![]()
在 RAG 领域,多向量模型 ColBERT 通过为文档的每个 token 生成独立的向量,带来了检索精度的提升。但同样也带来了存储需求的剧增,并且仅支持英文,限制了其应用范围。
为解决这些问题,我们改进了 ColBERT 的架构和训练流程,特别是在多语言处理方面取得了突破。最新的 Jina-ColBERT-v2 支持 89 种语言,并引入了自定义输出维度选项,显著减少存储需求,提升了多语言检索的效率和准确性。
新版本的核心亮点
-
性能增强:与原始 ColBERT-v2 相比,英文检索性能提升了 6.5%;相较于前代 jina-colbert-v1-en,性能也提升了 5.4%。
-
多语言支持:新版本支持多达 89 种语言,涵盖阿拉伯语、中文、英语、日语、俄语等多种语言,同时支持编程语言。
-
输出维度可定制:新版本采用“俄罗斯套娃”式表征学习技术(Matryoshka Representation Learning, MRL),提供 128、96 和 64 维的输出向量选项,允许用户根据实际需求选择合适的维度。
完整的技术报告可以在 arXiv 上找到:https://arxiv.org/abs/2408.16672
jina-colbert-v2 表现一览
在检索性能上,jina-colbert-v2 展现了不俗的优势,无论是英文检索任务,还是多语言支持都优于之前的版本。通过 Jina AI 祖传 8192 token 输入长度的加持,这款多向量模型的优势也能得以充分发挥。以下是与其他版本的对比,可以清晰看到核心的改进:
|
jina-colbert-v2 |
jina-colbert-v1-en |
原始 ColBERTv2 |
| 英语 BEIR 任务的平均值 |
0.521 |
0.494 |
0.489 |
| 多语言支持 |
89 种语言 |
仅支持英语 |
仅支持英语 |
| 输出维度 |
128、96 或 64 |
固定 128 |
固定 128 |
| 最大查询长度 |
32 tokens |
32 tokens |
32 tokens |
| 最大文档长度 |
8192 tokens |
8192 tokens |
512 tokens |
| 参数数量 |
5.6 亿 |
1.37 亿 |
1.1 亿 |
| 模型大小 |
1.1GB |
550MB |
438MB |
1. 性能提升
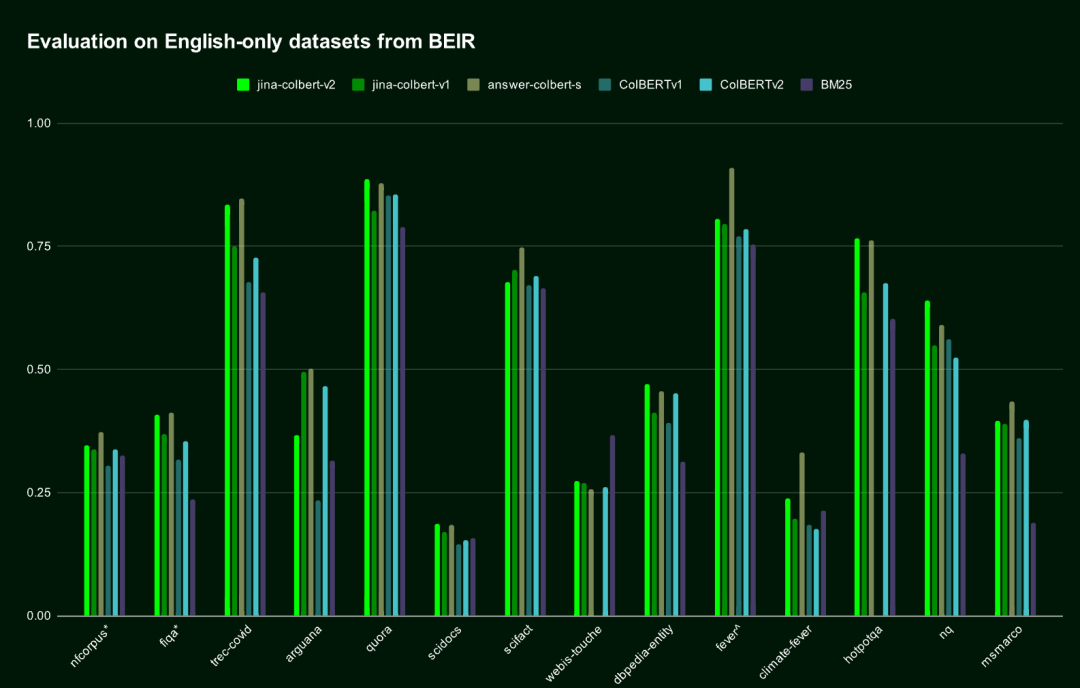
