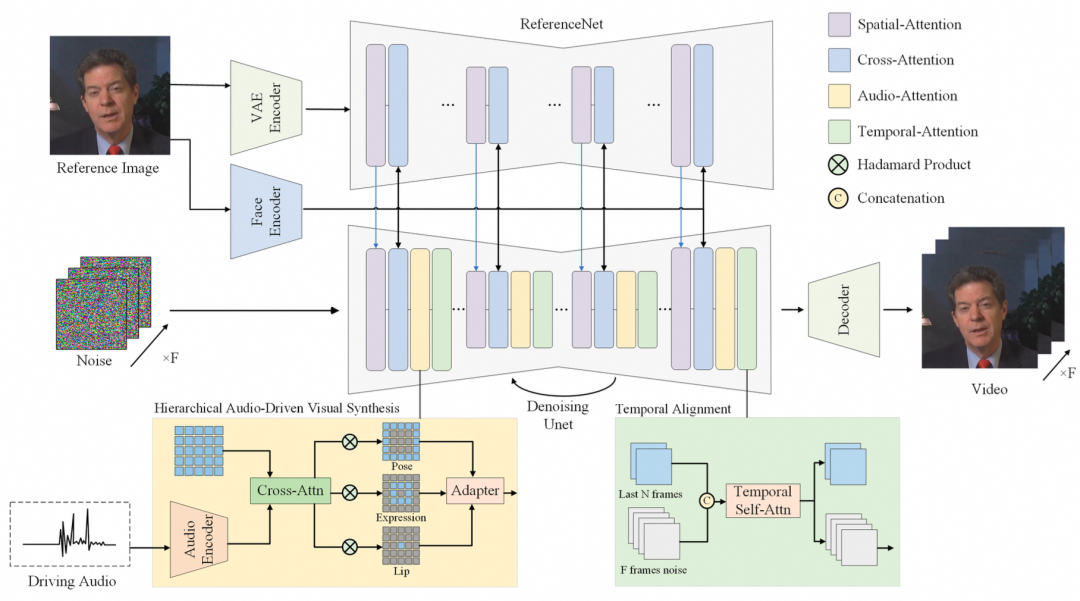
来自复旦大学的Hallo[3] 是其中一种方法,其主要流程如下图所示:
![]()
Hallo的整体流程与即将介绍的AnimateAnyone非常相似。具体而言,通过在潜在空间中随机采样噪声![]() ,并对其进行去噪处理以得到视频的潜在变量
,并对其进行去噪处理以得到视频的潜在变量![]() 。该方法主要包括以下模块:
。该方法主要包括以下模块:
-
VAE 编解码器:使得模型能够在潜在空间进行有效的去噪操作。
-
AudioEncoder(wav2vec 模型):用于编码驱动音频信号,并将其注入到DenoiseUNet中,以实现与语音同步的动画效果。
-
ReferenceNet 和 FaceEncoder 图像编码器:编码全局视觉纹理信息,从而保证角色动画的一致性和可控性。ReferenceNet 的层级特征与 DenoiseUNet 中对应的特征进行融合,以便嵌入身份信息。
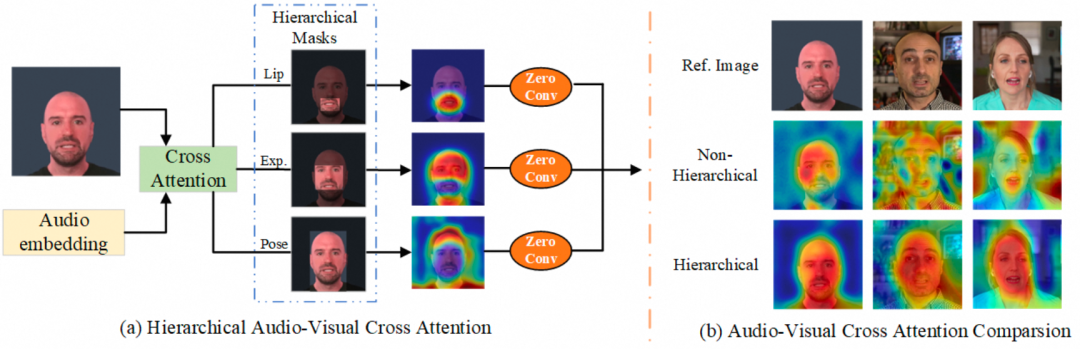
值得一提的是,Hallo引入了层级音频-视觉交叉注意力模块(Hierarchical Audio-Visual Cross Attention)来增强语音特征和特定面部位置之间的一致性,具体结构如下图所示:
![]()
对于参考帧,需要预先检测出口唇部、面部表情和姿态等区域,并分别得到对应的掩码![]() (口唇部)、
(口唇部)、![]() (面部表情)和
(面部表情)和![]() (姿态)。在将音频特征和 UNet 特征进行交叉注意力机制处理后,基于这些掩码分别提取对应区域的局部特征。随后,每个局部特征经过一个卷积层(Conv)处理,并最终融合在一起作为新的 UNet 输入特征。这种方法可以增强音频特征与 UNet 特征之间的关联性,从而提升面部驱动的效果。笔者认为,在分离和合并局部特征的过程中,能够更有效地针对特定部位进行增强和控制。
(姿态)。在将音频特征和 UNet 特征进行交叉注意力机制处理后,基于这些掩码分别提取对应区域的局部特征。随后,每个局部特征经过一个卷积层(Conv)处理,并最终融合在一起作为新的 UNet 输入特征。这种方法可以增强音频特征与 UNet 特征之间的关联性,从而提升面部驱动的效果。笔者认为,在分离和合并局部特征的过程中,能够更有效地针对特定部位进行增强和控制。
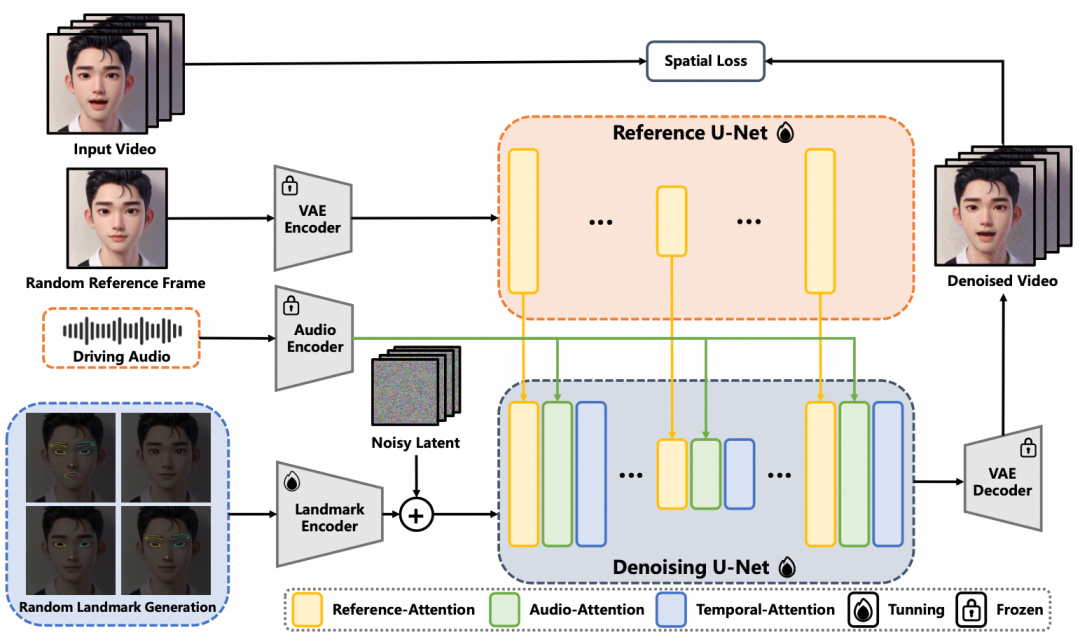
除了Hallo之外,蚂蚁集团开发的EchoMimic[4] 在网络结构上与其类似,但引入了一个关键的Landmark Encoder模块(如图所示),将人脸的关键点信息纳入模型中,从而提高了生成视频的保真度和一致性。
![]()
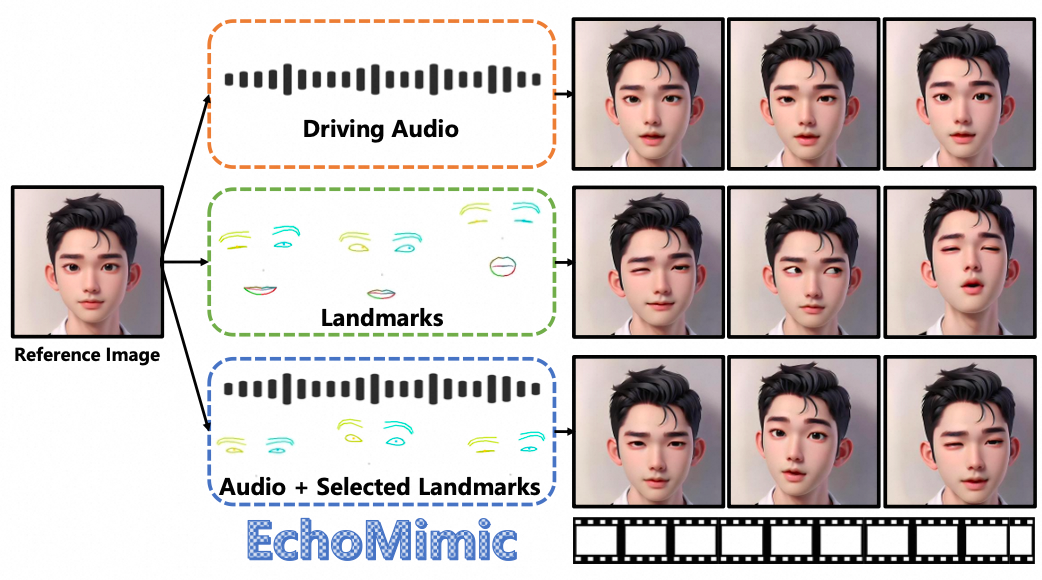
