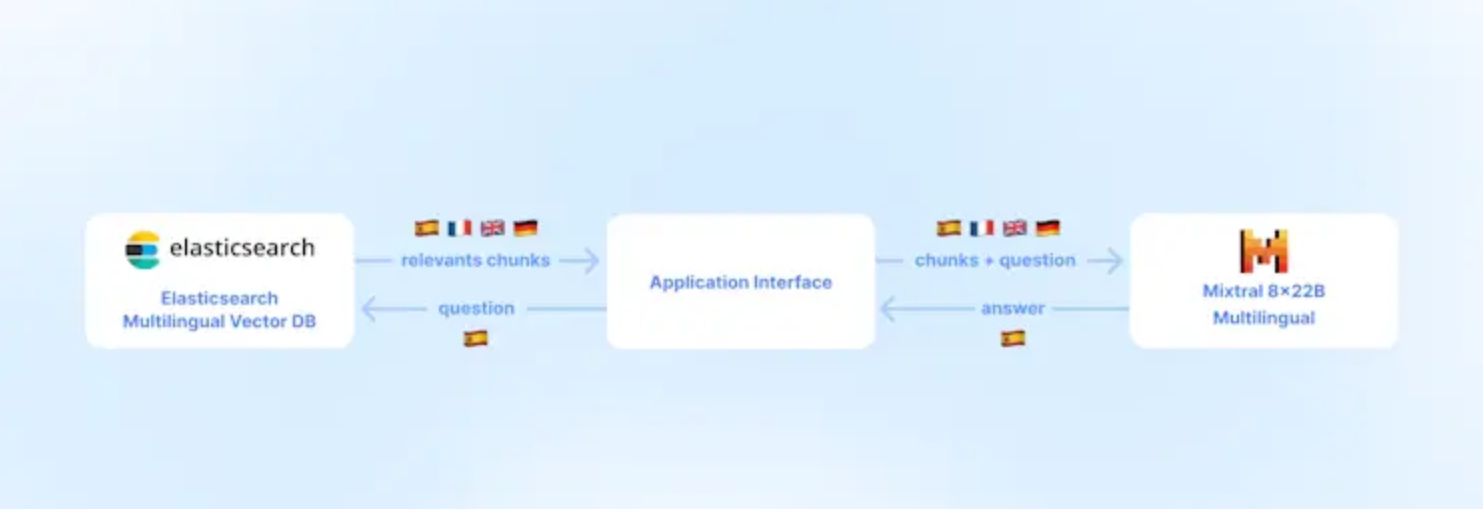
这篇文章是之前的文章 “使用 Elastic 和 Mistral 构建多语言 RAG(一)” 的续篇。在这篇文章中,我将展示如何在本地部署中完成在那篇文章中的实现。
注意:由于 semantic text 从 8.15 版本开始提供,你需要至少 8.15 及以上的版本才可以运行下面的代码。
![]()
安装
Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的链接来进行安装:
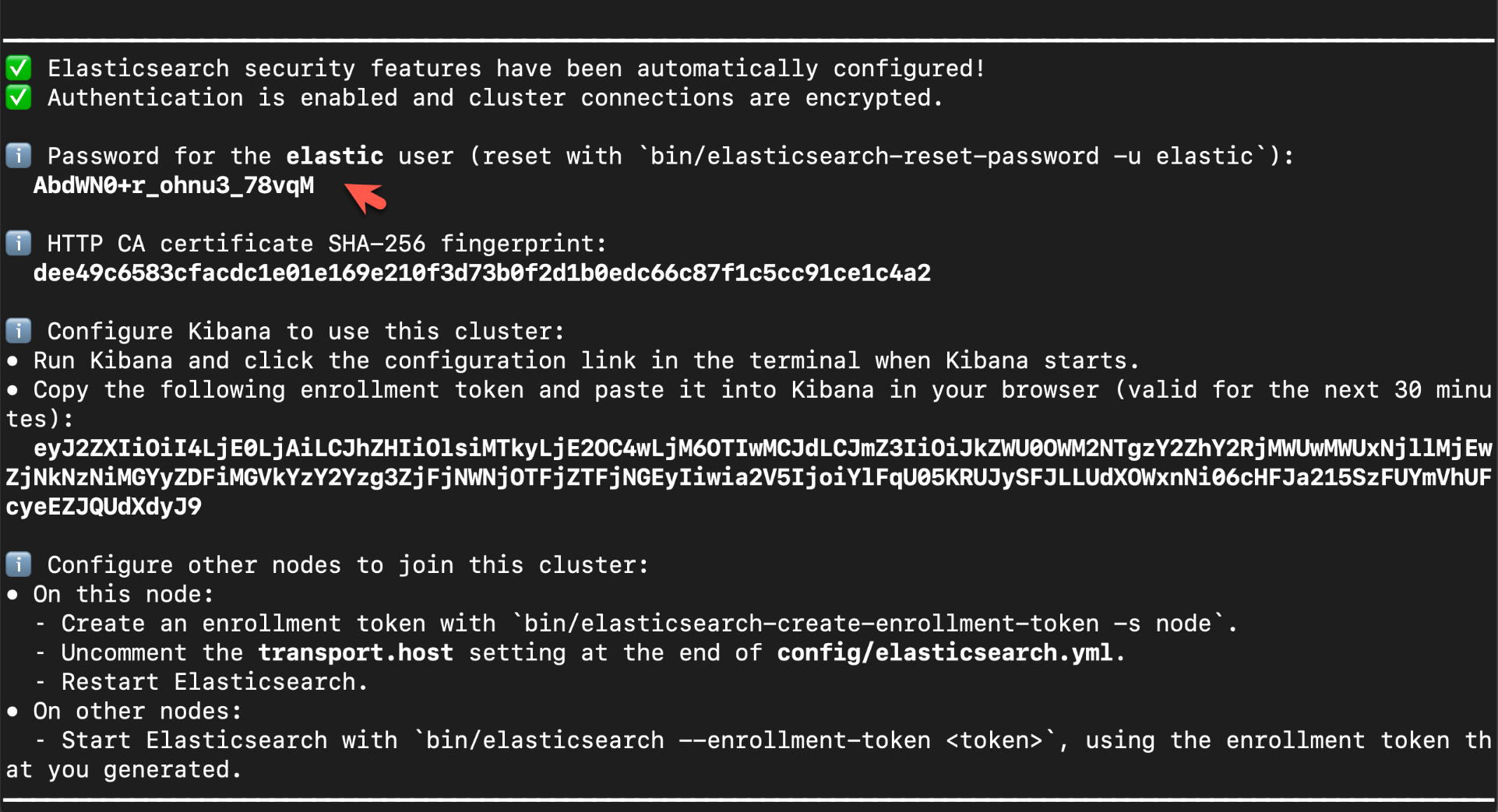
在安装的时候,我们选择 Elastic Stack 8.x 来进行安装。在首次启动 Elasticsearch 的时候,我们可以看到如下的输出:
![]()
在上面,我们可以看到 elastic 超级用户的密码。我们记下它,并将在下面的代码中进行使用。
我们还可以在安装 Elasticsearch 目录中找到 Elasticsearch 的访问证书:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.15.0/config/certs
$ ls
http.p12 http_ca.crt transport.p12
在上面,http_ca.crt 是我们需要用来访问 Elasticsearch 的证书。
我们首先克隆已经写好的代码:
git clone https://github.com/liu-xiao-guo/elasticsearch-labs
我们然后进入到该项目的根目录下:
$ pwd
/Users/liuxg/python/elasticsearch-labs/supporting-blog-content/building-multilingual-rag-with-elastic-and-mistral
$ ls
building_multilingual_rag_with_elastic_and_mistral.ipynb
如上所示,building_multilingual_rag_with_elastic_and_mistral.ipynb 就是我们今天想要工作的 notebook。
我们通过如下的命令来拷贝所需要的证书:
$ pwd
/Users/liuxg/python/elasticsearch-labs/supporting-blog-content/building-multilingual-rag-with-elastic-and-mistral
$ cp ~/elastic/elasticsearch-8.15.0/config/certs/http_ca.crt .
