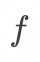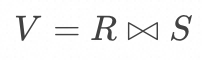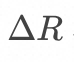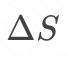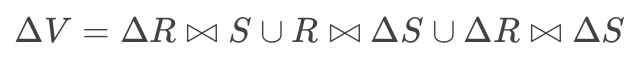自"三驾马车"伊始, 大数据处理技术已经发展了二十年。在前十年中, Hive+Spark 这套离线处理技术就已经基本完善; 近十年来, Flink的快速发展又有效地解决了实时处理的问题。然而, 低成本的近实时处理依然面临挑战。近来, 随着业界对近实时处理及流批一体架构的需求愈发强烈, 增量计算开始重新被关注。Flink在1.20中推出了 Materialized Table(MT) 来统一流批两种模式的处理, 配合Paimon已有的Changelog存储能力, 开源低成本增量计算的曙光已至。
本文首先介绍增量计算相关的概念, 随后结合 Flink 和 Paimon 两个引擎通过具体案例来介绍当前开源引擎增量计算的能力。从中我们可以得出当前的增量计算还有哪些不足, 亦可窥视其未来发展方向。
增量计算在数据库领域早有研究, 在数据库领域称为Incremental View Maintenance(IVM), 其核心是为了降低基础数据变化时, 更新物化视图的成本, PostgreSQL对此也有实现。而大数据处理领域一向是大力出奇迹, 为什么近来也开始关注增量计算呢? 笔者认为有两个核心原因:
-
一是对流批一体架构的追求, 流批一体的口号业界已经喊了多年, 但是实际落地的场景并不多。即使像Flink这类支持流批两种处理模式的引擎, 不同处理模式下的代码也难以共用。笔者认为其核心原因是底层计算模型没有统一, 批处理是全量计算模型, 而Flink的流处理是基于Changelog的增量计算模型。不同计算模型下, 对输入和输出的要求不通, 就难以做到流批完全一致。
-
另一个原因是对成本和数据新鲜度的权衡。目前的批处理通过调度 + 全量计算的模式能够做到很低的计算成本, 但延迟在理想情况下也是T+1; 流处理通过Long Running + 增量计算的模式能够做到很低的计算延迟, 但 Long Running 的计算作业带来了极大的运维和资源成本。这几乎是两个极端, 在近实时场景下, 想要牺牲一定的延迟(从流处理的秒级到分钟级), 来降低成本几乎不可能。
目前来看, 增量计算是能够解决上述两个问题的。从计算模型上来看, 全量计算是增量计算的一个特例, 能够统一成增量计算。从成本和数据新鲜度方面, 增量计算能够通过调整计算频率来平衡延迟和成本。
这里需要注意的是, Flink的计算模式是基于Changelog的增量计算, 它是增量计算的一种实现方式, 它把变更作为状态记录在引擎内部, 理论上要保证计算结果准确, 状态是需要永久保存的。在实操中之所以能给状态设定一个TTL, 是因为存在一种隐含的假设, 增量数据产生的回撤操作不会影响那个TTL之前的历史结果。Flink默认是逐条数据处理的, 在Mini-Batch模式下可以攒小批, 适合低延迟的计算, 但由于Long Runing作业的存在其成本还是较高,要实现低成本的增量计算显然要另寻方法。
![]()
增量计算的模型
全量计算中, 每一次的计算结果只与本次输入有关, 而且是幂等的. 增量计算中, 每一批次的计算结果, 是由本批数据和历史数据结合计算出来的, 即![]()
从以上公式上来看, 实现增量计算有两个要点:
一是要捕获增量变更, 即![]() ;
;
二是如何基于增量变更进行增量计算, 即如何实现函数![]()
目前来看, 数据库领域和大数据处理领域采用了不太一样的实现方案:
数据库领域, 在增量数据捕获上通常会基于其内部机制记录变更数据, 例如PostgreSQL 基于 AFTER触发器 和 Transition Table 来捕获增量数据; 在增量计算上, 通过查询改写来实现增量计算, 例如一个 Inner Join![]() ,若能够捕获关系 R 和 S 的变更
,若能够捕获关系 R 和 S 的变更![]() 和
和![]() , 那么其增量可改写为:
, 那么其增量可改写为:
![]()
在大数据处理领域, 在增量数据捕获上会基于通用的 Changelog 模型, 例如Paimon的 Changelog Producer。在计算上, 使用通用的 Changelog 模型就可以大力出奇迹了, 引擎不需要为每个处理操作制定特有的增量算法, 只需按常规方式实现并考虑数据的 Changelog 类型即可。
![]()
增量计算的实现形式
上文我们说到数据库领域和大数据处理领域在增量计算的实现上有所不同, 数据库领域多倾向于通过算法进行查询改写来实现, 虽然可以更加精细化, 但是难度大没有统一的模型, 因此本文不作详细介绍。这里我们重点介绍一下大数据处理领域增量计算的实现形式。
目前最为成熟的是流处理引擎中基于 Changelog+ 状态的增量计算, Flink就是其中的代表。这种基于内置状态的增量计算的好处是可以逐条记录处理, 从而达到最低延迟。但也面临两个问题: 首先是回撤带来大量无用计算, 回撤意味着随着数据的增量变化, 之前的计算结果是无效的, 需要删除并重新更新结果。实践上, 很多场景下不会需要每新增一条数据就计算一次结果, 因此可以通过攒批来减少回撤, Flink也实现了Mini-Batch Aggregate和Mini-Batch Join来减少回撤。但这仍无法解决在超长时间跨度回撤的场景下, 要保证计算结果准确, 状态TTL必须无穷的问题。
上述模式最大的问题是状态TTL无穷。状态本质上是截止当前所有增量数据计算的结果, 设想如果我们去掉状态就无法将增量结果与历史结果合并, 从而得到新的计算结果。但是换一种思路, 我们并不一定要输出合并后的计算结果, 而是可以输出增量计算结果(当然增量结果也需要符合Changelog格式), 在查询时再对多个增量结果进行合并, 从而得到最终结果。这种模式就是目前流处理引擎 + 数据湖的增量计算, 与上述模式不同的是流处理引擎不再需要无穷状态, 只计算并输出增量结果到数据湖(要求数据湖支持Changelog存储), 结果的合并由数据湖进行, 可以选择写时合并或读时合并。并且通过攒批可以减少回撤, 从而降低合并时的压力。目前Paimon提供了多种类型的Merge Engine, 可以减少或消除Flink状态。