具体而言,EchoMimic在训练过程中采用随机地标选择(Random Landmark Selection,RLS)方法,即随机丢弃一些面部关键点(如下图所示),这使得推理阶段可以使用完整或部分的面部关键点。这一设计提供了额外的控制条件,使模型具备更高的灵活性,并结合了Hallo和LivePortrait的优点。
![]()
此外,在损失函数的设计上,EchoMimic 不仅在潜在空间中计算损失,还在像素空间中引入了一个损失项以捕捉面部细节信息。这种多尺度损失策略有助于提升生成视频的质量。综上所述,虽然EchoMimic的网络结构与Hallo相似,但其引入的关键点编码器和改进的损失函数使其具备了更高的灵活性和更好的性能表现。
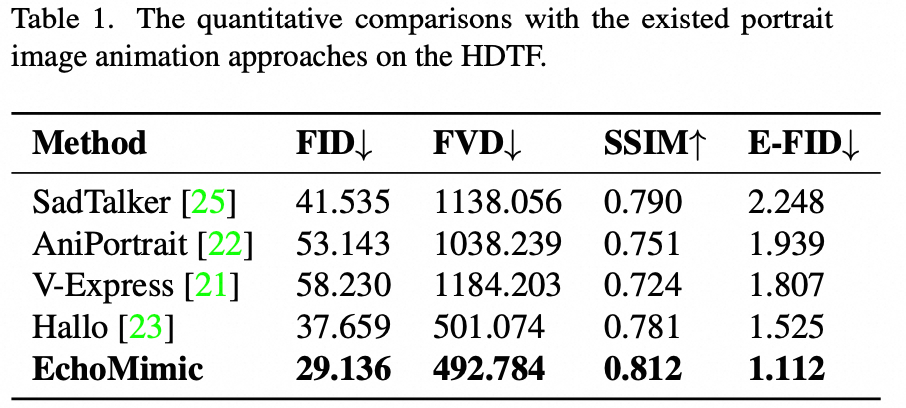
在定量指标方面,EchoMimic表现出更好的性能。这很大程度上归因于其更大的训练数据集:EchoMimic使用了540小时的数据进行训练,而Hallo仅使用了150+小时的训练数据。
![]()
除了上述工作之外,基于3D方案的头部驱动也进行了大量研究,如GeneFace[5]、GeneFace++[6] 和SyncTalk[7] 等。这些方法大多基于NeRF或Gaussian Splatting技术,并通常需要几分钟的人脸视频进行3D建模,且针对特定形象需单独训练。由于篇幅有限,本文不详细介绍这些工作。
▐ 肢体驱动
完整的人物驱动不仅依赖于口唇和头部驱动,还需要与语音一致的人体姿态,这方面的研究被称为协同语音的人物姿态视频生成(Co-Speech Video Generation)。这类方法通常可以分为两类:生成式的视频生成和检索式的视频生成。生成式的视频生成以给定的音频作为条件,直接生成所有的视频帧。这种技术可以直接合成符合语音特征的新视频内容。检索式的视频生成则利用已有的视频片段组合出新的视频,并通过插帧的方法来补足帧之间的不连续部分。这种方法通常从现有数据中选择最匹配的部分进行重组和优化。这两种方法各有优缺点,具体应用取决于需求和资源的可用性。生成式方法可以直接合成新内容,但可能需要更多的计算资源;检索式方法则可以利用现有的大量视频片段,但在插帧时可能会遇到不连续的问题。
生成式的视频生成通常包含两个步骤:speech2pose和pose2video。首先将语音映射到特定的动作序列(如3D序列或2D骨架图序列),然后再使用这些动作序列来驱动视频的生成。
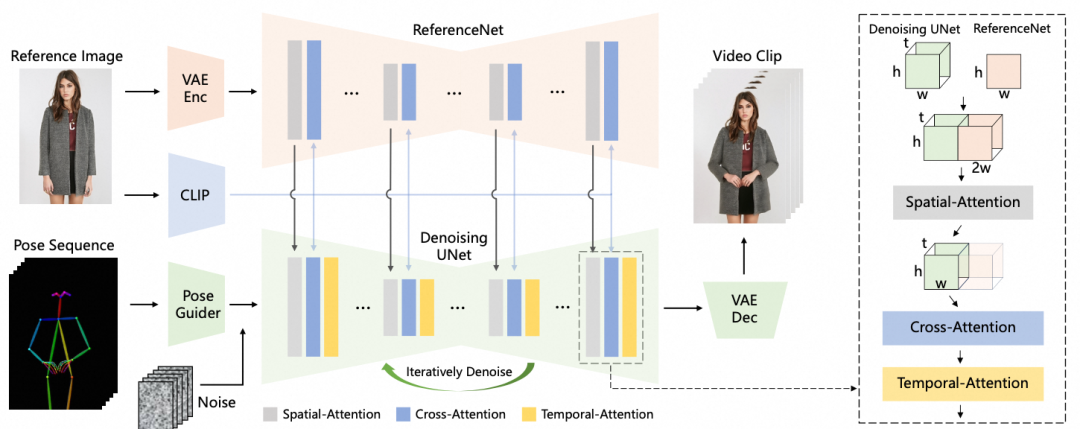
对于第一阶段的speech2pose相关工作,主要包括PantoMatrix[10] 等研究。这一领域的详细内容本文不做详细介绍,请读者查阅原始文献。近年来,在pose2video领域中最具代表性的作品之一是AnimateAnyone[8]。其流程框图如下所示:
![]()