$ ls
building_multilingual_rag_with_elastic_and_mistral.ipynb
http_ca.crt
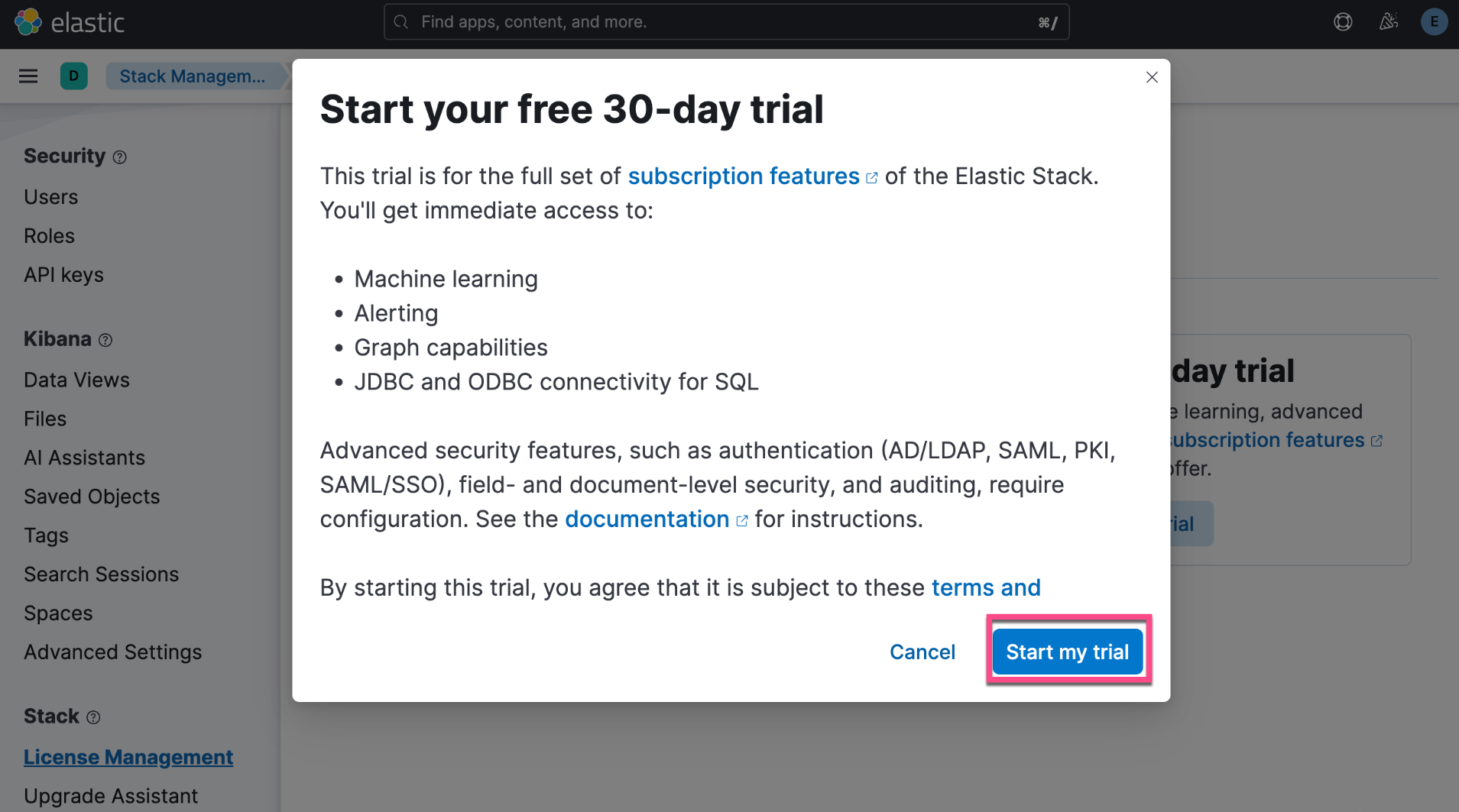
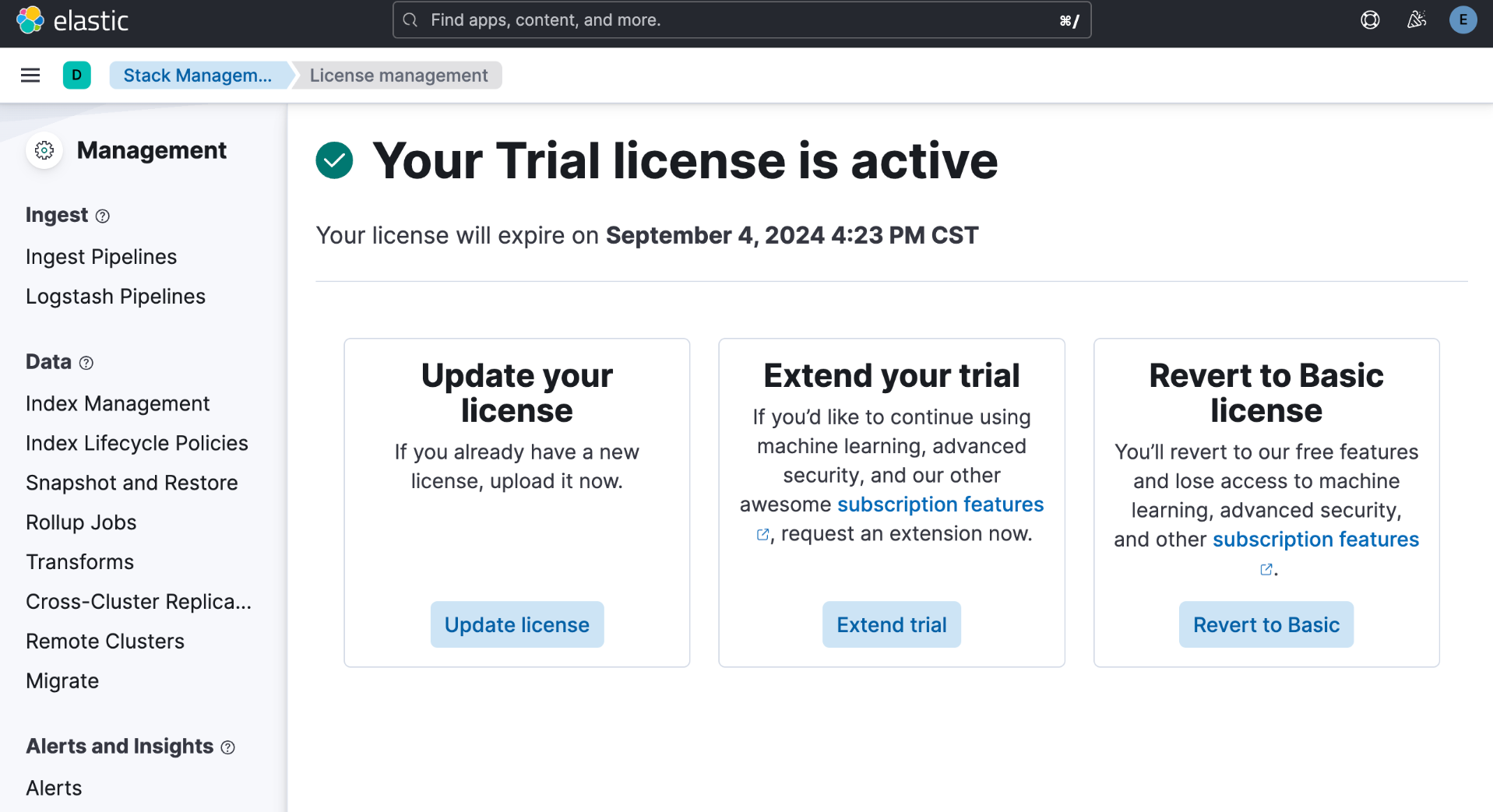
启动白金试用
我们的演示中需要使用到版权。我们按照下面的步骤来启动白金试用:
![]()
![]()
![]()
![]()
这样我们就完成了白金试用的功能。
添加 ES 模型做多语言向量化
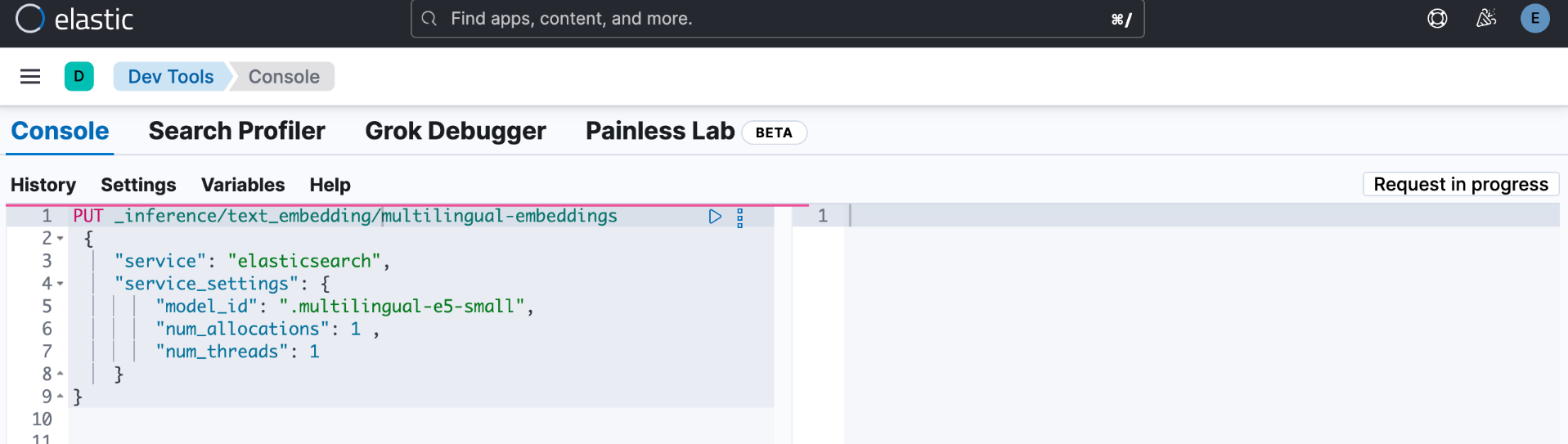
我们在 DevTools 中打入如下的命令:
PUT _inference/text_embedding/multilingual-embeddings
{
"service": "elasticsearch",
"service_settings": {
"model_id": ".multilingual-e5-small",
"num_allocations": 1 ,
"num_threads": 1
}
}
![]()
整个的过程需要一定的时间来完成。
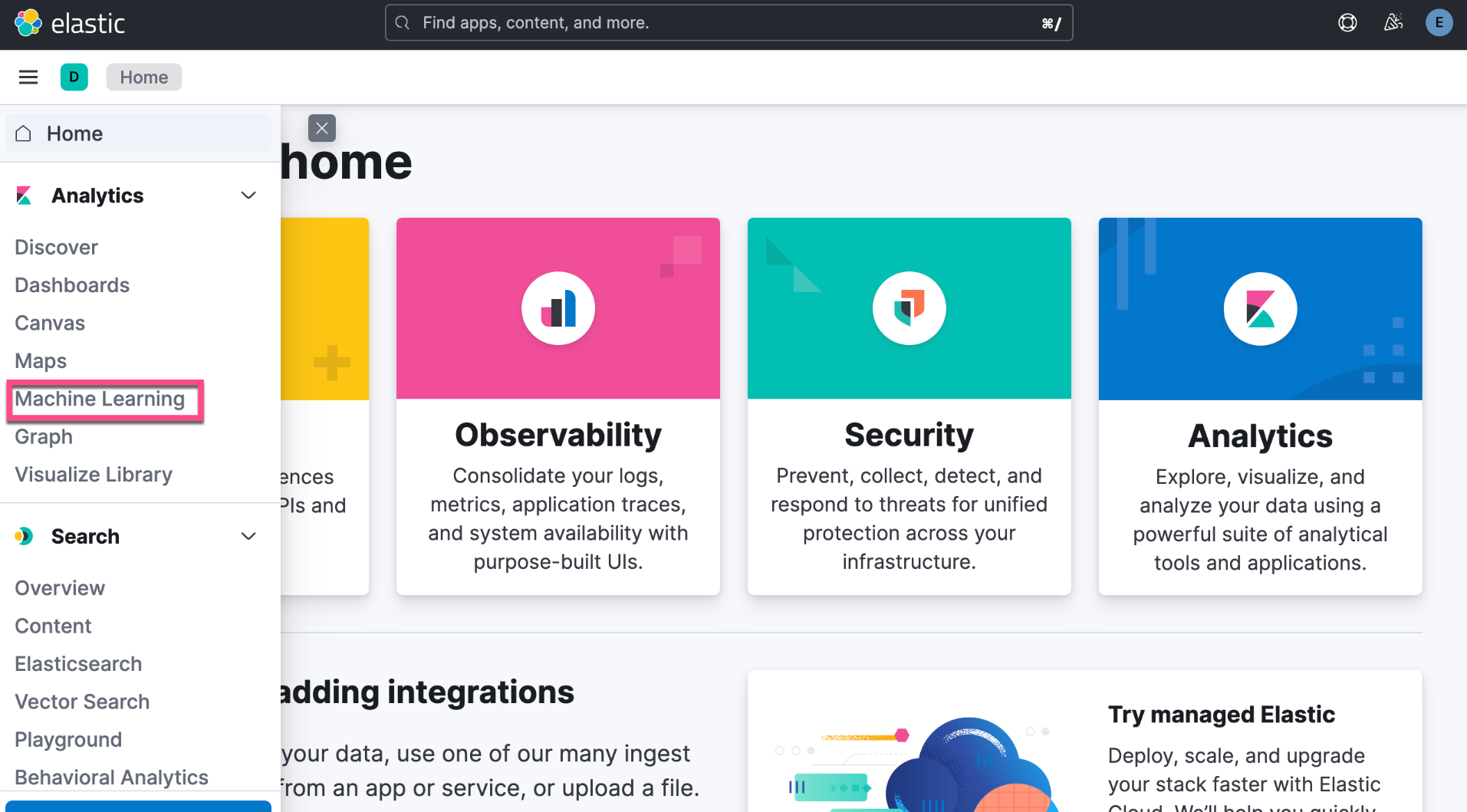
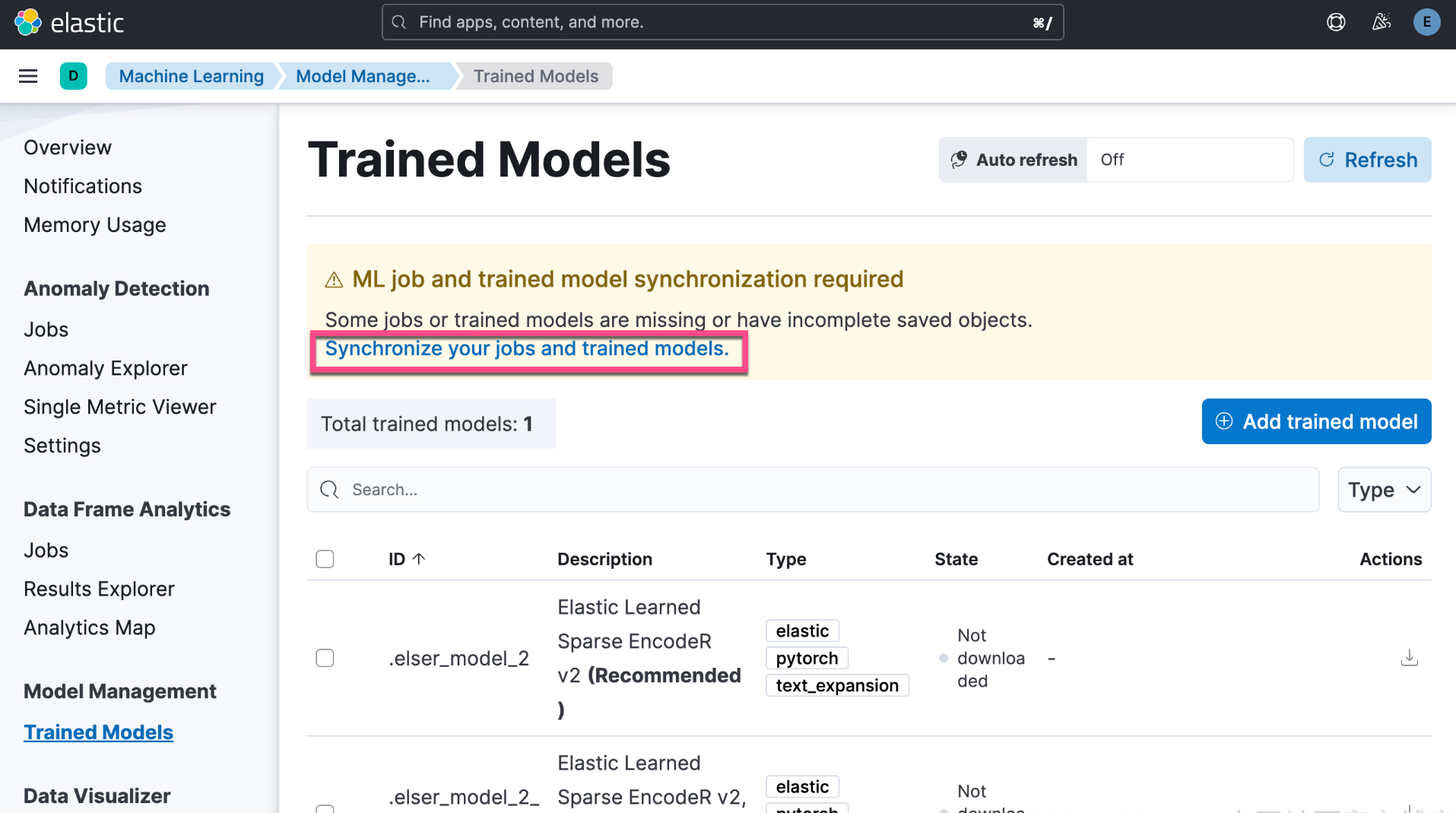
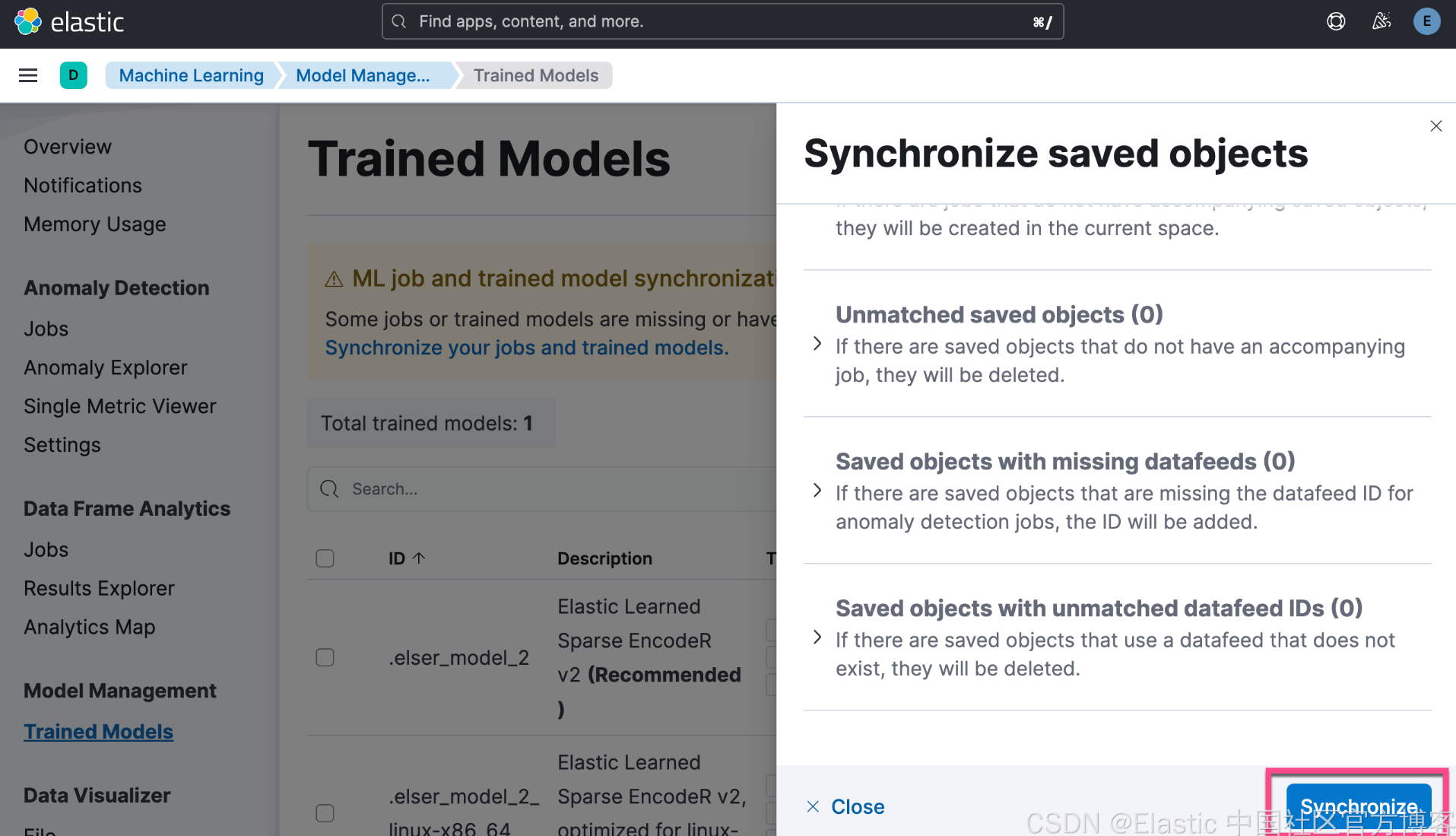
我们接下来去机器学习界面查看:
![]()
![]()
![]()
![]()
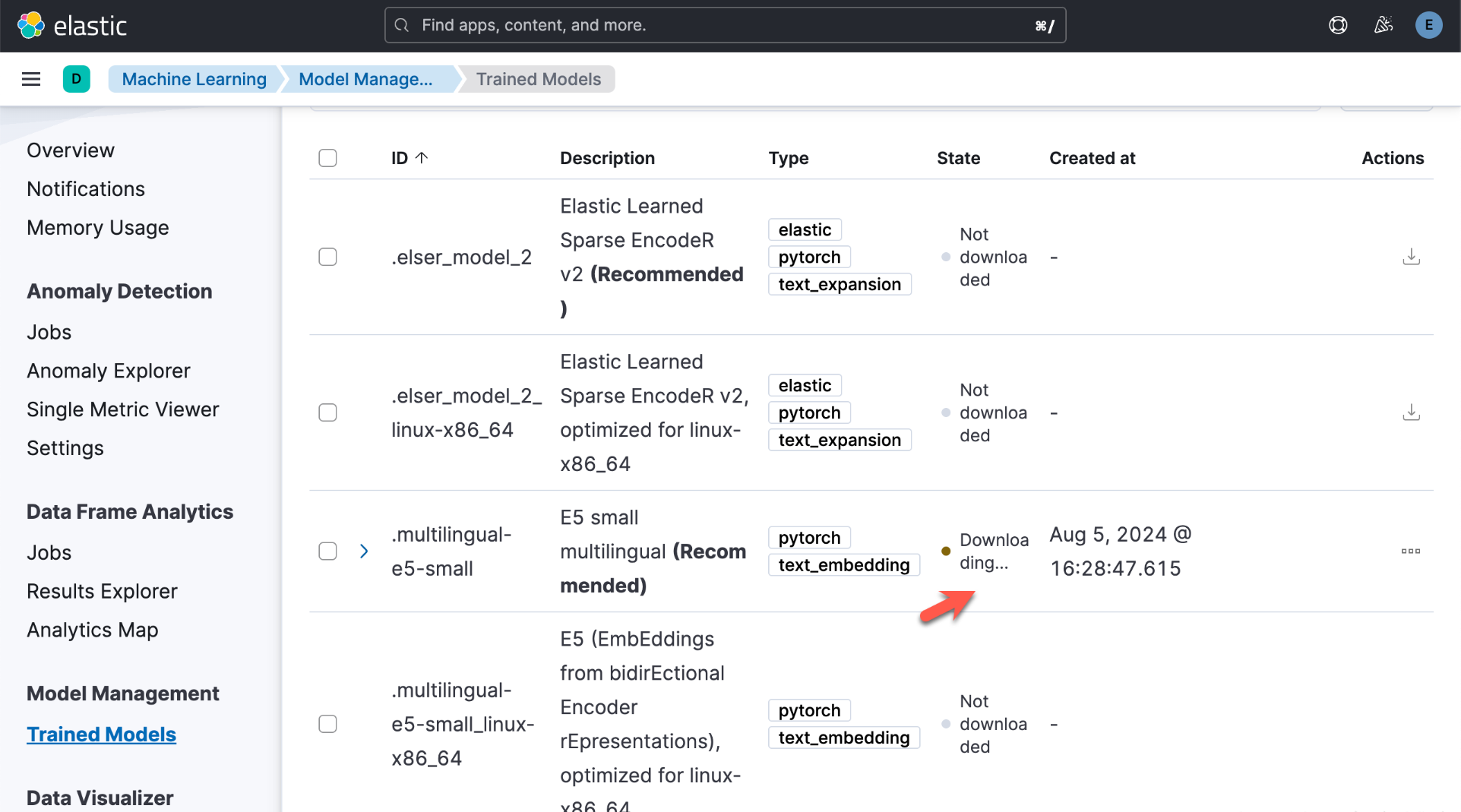
我们需要等一定的时间来完成上面的下载。
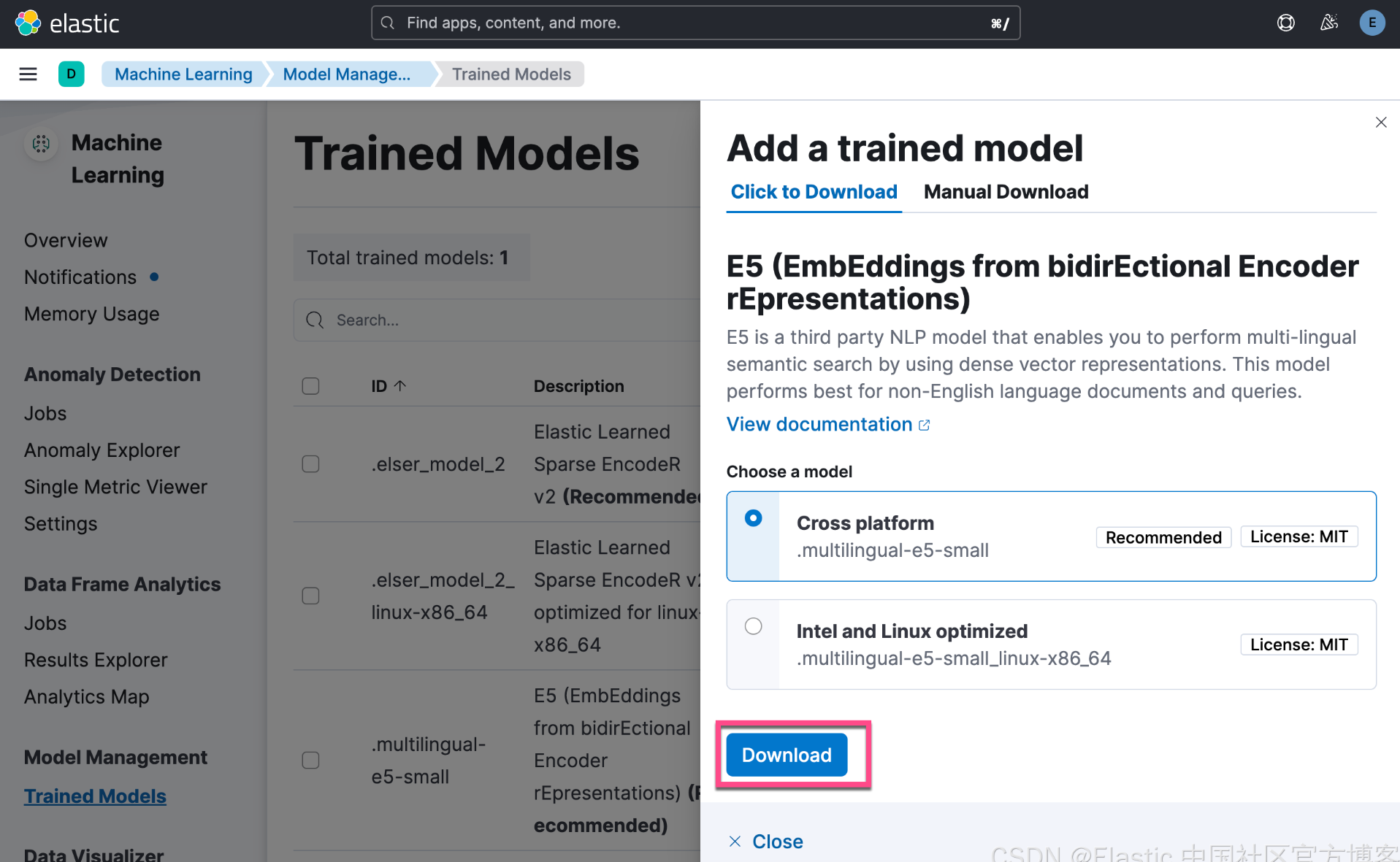
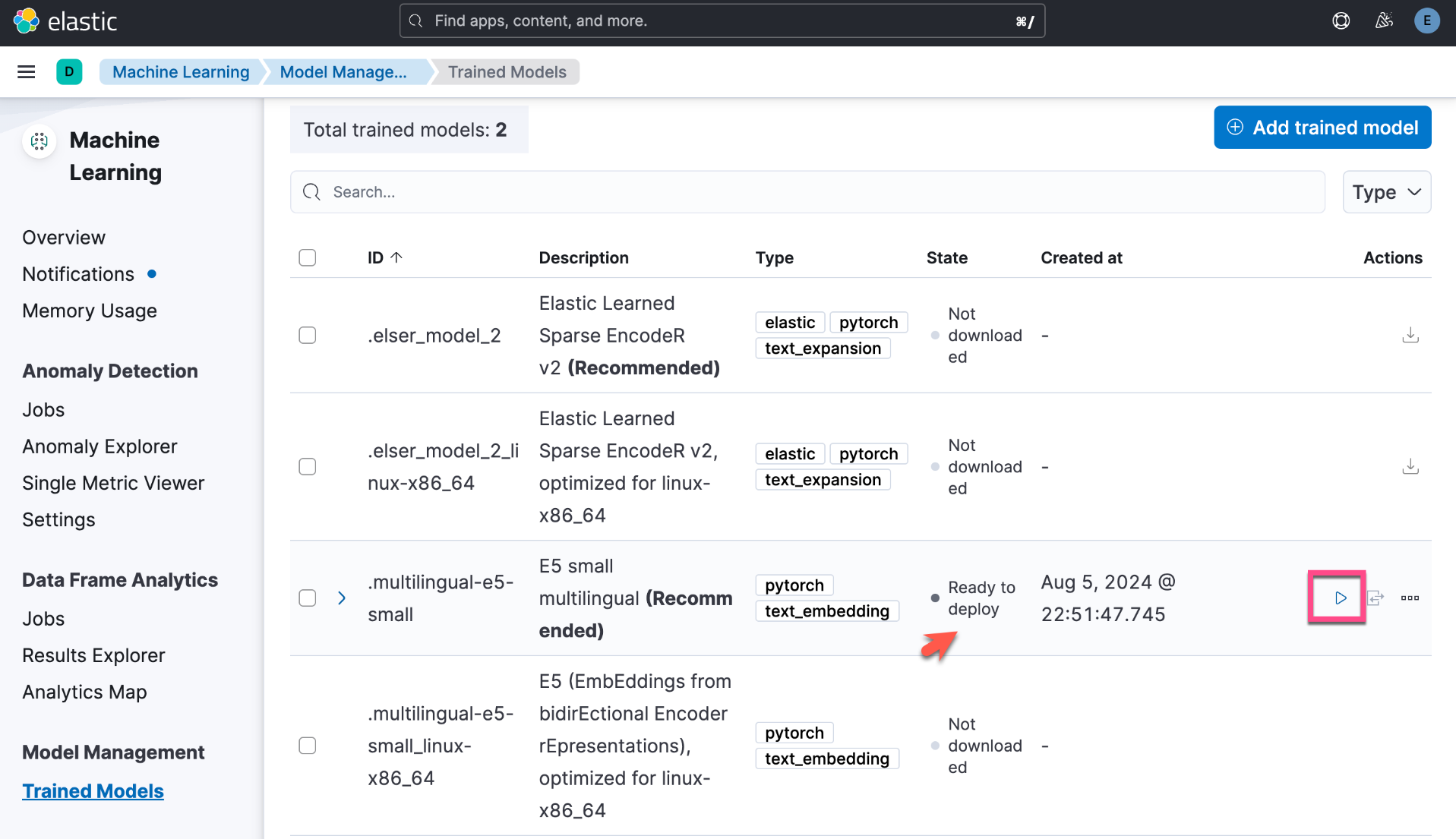
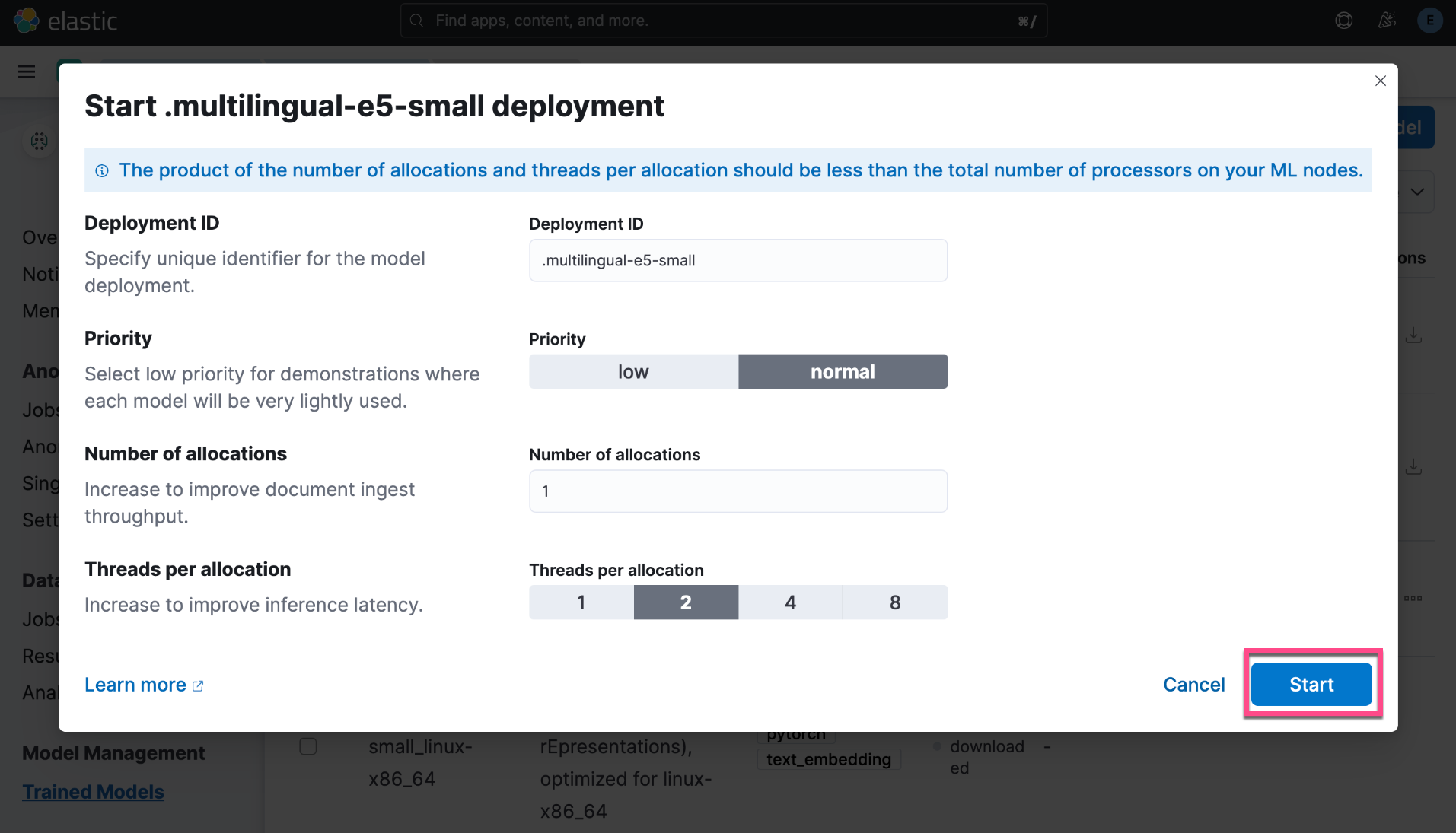
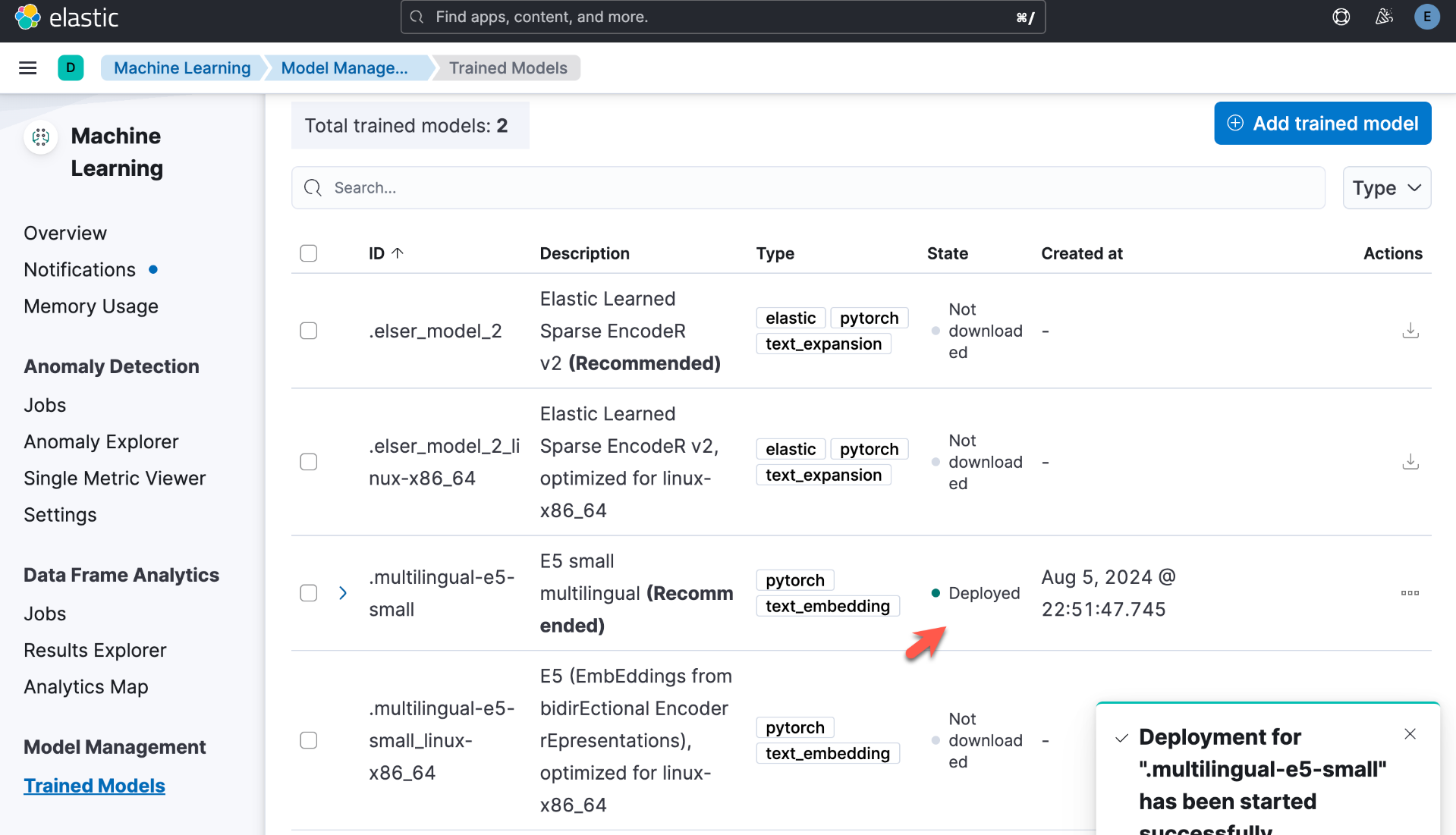
我们还可以直接通过如下的方法来进行下载:
![]()
![]()
![]()
![]()
![]()
上面显示 E5 已经部署成功了。
安装所需要的 python 依赖包
pip3 install python-dotenv elasticsearch==8.14 mistralai
我们可以使用如下的方法来查看 elasticsearch 的版本:
$ pip3 list | grep elasticsearch
elasticsearch 8.14.0
创建环境变量
为了能够使得下面的应用顺利执行,在项目当前的目录下运行如下的命令:
export ES_ENDPOINT="localhost"