在英语检索任务中,jina-colbert-v2 的表现超越了前一代 jina-colbert-v1-en 和原版 ColBERT v2,接近专为英语设计的 AnswerAI-ColBERT-small 模型水平。
| 模型名称 |
英语 BEIR 基准测试的平均分 |
多语言支持 |
jina-colbert-v2 |
0.521 |
支持多语言 |
jina-colbert-v1-en |
0.494 |
仅支持英语 |
| ColBERT v2.0 |
0.489 |
仅支持英语 |
| AnswerAI-ColBERT-small |
0.549 |
仅支持英语 |
![]() Jina ColBERT v2 在基于英语的 BEIR 数据集上的表现
Jina ColBERT v2 在基于英语的 BEIR 数据集上的表现
2. 多语言支持
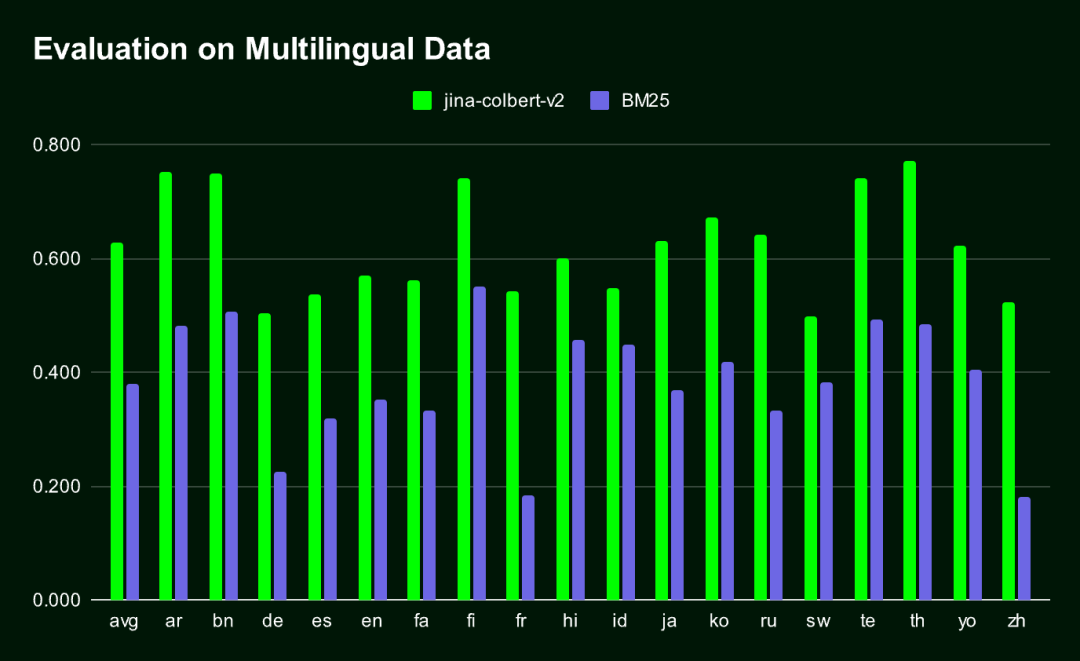
Jina-ColBERT-v2 是目前唯一一款支持多种语言的 ColBERT 模型,能够生成非常紧凑的 Embedding 向量,效果显著好于传统 BM25 检索方法(在 MIRACL 基准测试的所有语言中)。
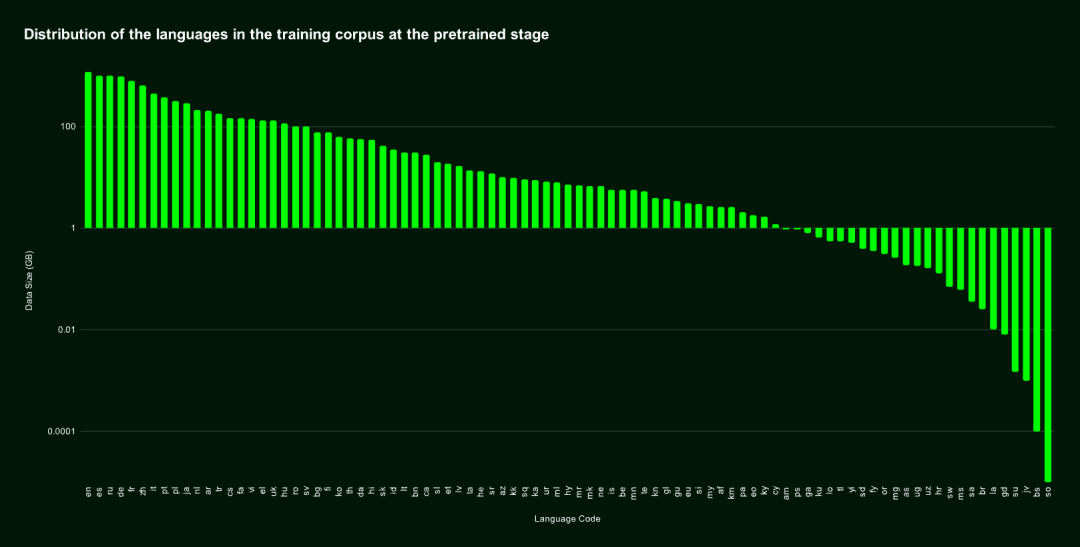
jina-colbert-v2 的训练语料库覆盖了 89 种语言,包括 4.5 亿对弱监督的语义相关句子对、问答对和查询-文档对。其中,其中一半的数据是英语,剩下的部分包括 29 种不同的非英语语言,此外,还使用了 3.0% 的编程语言数据和 4.3% 的跨语言数据。
我们还专门对 阿拉伯语、中文、法语、德语、日语、俄语、西班牙语等主流语言 和 编程语言 进行了额外训练,通过引入对齐的双语文本语料库,使得模型在处理跨语言任务时表现出色。
![]() 预训练数据集的语言分布
预训练数据集的语言分布
下图展示了在 MIRACL 基准测试中,Jina-ColBERT-v2 和 BM25 在 16 种语言上的性能对比结果。
![]()
3. 俄罗斯套娃表征学习
俄罗斯套娃表征学习(Matryoshka Representation Learning, MRL) 是一种灵活且高效的训练方法,能够在支持不同输出向量维度的同时,最大限度地减少精度损失。具体实现是在模型的隐藏层中引入多个线性层,每一层对不同维度进行处理。该技术更多细节,请参阅:https://arxiv.org/abs/2205.13147
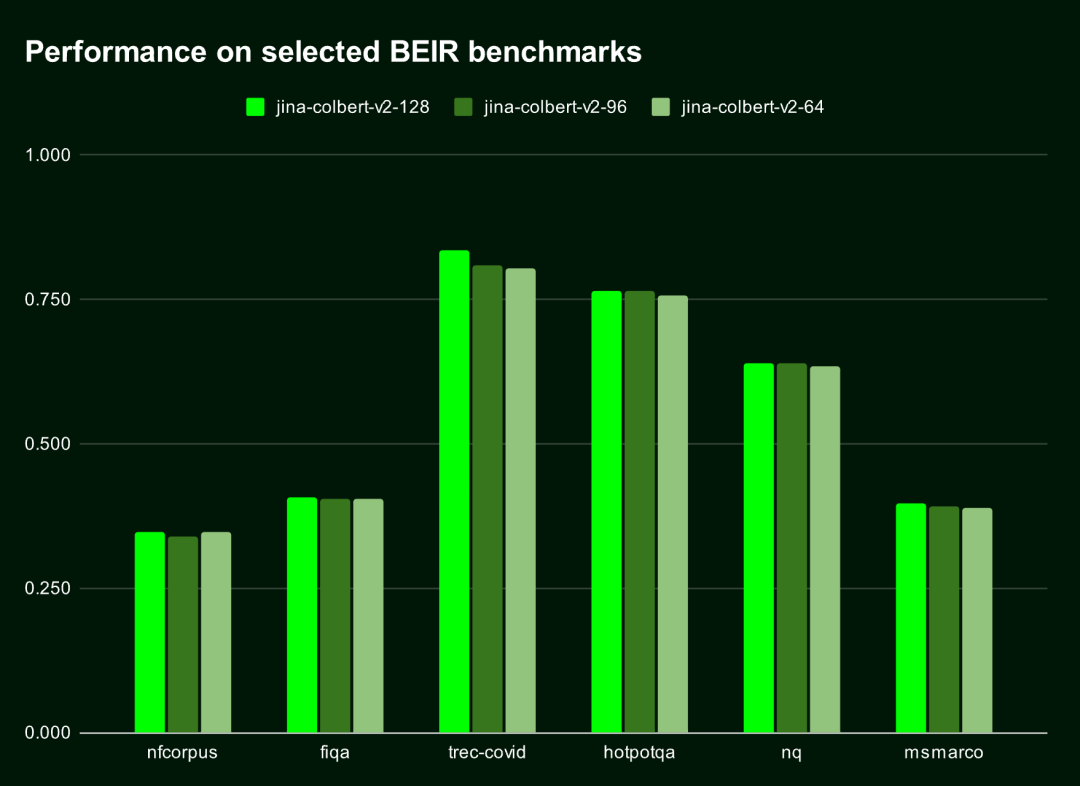