AnimateAnyone的目标是从随机噪声![]() 中采样,并对其进行去噪处理,以得到估计的视频潜在变量
中采样,并对其进行去噪处理,以得到估计的视频潜在变量![]() 。其具体模块如下:
。其具体模块如下:
-
基于预训练的 VAE 编码器和解码器:通过预训练的变分自编码器(VAE)在潜在空间中进行去噪过程;
-
PoseGuider:将姿态特征添加到潜在空间中的噪声中,作为 DenoiseNet 的输入。这一步确保了生成的动作与语音信号的一致性。
-
ReferenceNet 和 CLIP 图像编码器:通过 ReferenceNet 保持人物外观的一致性,并引入 CLIP 图像编码器来嵌入身份信息。来自 ReferenceNet 的层级特征与 Denoising UNet 中对应的特征进行融合,以确保生成的视频帧具有稳定的视觉风格。
-
v-prediction 损失计算:通过计算 v-prediction 损失用于训练整个模型。
通过这种方式,AnimateAnyone能够有效地依据Pose序列驱动参考图生成纹理和姿态一致的视频内容。
在检索式协同语音驱动的视频生成领域中,Tango[9] 是一个典型的工作实例。Tango 生成手势视频的过程可以分为三个步骤:首先,它构建了一个有向运动图(Motion Graph),将特定的原子视频片段表示为节点,并通过有效的转场路径作为边来连接这些节点。每条采样的路径指示了选定的播放顺序。其次,在输入音频之后,使用基于跨模态相似度比较模型 AuMoCLIP 进行检索模块操作,该过程通过最小化跨模态特征距离来找到与目标音频最匹配的手势路径。最后,在原始参考视频中不存在转场边的情况下,利用基于扩散的插值模型生成外观一致的连接帧。
采样得到的路径通常包含许多跳变,因此需要使用一个插帧模型来填补缺失的帧,从而生成连贯的视频。Tango 采用了基于 AnimateAnyone 的方法来进行视频插帧。如图所示,与 AnimateAnyone 不同的是,Tango 引入了 Background Guider 模块,并修改了 Motion Module 部分。通过这些改进,Tango 能够更好地处理背景和动作细节,从而生成更自然、连贯的视频。
![]()
Background Guider 的网络结构与 PoseGuider 基本相同。作者提出 Background Guider 是因为在生成插帧时发现背景存在明显的漂移和跳变现象。通过引入参考帧和目标帧之间的单应性矩阵,计算每个像素点的偏移量(offset),并将该 offset 作为 Background Guider 的输入,从而矫正生成视频中的视角误差。
在 Motion Module 部分,核心操作是时间维度上的 self-attention。作者在此模块中引入了真实参考帧的潜在特征,在训练阶段随机引入这些特征,在推理阶段则直接使用参考特征来增强生成插帧的真实性。