export ES_USER="elastic"
export ES_PASSWORD="YourPassword"
export MISTRAL_API_KEY="YourKey"
你需要根据自己的 Elasticsearch 的配置进行相应的修改。你可以在地址申请 Mistral API key。前提是你需要注册一个账号。
使用 Elastic 和 Mistral 构建 RAG
我们接下来运行 Python notebook。我们在当前的目录下打入如下的命令:
jupyter notebook building_multilingual_rag_with_elastic_and_mistral.ipynb
安装软件包并导入必要的模块
# install packages
!python3 -m pip install python-dotenv elasticsearch==8.14 mistralai
# import modules
from mistralai.client import MistralClient
from mistralai.models.chat_completion import ChatMessage
from elasticsearch import Elasticsearch, exceptions
from elasticsearch.helpers import bulk
from getpass import getpass
import json
读入变量
from dotenv import load_dotenv
import os
load_dotenv()
ES_USER = os.getenv("ES_USER")
ES_PASSWORD = os.getenv("ES_PASSWORD")
ES_ENDPOINT = os.getenv("ES_ENDPOINT")
MISTRAL_API_KEY = os.getenv("MISTRAL_API_KEY")
实例化 Elasticsearch 客户端
# Create the client instance
url = f"https://{ES_USER}:{ES_PASSWORD}@{ES_ENDPOINT}:9200"
print(url)
es_client = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)
print(es_client.info())
上面显示我们的客户端成功连接到 Elasticsearch。
创建嵌入端点
try:
es_client.options(
request_timeout=60, max_retries=3, retry_on_timeout=True