上述模式尽管解决了状态问题, 但是仍需要一个Long Running的流处理作业。并且可以发现, 数据湖的写是通过基于Checkpoint的两阶段提交来保证一致性的, 那数据可见性延迟实际上就是Checkpoint的时间间隔。既然如此, 为了进一步降低成本, 我们可以去掉这个Long Running的流处理作业, 使用低延迟调度的批处理作业作为替代, 只要保证批处理作业的调度时间间隔与流处理作业Checkpoint的时间间隔一致, 就能保证一致的数据可见性延迟。
由于批处理引擎每次只处理增量数据, 把延迟降低到分钟级是可能的。当然这种基于批处理引擎低延时调度 + 数据湖的增量计算, 要求批处理引擎也能识别和处理Chengelog数据。目前Flink在Streaming模式下能配合Paimon处理Changelog数据, 但是Batch模式下并没有Changelog的处理能力, 因此开源引擎目前尚无法实现这一模式。不过已有商业数据平台实现了类似的能力, 国外的如Snowflake的Dynamic tables, Databricks的Delta Live Tables; 国内的如MaxCompute的Delta Table, 云器科技的 Dynamic Table...
![]()
增量计算示例
上文介绍了增量计算的理论, 目前开源系统中, 增量计算实现最完善的是Flink + Paimon这套组合, 这里以这两个系统为例通过一个具体案例, 来更直观地展示增量计算的效果,主要涉及两个系统的以下几个特性:
-
Flink对处理Changelog数据的支持以及1.20新增的Materialized Table特性。由于Paimon也是从Flink衍生, 其Changelog存储的实现在原理上也与Flink类似, 因此理解Flink的Changelog原理是关键, 具体可参考《Flink SQL源码 - Changelog 原理与实现》。
-
Paimon的Merge Engine能力以及Changelog Producer。
不使用Flink MT语法实际上也能配合Paimon实现上述第二种模式的增量计算, 不过Paimon将会支持Flink MT, 并且MT语法提供了更好的封装方便链路开发。这里给出一个Flink MT + Paimon的尝鲜案例。这一案例统计各个物流公司的运单数量, 但是由于各种原因某个订单的物流公司可以从A变成B。
SET 'sql-client.execution.result-mode' = 'tableau';SET 'table.exec.sink.upsert-materialize' = 'NONE';SET 'execution.runtime-mode' = 'streaming';
CREATE CATALOG paimon WITH ( 'type'='paimon', 'warehouse'='file:/tmp/paimon');
CREATE TABLE tms_source ( order_id STRING PRIMARY KEY NOT ENFORCED, tms_company STRING NOT NULL) WITH ( 'connector' = 'paimon', 'path' = 'file:/tmp/paimon/default.db/tms_source', 'changelog-producer' = 'lookup', 'scan.remove-normalize' = 'true');
CREATE MATERIALIZED TABLE continues_tms_res(CONSTRAINT `pk_tms_company` PRIMARY KEY (tms_company) NOT ENFORCED)WITH ( 'format' = 'debezium-json', 'scan.remove-normalize' = 'true', 'changelog-producer' = 'lookup', 'merge-engine' = 'aggregation', 'fields.order_cnt.aggregate-function' = 'sum')FRESHNESS = INTERVAL '30' SECONDAS SELECT tms_company, 1 AS order_cntFROM tms_source;
INSERT INTO tms_source VALUES ('001', 'ZhongTong');INSERT INTO tms_source VALUES ('002', 'ZhongTong');INSERT INTO tms_source VALUES ('001', 'YuanTong');
如果在向源表插入数据的过程中观察tms_source和continues_tms_res, 我们可以得到如下结果。由于两个表都启动了Changelog Producer, 因此表中会记录所有的Changelog记录(+I, -U, +U, -D)。这里需要说明的是, 以下结果是在每条记录的插入时间间隔超过30s时得到的, 如果三条记录在一个 Checkpoint 批次内插入, 那由于攒批操作, 回撤操作将被消除。
Flink SQL> SELECT * FROM tms_source;+----+--------------------------------+--------------------------------+| op | order_id | tms_company |+----+--------------------------------+--------------------------------+| +I | 001 | ZhongTong || +I | 002 | ZhongTong || -U | 001 | ZhongTong || +U | 001 | YuanTong |