![图片]()
业务流程与效果
人物视频生成技术取得了显著进展,我们尝试将其应用于淘天平台的视频营销业务场景中。具体而言,可以在营销视频中插入人物形象,以真实人物的方式向消费者介绍商品或福利,从而增强营销的可信度、拉近与消费者的距离,并提升视频的点击率(CTR),为下游承接项目提供更多的流量支持。
▐ 业务场景与流程
我们将整个业务流程划分为四个环节:素材生成与筛选、人物驱动、质量过滤和合成链路。这一完整的链路串联了组内多名同学的能力和贡献,是团队技术能力的一次综合体现。
![]()
由于需要支持多种生产线的视频生成,在素材生成与筛选阶段,我们需要集成各种类型的原始素材。具体来说:
通过基于同步语音的相似度比较等方式,筛选并构建出质量高且通用性强的人体动作模板库。为了进一步提升人物形象的多样性,我们进行了换脸和换装操作。以下详细介绍这两项技术的应用:
换脸技术已经非常成熟,流行的方法有 Roop、FaceFusion 等等。然而,我们面临的难点是如何获取丰富且无版权限制的人脸图片。起初,我们考虑使用基于扩散模型生成人脸的方案,但发现这些模型虽然可以生成较为逼真的人脸,但是这些人脸之间都非常相似,难以确保多样性。
如下图所示,我们分别使用了 Flux 和 MajicMix 模型,并结合不同的 Prompt 来生成人脸图像。然而,每一列得到的人脸图片样貌过于相似,无法保证多样性。
| flux man |
flux woman |
majicmix man |
majicmix women |
|
![]()
|
![]()
|
![]()
|
![]()
|
具体来说:使用扩散模型生成人脸虽然可以生成逼真的人脸图像,但是这些模型生成的人脸之间缺乏足够的多样性。我们尝试了即便使用不同的 Prompt,生成的图片仍然表现出高度的一致性,难以满足多样性的需求。
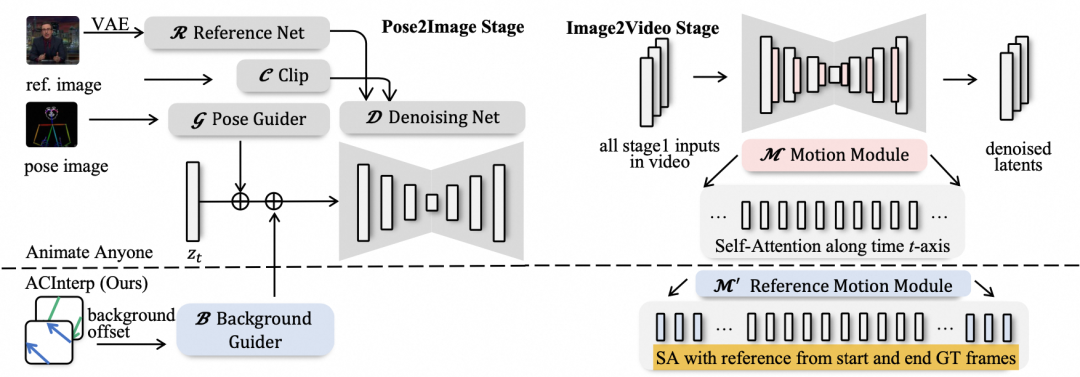
为了克服这一难题,我们专门研发了基于多参考图的、细粒度高可控的人脸局部替换技术 FuseAnyPart[11]。目前相关研究工作已经收录于 NeurIPS 24(Spotlight)中,其大致原理如下图所示:
FuseAnyPart 的基本思路是通过将不同人物的局部特征进行融合来生成新的形象。这种方法使得合成图像中的五官发生变化,与原图产生实质性差异,并且基于组合原理可以确保生成人脸的多样性。
具体步骤如下:
-
面部检测和掩码提取:首先使用一个开放集检测器识别面部图像,以获取各种面部部位(如眼睛、鼻子、嘴巴等)的掩码。
-
特征提取:接着,通过图像编码器利用这些掩码从面部图像中提取相应的局部特征。
-
基于掩码的融合模块:将提取到的面部部位特征和掩码输入到基于掩码的融合模块,在潜在空间中组合出一个完整的面部。
-