).inference.put_model(
task_type="text_embedding",
inference_id="multilingual_embeddings",
body={
"service": "elasticsearch",
"service_settings": {
"model_id": ".multilingual-e5-small",
"num_allocations": 1,
"num_threads": 1,
},
},
)
print("Embedding endpoint created successfully.")
except exceptions.BadRequestError as e:
if e.error == "resource_already_exists_exception":
print("Embedding endpoint already created.")
else:
raise e
上面运行的输出结果为:
Embedding endpoint created successfully.
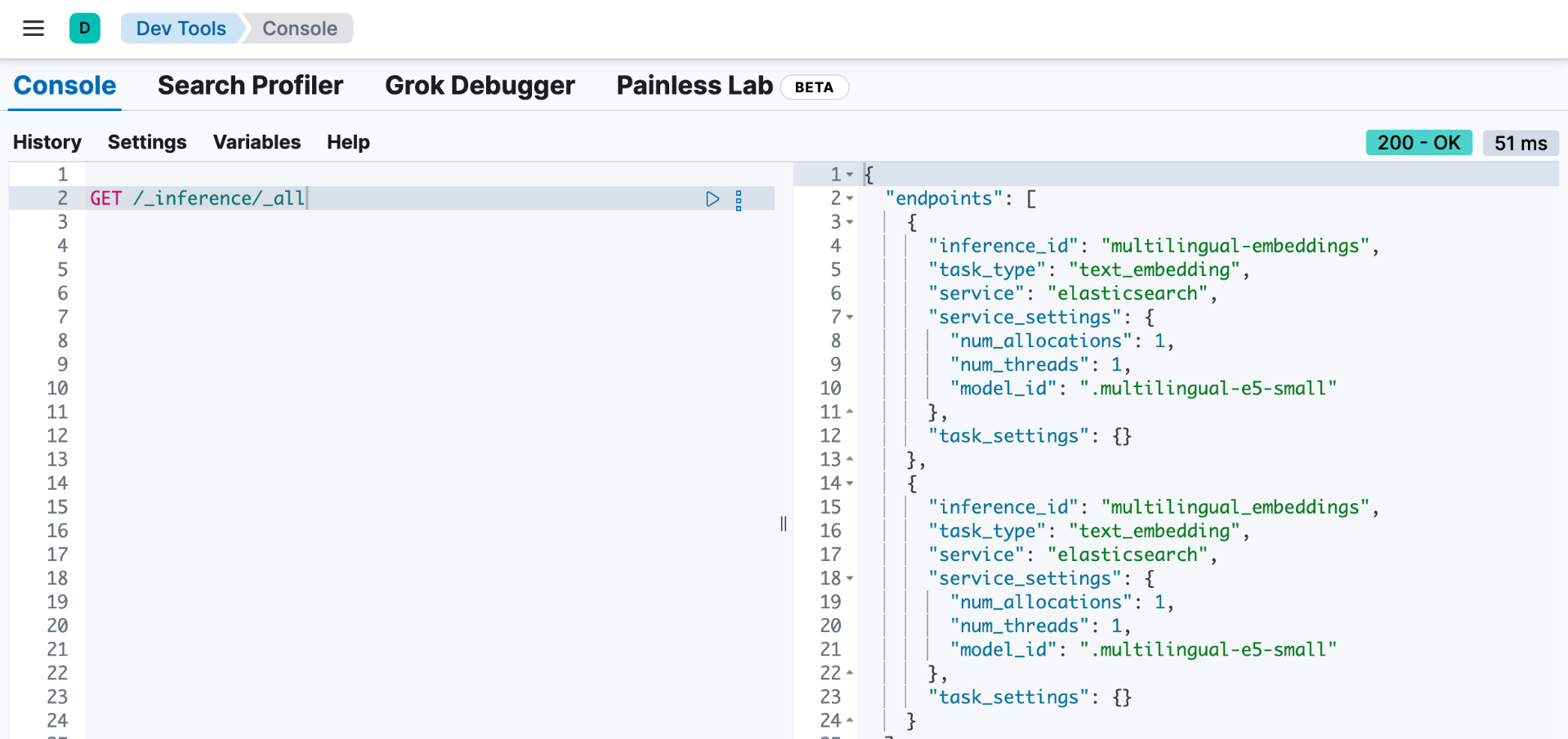
我们可以通过如下的方法来得到所有的 inference ids:
GET /_inference/_all
![]()
我们还可以通过如下的命令来得到某个特定 task_type 的 inference ids:
GET /_inference/text_embedding/_all
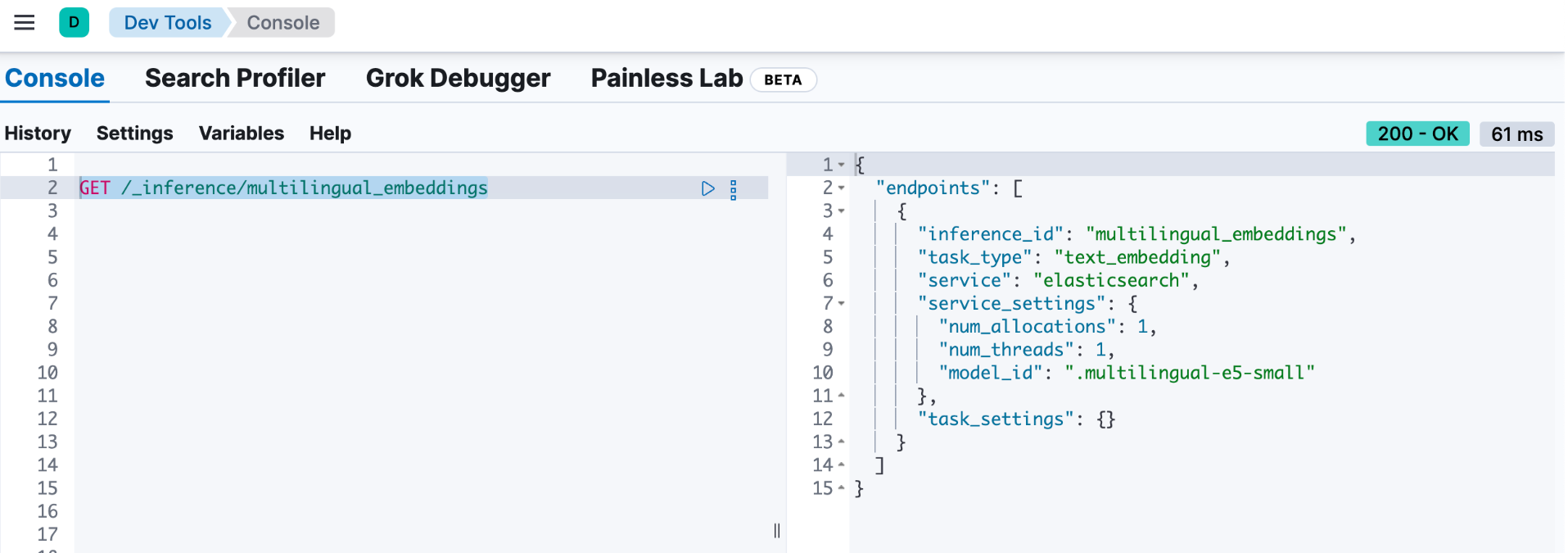
我们可以通过如下的命令来查看已经创建的 embedding endpoint:
GET /_inference/multilingual_embeddings
![]()
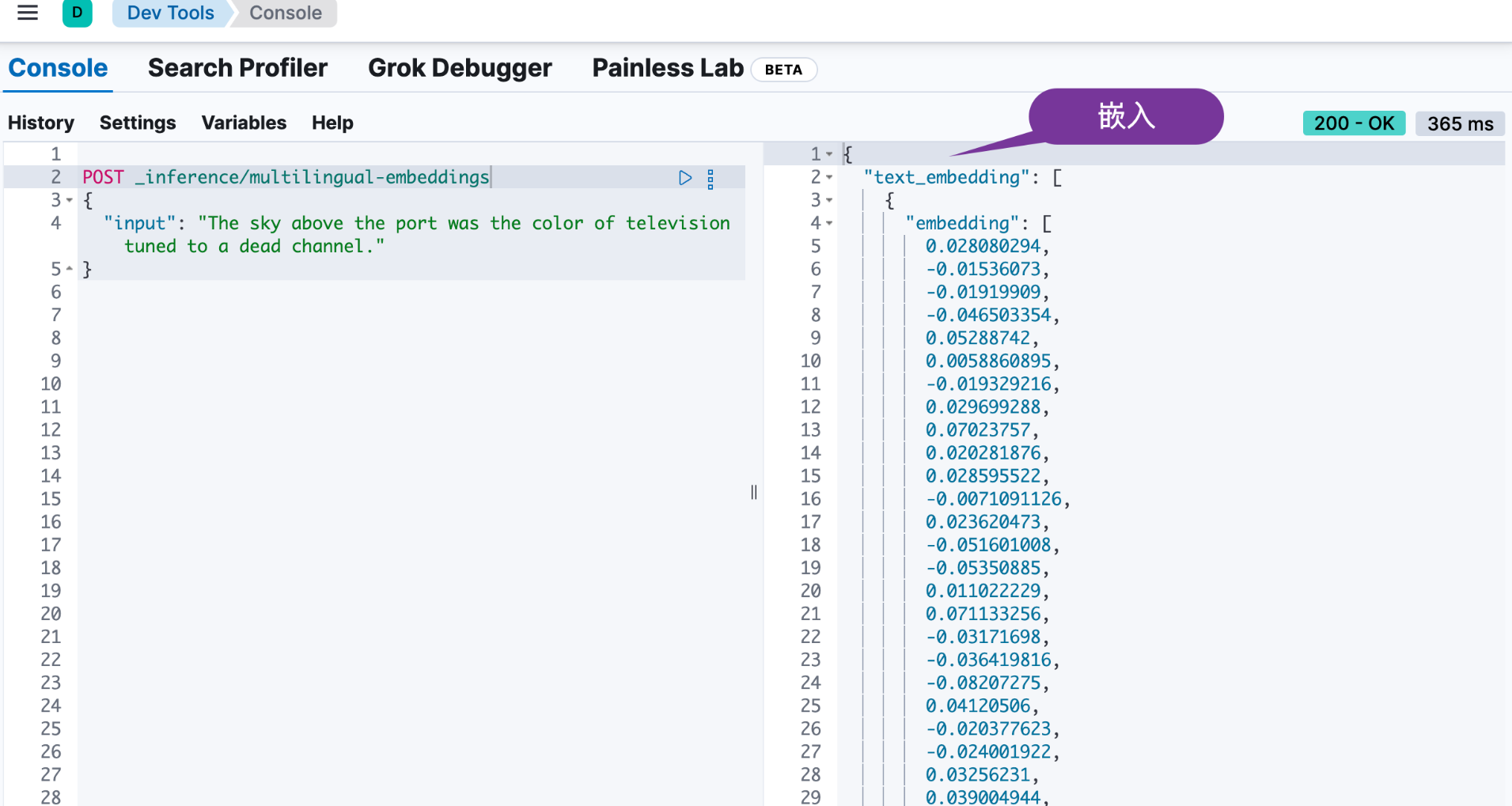
我们可以通过如下的方式来为一个特定的文字生成嵌入:
POST _inference/multilingual-embeddings
{
"input": "The sky above the port was the color of television tuned to a dead channel."
}
或者命令:
POST _inference/text_embedding/multilingual-embeddings
{
"input": "The sky above the port was the color of television tuned to a dead channel."
}
上面命令返回的结果为:
![]()
创建映射
try:
es_client.indices.create(