Flink SQL> SELCT * FROM continues_tms_res;+----+--------------------------------+-------------+| op | tms_company | order_cnt |+----+--------------------------------+-------------+| +I | ZhongTong | 1 || -U | ZhongTong | 1 || +U | ZhongTong | 2 || +I | YuanTong | 1 || -U | ZhongTong | 2 || +U | ZhongTong | 1 |
最终查询两个表的最终状态, 可以得到如下结果, Changelog 中间结果(增量计算结果)将在读时被合并。
Flink SQL> SELECT * FROM tms_source;+----+--------------------------------+--------------------------------+| op | order_id | tms_company |+----+--------------------------------+--------------------------------+| +I | 001 | YuanTong || +I | 002 | ZhongTong |
Flink SQL> SELECT * FROM continues_tms_res;+----+--------------------------------+-------------+| op | tms_company | order_cnt |+----+--------------------------------+-------------+| +I | YuanTong | 1 || +I | ZhongTong | 1 |
continues_tms_res这个 Materialized Table 背后其实是有一个 Long Running 的 Flink 作业, 在实现上 SQL Gateway 会将 Materialized Table 语法解析为一个普通的 INSERT INTO 语句并提交给 Flink 集群, 它的作业图如下, 可以看到整个作业中是不存在状态算子的,但是我们最终实现了增量的聚合计算。
![]()
以上示例运行在Flink的Streaming模式下, 由于目前Flink Batch模式并不支持基于Changelog数据的计算, 因此Flink MT + Paimon的组合目前还无法实现调度+批处理模式的增量计算。不过受益于流处理模式下已有的经验, 相信Flink是最有可能成为补足这一能力的批处理引擎。
本文介绍了大数据处理中的增量计算技术, 目前看来不管是开源还是商业化引擎, 都在不断补足这一部分能力。通过目前趋势来看, 个人认同的一个观点是: 基于批处理引擎低延时调度 + 增量计算的方式将是未来真正能够实现流批一体的架构, 并且能在分钟级延迟的数据新鲜度下保持较低的成本。不过这套架构难以解决纯实时的场景。因此最终离线和近实时处理是能够在存储和计算上都做到流批一体的, 但是纯实时领域还是需要另外一套架构。
![]()
参考资料
[1] FLIP-435: Introduce a New Materialized Table for Simplifying Data Pipelines:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-435%3A+Introduce+a+New+Materialized+Table+for+Simplifying+Data+Pipelines
[2] [DISCUSS] FLIP-435: Introduce a New Dynamic Table for Simplifying Data Pipelines:
https://lists.apache.org/thread/c1gnn3bvbfs8v1trlf975t327s4rsffs
[3] Incremental View Maintenance:
https://wiki.postgresql.org/wiki/Incremental_View_Maintenance
[4] 《离线数仓近实时化的成本问题--- 增量数仓系列其一》:
https://zhuanlan.zhihu.com/p/659048818
[5] 《是时候准备结束数仓领域流批一体的讨论了---增量数仓系列其二》:
https://zhuanlan.zhihu.com/p/688990525
[6] Incremental Database Computations:
https://www.feldera.com/blog/incremental-database-computations
[7] Tempura: a general cost-based optimizer framework for incremental data processing (Journal Version):
https://zuozhiw.github.io/tempura-journal.pdf
[8] 《云器科技-产品文档-开发动态表实现近实时增量处理》:
https://www.yunqi.tech/documents/streaming_pipeline_with_dynamic_table
[9] 《Flink SQL源码 - Changelog 原理与实现》:
https://liebing.org.cn/flink-sql-changelog.html
我们是淘天集团—终端平台团队,专注打造业界领先的终端技术以及丝滑流畅的体验,通过持续的创新突破,赋能前台业务、连接数亿用户,提供极致高可靠的服务、极致高性能的架构和极致高效率的产品。



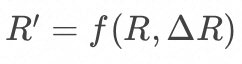
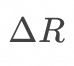 ;
;