加法注入模块:整合后的特征被传送到基于加法的注入模块,以便在扩散模型的 UNet 结构中进行进一步的融合。
这种技术使得生成的人脸具有高度多样性和自然感。通过在潜在空间中的灵活组合和调整,可以创造出新的面部形象,从而有效解决人脸多样性的问题,并为人物驱动提供高质量、多样化的人脸素材。
经过 FuseAnyPart 的融合处理,可以得到清晰、自然的合成人脸图像,并且与一些基线方法相比表现出更佳的效果。
此外,FuseAnyPart 在跨种族和跨年龄样本的合成上也展示出了不错的表现,能够生成多样化的人脸图像。
FuseAnyPart 还可以进行人物与卡通形象的融合,提供更多的创意应用场景。这种灵活性不仅增加了系统的趣味性和多样性,还拓展了其在娱乐、游戏等领域的应用范围。
为了构建高质量的人脸库,在业务数据集上我们通过 FuseAnyPart 生成了一批合成人脸,并对其五官进行了调整和替换。这些经过处理的合成人脸不仅可以用于人物驱动,还可以在其他需要人脸图像的应用场景中使用,大大丰富了数据资源并提高了应用效果。
通过上述方法和技术,我们可以确保生成的人脸库既具有多样性又具备高质量和自然感。这不仅有助于提升用户体验,还为各种应用场景提供了丰富的素材支持。
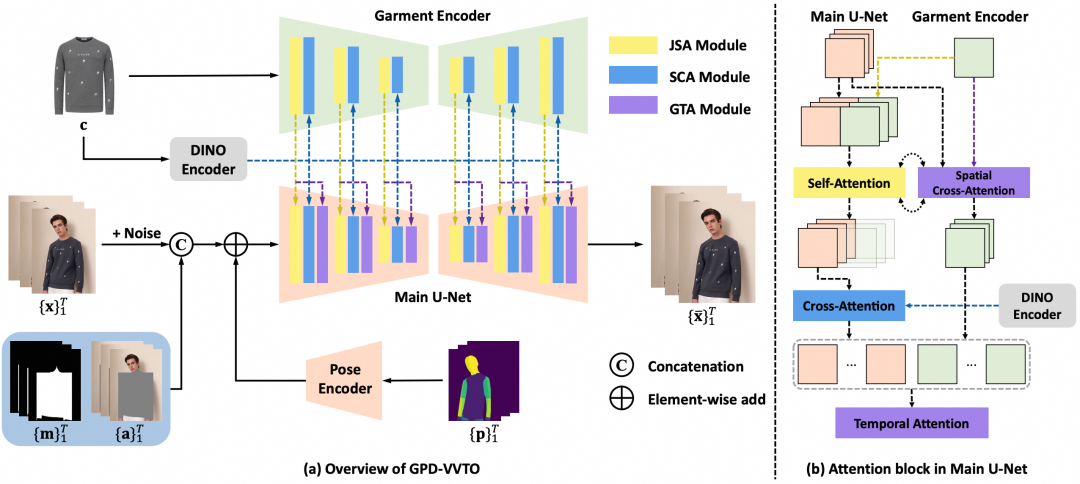
为了进一步提升人物的多样性,除了进行换脸之外,还开发了一种视频级的换衣技术,并应用了组内研发的 GPD-VVTO[12] 方案,目前该工作已经收录于 ACMMM24。该方案能够在视频上实现细节丰富、时序一致的换衣效果,为人物提供了更多的创意和应用场景。
![]()
GPD-VVTO架构主要由一个UNet骨干网络构成。该网络以视频噪声潜在表示、无服装视频潜在表示和二值遮罩序列作为输入,同时整合了DensePose序列的姿态信息。通过服装编码器和DINO编码器分别提取服装的局部纹理和全局语义特征,并通过JSA、SCA和GTA三个注意力模块将这些特征注入主网络,以实现服装细节的精确迁移。
采用 GPD-VVTO 方案,构建了数百个换衣后的视频动作模板。这些模板支持下游人物视频业务中的各种应用场景,如服装定制、角色扮演等。
通过这一方案的应用,不仅提升了人物形象在视觉上的多样性,还增强了其在娱乐和商业应用中的吸引力和互动性。这为用户提供了一种全新的体验方式,使人物视频更加生动和真实。GPD-VVTO 方案在视频级换衣技术中展现出了卓越的能力,能够生成高质量、自然且一致的换衣效果。这对于提升人物视频的多样性和用户体验具有重要意义,并为进一步拓展其应用领域奠定了坚实基础。
![图片]()
目前,在产品效果方面,我们设计了多种样式以增强含人物的营销视频的多样化,在素材外投业务中进行了初步尝试,结果显示引入人物显著提升了视频的点击率。为期两周的线上测试表明,通过添加二次创作的人物视频都能够有效吸引观众的注意力,并提高用户的互动和参与度。鉴于这些积极的结果,相关量产方案正在设计当中,以期在未来更大范围内推广和应用人物视频生成技术,从而实现更广泛的商业价值。