index="multilingual-mistral",
body={
"mappings": {
"properties": {
"super_body": {
"type": "semantic_text",
"inference_id": "multilingual-embeddings",
}
}
}
},
)
except exceptions.RequestError as e:
if e.error == "resource_already_exists_exception":
print("Index already exists.")
else:
raise e
写入文档
# Support tickets to add to the index
support_tickets = [
"""
_Support Ticket #EN1234_
**Subject**: Calendar sync not working with Google Calendar
**Description**:
I'm having trouble syncing my project deadlines with Google Calendar. Whenever I try to sync, I get an error message saying "Unable to connect to external calendar service."
**Resolution**:
The issue was resolved by following these steps:
1. Go to Settings > Integrations
2. Disconnect the Google Calendar integration
3. Clear browser cache and cookies
4. Reconnect the Google Calendar integration
5. Authorize the app again in Google's security settings
The sync should now work correctly. If problems persist, ensure that third-party cookies are enabled in your browser settings.
""",
"""
_Support-Ticket #DE5678_
**Betreff**: Datei-Upload funktioniert nicht
**Beschreibung**:
Ich kann keine Dateien mehr in meine Projekte hochladen. Jedes Mal, wenn ich es versuche, bleibt der Ladebalken bei 99% stehen und dann erscheint eine Fehlermeldung.