默认情况下,Jina-ColBERT-v2 会生成 128 维的 Embedding,但你可以选择更短的向量,比如 96 维或 64 维。即便向量缩短了 25% 或 50%,它对性能的影响几乎可以忽略(下降小于 1.5%)。也就是说,无论你需要多长的向量,这个模型都能保持高效而精准的表现。
下表展示了 Jina-ColBERT-v2 在这六个 BEIR 基准测试中前十名结果 (nDGC@10) 的表现。可以看到,128 维和 96 维之间的性能差异不到 1%,而 128 维和 64 维之间的差异不到 1.5%。
| 输出维度 |
平均得分(6 项基准测试的 nDGC@10) |
| 128 |
0.565 |
| 96 |
0.558 |
| 64 |
0.556 |
下图直观地展示了 Jina-ColBERT-v2 在不同输出维度下的性能表现。
![]()
选择较小的输出向量不仅能节省存储空间,还能提升计算速度,尤其是在需要比较向量或计算距离的场景中,如向量检索系统。
同时成本也是非常明显下降的,根据 Qdrant 的云端成本估算器,在 AWS 上存储 1 亿个文档时,使用 128 维向量的费用是每月 1319.24 美元,而如果使用 64 维向量,费用可以直接减半,降到每月 659.62 美元。这样一来,不仅速度提升了,成本也大幅降低。
如何开始使用 Jina ColBERT v2
Jina ColBERT v2 已经上线 Jina Search Foundation API、AWS Marketplace 和 Azure 平台。此外,它还以 CC BY-NC-4.0 许可证在 Hugging Face 上开源,供非商业用途使用。
-
AWS Marketplace: https://aws.amazon.com/marketplace/seller-profile?id=seller-stch2ludm6vgy
-
Azure: https://azuremarketplace.microsoft.com/en-gb/marketplace/apps?search=Jina
-
Hugging Face: https://huggingface.co/jinaai/jina-colbert-v2
通过 Jina Search Foundation API
用于 Embedding
使用 Jina Embedding API 获取 jina-colbert-v2 的 Embedding 是最简单直接的方式。
两个关键参数:
dimensions:表示 Embedding 的输出维度,默认为 128,也可以选择 64。
