Release Notes
- 1、【提升】爬虫JS渲染能力强化:升级提供 "Selenium + ChromeDriver" 方案支持JS渲染,兼容性更高,废弃旧Phantomjs方案。非JS渲染场景仍然Jsoup,速度更快。同时支持自由扩展其他实现。
- 2、【优化】进一步优化 Selenium 兼容问题,完善JS渲染场景下兼容性和性能。
- 3、【重构】重构核心功能模块,提升扩展性;修复历史代码隐藏问题,提升系统稳定习惯。
- 4、【升级】多个依赖升级至更新版本,如jsoup、selenium等。
引入Maven依赖
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-crawler</artifactId>
<version>${最新稳定版}</version>
</dependency>
代码示例
注意:仅供学习测试使用,如有侵犯请联系删除
提示:更多测试代码可以前往仓库查看:测试代码目录
- 爬虫名称:Gitee高星项目采集爬虫
- 爬虫功能:一行代码启动多线程爬虫,分页方式扩散爬取“Gitee开源项目列表”,通过“注解式”自动提取页面数据,封装成PageVo输出;
XxlCrawler crawler = new XxlCrawler.Builder()
.setUrls("https://gitee.com/explore/all?order=starred&page=1") // 设置爬虫入口URL
.setAllowSpread(true) // 允许爬虫扩散
.setWhiteUrlRegexs("^https:\\/\\/gitee\\.com\\/explore\\/all\\?order=starred&page=[1-5]$") // 设置爬虫扩散的URL白名单正则表达式,控制扩散范围
.setThreadCount(3) // 设置爬虫线程池大小
.setPauseMillis(100) // 设置爬虫每次抓取间隔时间,避免对下游压力过大
.setPageParser(new PageParser<GiteeProjectPageVo>() {
@Override
public void afterParse(Response<GiteeProjectPageVo> response) {
/**
* 获取爬虫结果数据:afterParse 会在多线程爬虫运行过程中实时输出爬虫结果数据,避免结尾一次性反馈造成大对象问题;可实时消费处理数据,如存储在DB等。
*/
if (response.getParseVoList() != null) {
for (GiteeProjectPageVo pageVo: response.getParseVoList()) {
logger.info("response.getHtml().baseUri()={}, PageDataVo={}", response.getHtml().baseUri(), pageVo);
}
}
}
})
.build();
crawler.start(true);
简介
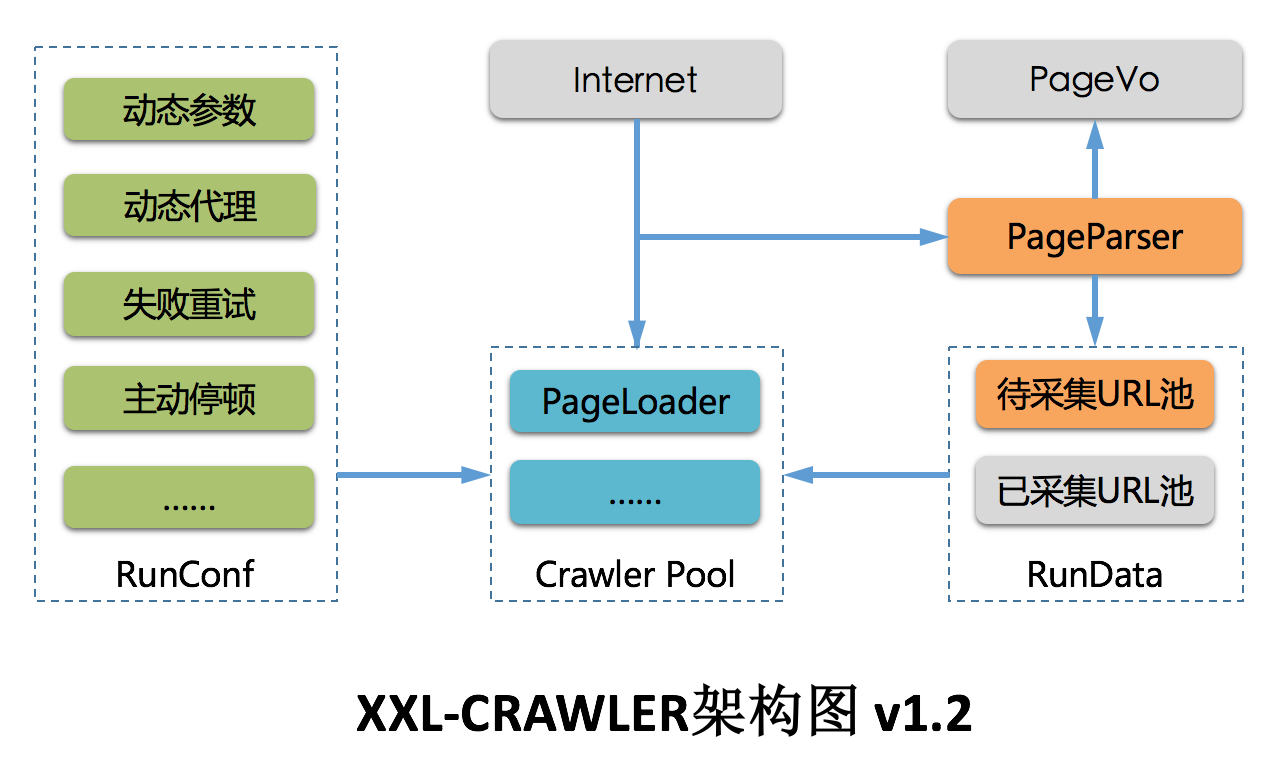
XXL-CRAWLER 是一个轻量级Java爬虫框架。一行代码开发一个多线程爬虫,全注解方式采集页面数据至Java对象,拥有"多线程、全注解、JS渲染、代理、分布式扩展"等特性;
项目资料
特性
- 1、简洁:API直观简洁,可快速上手;
- 2、轻量级:底层实现仅强依赖jsoup,简洁高效;
- 3、模块化:模块化的结构设计,可轻松扩展;
- 4、全注解:支持通过注解提取页面数据,高效映射页面数据到PageVO对象,底层自动完成PageVO对象的数据抽取和封装返回;单个页面支持抽取一个或多个PageVO;
- 5、多线程:线程池方式运行,提高采集效率;
- 6、扩散全站:支持以现有URL为起点扩散爬取整站;
- 7、JS渲染:通过扩展 "PageLoader" 模块,支持采集JS动态渲染数据。原生提供 Jsoup(非JS渲染,速度更快)、Selenium+ChromeDriver(JS渲染,兼容性高) 等多种实现,支持自由扩展其他实现;
- 8、代理IP:对抗反采集策略规则WAF;
- 9、动态代理:支持运行时动态调整代理池,以及自定义代理池路由策略;
- 10、失败重试:请求失败后重试,并支持设置重试次数;
- 11、异步:支持同步、异步两种方式运行;
- 12、幂等去重:防止重复爬取;
- 13、URL扩散过滤:支持设置页面白名单正则,过滤URL;
- 14、分布式支持:通过扩展 "RunUrlPool" 模块,并结合Redis或DB共享运行数据可实现分布式。默认提供LocalRunUrlPool单机版爬虫;
- 15、自定义请求信息,如:请求参数、Cookie、Header、UserAgent轮询、Referrer等;
- 16、动态参数:支持运行时动态调整请求参数;
- 17、超时控制:支持设置爬虫请求的超时时间;
- 18、主动停顿:爬虫线程处理完页面之后进行主动停顿,避免过于频繁被拦截;