**Lösung**:
Das Problem wurde durch folgende Schritte gelöst:
1. Überprüfen Sie die Dateigröße. Die maximale Uploadgröße beträgt 100 MB.
2. Deaktivieren Sie vorübergehend den Virenschutz oder die Firewall.
3. Versuchen Sie, die Datei im Inkognito-Modus hochzuladen.
4. Wenn das nicht funktioniert, leeren Sie den Browser-Cache und die Cookies.
5. Als letzten Ausweg, versuchen Sie einen anderen Browser zu verwenden.
In den meisten Fällen lag das Problem an zu großen Dateien oder an Interferenzen durch Sicherheitssoftware. Nach Anwendung dieser Schritte sollte der Upload funktionieren.
""",
"""
_Q3 Marketing Campaign Ideas_
1. Social media contest: "Share Your Productivity Hack"
- Users share tips using our software, best entry wins a premium subscription
2. Webinar series: "Mastering Project Management"
- Invite industry experts to share insights using our tool
3. Email campaign: "Unlock Hidden Features"
- Series of emails highlighting lesser-known but powerful features
4. Partner with a productivity podcast for sponsored content
5. Create a "Project Management Memes" social media account for lighter, shareable content
""",
"""
_Mitarbeiter des Monats: Juli 2023_
Wir freuen uns, bekannt zu geben, dass Sarah Schmidt zur Mitarbeiterin des Monats Juli gewählt wurde!
Sarah hat außergewöhnliche Leistungen in folgenden Bereichen gezeigt:
- Kundenbetreuung: Sarah hat durchschnittlich 95% positive Bewertungen erhalten.
- Teamarbeit: Sie hat maßgeblich zur Verbesserung unseres internen Wissensmanagementsystems beigetragen.
- Innovation: Sarah hat eine neue Methode zur Priorisierung von Support-Tickets vorgeschlagen, die unsere Reaktionszeiten um 20% verbessert hat.
Bitte gratulieren Sie Sarah zu dieser wohlverdienten Anerkennung!
""",
]
# This function will create a bulk object for the given id and body
def build_bulk_obj(id, body):
return {
"_index": "multilingual-mistral",
"_id": id,
"_source": {"super_body": body},
}
data = []
# Constructing bulk object for each detail
for i, details in enumerate(support_tickets):
data.append(build_bulk_obj(i + 1, details))
try:
# Using the bulk API to index the data
bulk(es_client, data)
print("Data indexed successfully.")
except exceptions.RequestError as e:
print("Error indexing data.")
print(e)
我们可以看到如下的结果:
Data indexed successfully.