![图片]()
[1] Prajwal K R, Mukhopadhyay R, Namboodiri V P, et al. A lip sync expert is all you need for speech to lip generation in the wild[C]//Proceedings of the 28th ACM international conference on multimedia. 2020: 484-492.
[2] Zhang Y, Liu M, Chen Z, et al. MuseTalk: Real-Time High Quality Lip Synchronization with Latent Space Inpainting[J]. arxiv preprint arxiv:2410.10122, 2024.
[3] Xu M, Li H, Su Q, et al. Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation[J]. arxiv preprint arxiv:2406.08801, 2024.
[4] Chen Z, Cao J, Chen Z, et al. Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions[J]. arxiv preprint arxiv:2407.08136, 2024.
[5] Ye Z, Jiang Z, Ren Y, et al. Geneface: Generalized and high-fidelity audio-driven 3d talking face synthesis[J]. arxiv preprint arxiv:2301.13430, 2023.
[6] Ye Z, He J, Jiang Z, et al. Geneface++: Generalized and stable real-time audio-driven 3d talking face generation[J]. arxiv preprint arxiv:2305.00787, 2023.
[7] Peng Z, Hu W, Shi Y, et al. Synctalk: The devil is in the synchronization for talking head synthesis[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 666-676.
[8] Hu L. Animate anyone: Consistent and controllable image-to-video synthesis for character animation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 8153-8163.
[9] Liu H, Yang X, Akiyama T, et al. TANGO: Co-Speech Gesture Video Reenactment with Hierarchical Audio Motion Embedding and Diffusion Interpolation[J]. arxiv preprint arxiv:2410.04221, 2024.
[10] Liu H, Zhu Z, Becherini G, et al. EMAGE: Towards Unified Holistic Co-Speech Gesture Generation via Expressive Masked Audio Gesture Modeling[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 1144-1154.
[11] Yu Z, Wang Y, Cui S, et al. FuseAnyPart: Diffusion-Driven Facial Parts Swap via Multiple Reference Images[J]. Advances in Neural Information Processing Systems (NeurIPS), 2024.
[12] Wang Y, Dai W, Chan L, et al. GPD-VVTO: Preserving Garment Details in Video Virtual Try-On[C]//Proceedings of the 32nd ACM International Conference on Multimedia. 2024: 7133-7142.
[13] Tian L, Wang Q, Zhang B, et al. Emo: Emote portrait alive-generating expressive portrait videos with audio2video diffusion model under weak conditions[J]. arxiv preprint arxiv:2402.17485, 2024.
![图片]()
我们是淘宝业务技术内容AI团队-视频生成组,专注于服饰时尚领域,持续迭代服饰上身视频生成基础模型和下游服饰应用模型效果,并持续完善 FashionVideoGen 服饰视频产品化解决方案,面向商家和内容场域,做更灵活可控和多样化的视频生成产品化能力,让AIGC技术充分发挥业务价值。欢迎关注。