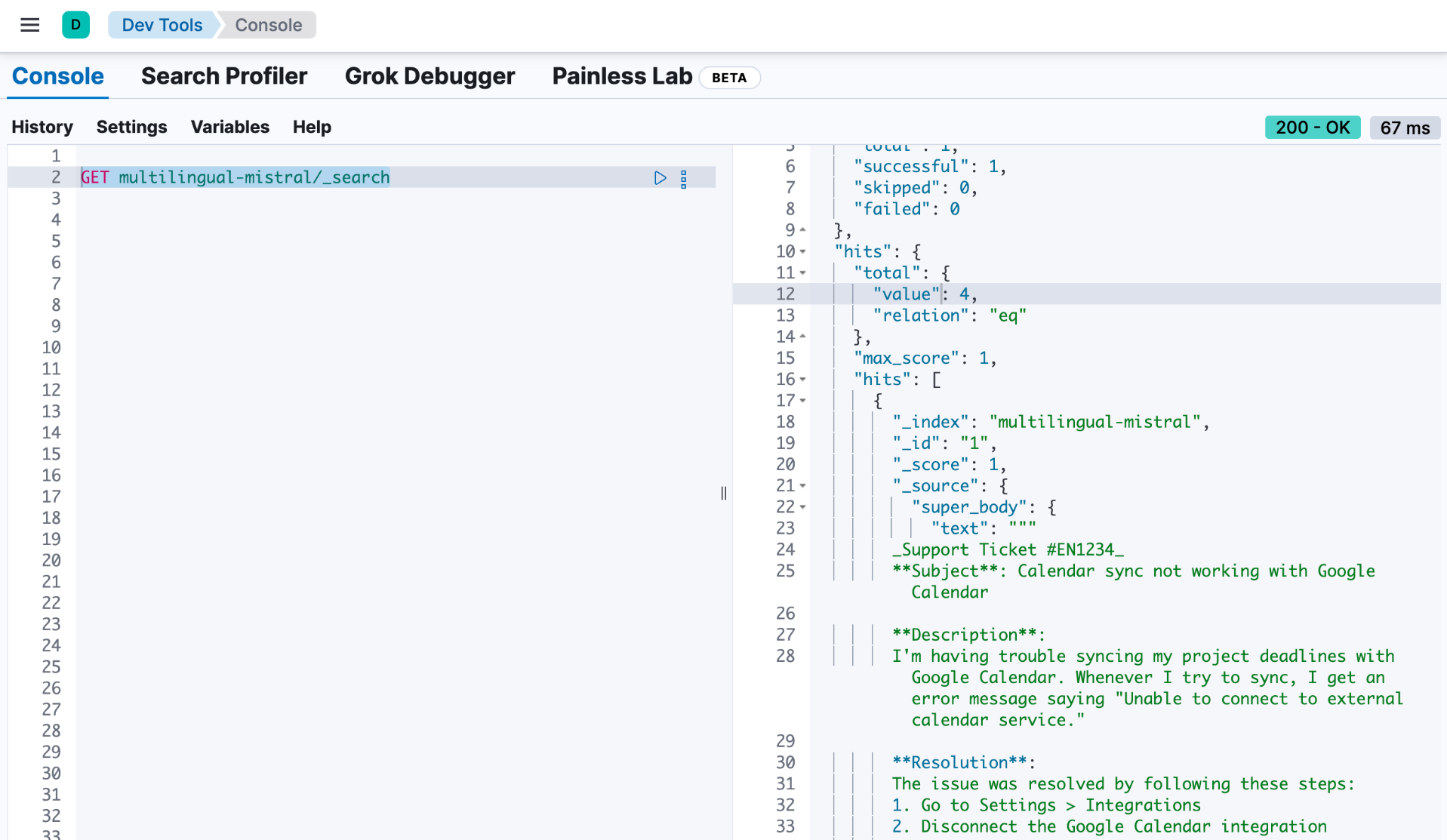
在 Kibana 里,我们可以通过如下的命令来进行查看:
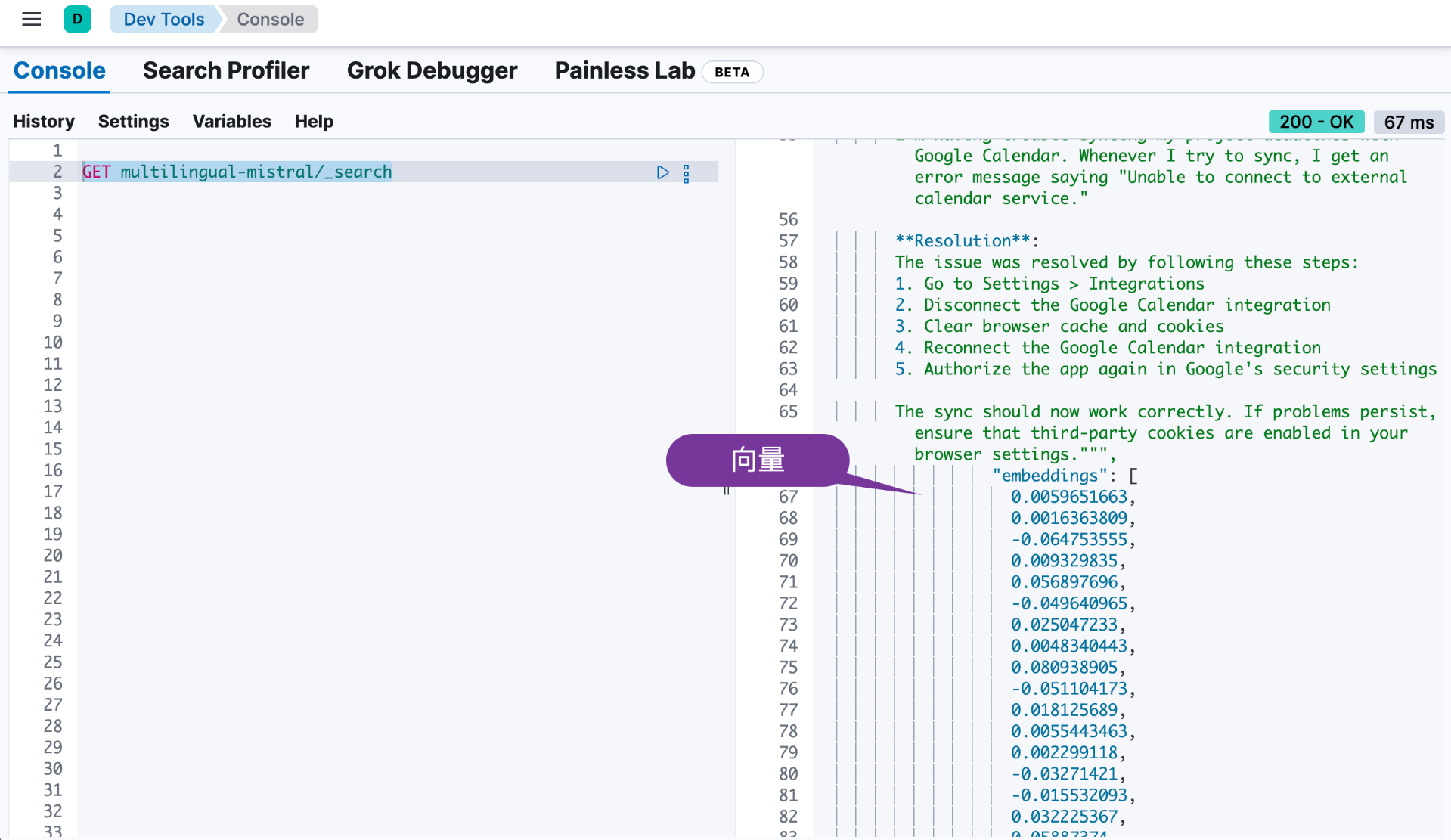
GET multilingual-mistral/_search
我们可以看到有 4 个文档:
![]()
![]()
检索文档
response = es_client.search(
index="multilingual-mistral",
body={
"size": 2,
"_source": {"excludes": ["*embeddings", "*chunks"]},
"query": {
"semantic": {
"field": "super_body",
"query": "Hola, estoy teniendo problemas para ocupar su aplicación, estoy teniendo problemas para sincronizar mi calendario, y encima al intentar subir un archivo me da error.",
}
},
},
)
# Print results
formatted_json = json.dumps(response.body, indent=4)
print(formatted_json)
![]()
回答问题
现在我们将使用 Mistral 来回答这个问题。
# Joining the Elasticsearch retrieve context
elastic_context = []
for r in response.body["hits"]["hits"]:
elastic_context.append(r["_source"]["super_body"]["text"])
context_str = "\n".join(elastic_context)
client = MistralClient(api_key=MISTRAL_API_KEY)
system_message = "You are a helpful multilingual agent that help users with their problems. You have access to a knowledge base on different languages and you must answer in the same language the question was asked."
user_message = f"""
## Question:
Hola, estoy teniendo problemas para ocupar su aplicación, estoy teniendo problemas para sincronizar mi calendario, y encima al intentar subir un archivo me da error.
## Related knowledge:
{context_str}
"""
messages = [
ChatMessage(role="system", content=system_message),
ChatMessage(role="user", content=user_message),
]
model = "open-mixtral-8x22b"
chat_response = client.chat(
model=model,
messages=messages,
)
print(chat_response.choices[0].message.content)
¡Hola! Lamento que estés teniendo problemas con nuestra aplicación. Parece que hay dos problemas distintos aquí.
En primer lugar, respecto a la sincronización del calendario, sigue los pasos que se indicaron en el ticket de soporte #EN1234:
1. Ve a Ajustes > Integraciones
2. Desconecta la integración de Google Calendar
3. Borra la caché y las cookies del navegador
4. Vuelve a conectar la integración de Google Calendar
5. Autoriza de nuevo la aplicación en los ajustes de seguridad de Google
Si sigues teniendo problemas, asegúrate de que las cookies de terceros estén habilitadas en los ajustes de tu navegador.
En segundo lugar, sobre el error al subir un archivo, puedes seguir los pasos que se indicaron en el ticket de soporte #DE5678:
1. Comprueba el tamaño del archivo. El tamaño máximo de subida es de 100 MB.
2. Desactiva temporalmente el antivirus o el firewall.
3. Intenta subir el archivo en modo incógnito.
4. Si eso no funciona, borra la caché y las cookies del navegador.
5. Como último recurso, prueba a utilizar un navegador diferente.
En la mayoría de los casos, el problema estaba causado por archivos demasiado grandes o por interferencias de software de seguridad. Después de seguir estos pasos, el proceso de subida debería funcionar correctamente.
删除所使用的资源
最后,我们可以删除所使用的资源,以防止它们消耗资源。
# Cleanup - Delete Index
es_client.indices.delete(index="multilingual-mistral", ignore=[400, 404])
# Cleanup - Delete Embeddings Endpoint
es_client.inference.delete_model(
inference_id="multilingual_embeddings", ignore=[400, 404]
)
ObjectApiResponse({'acknowledged': True, 'pipelines': []})