input_type:决定输入类型,query 的最大长度限制为 32 token,超过部分会自动截断,而 document 可以长达 8192 token。文档编码可以离线处理,这样在查询时只需要编码查询部分,能够显著提高处理速度。
Jina API Key 在 jina.ai/embeddings 获取。
curl https://api.jina.ai/v1/multi-vector \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer <YOUR JINA API KEY>" \\
-d '{
"model": "jina-colbert-v2",
"dimensions": 128, # 或 64
"input_type": "document", # 这里需要注意input_type 是 document 还是 query
"embedding_type": "float",
"input": [
"在此输入你的文档文本",
"你可以发送多个文本",
"每个文本最长可达 8192 个标记"
]}'
用于 Reranker
要通过 Jina Reranker API 使用 jina-colbert-v2,传入一个查询和多个文档,并返回可 Reranker 的匹配分数,构造如下请求:
curl https://api.jina.ai/v1/rerank \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer <YOUR JINA API KEY>" \\
-d '{
"model": "jina-colbert-v2",
"query": "柏林的人口是多少?",
"top_n": 3,
"documents": [
"2023年柏林的人口比去年增长了0.7%。因此,到去年年底,柏林的居民人数比2022年增加了约27300人。30岁到40岁的人群是数量最多的年龄组。柏林拥有约88.1万外国居民,来自约170个国家,平均年龄为42.5岁。",
"柏林山是南极洲玛丽·伯德地的一个冰川覆盖的火山,距离阿蒙森海约100公里(62英里)。它是一个宽约20公里(12英里)的山峰,有寄生火山口,由两座合并的火山组成:柏林火山,其火山口宽2公里(1.2英里),以及距离柏林火山约3.5公里(2.2英里)的Merrem峰,火山口宽2.5×1公里(1.55英里×0.62英里)。",
"截至2023年12月31日,各联邦州按国籍和州统计的人口数据",
"柏林的都市区人口超过450万,是德国人口最多的都市区。柏林-勃兰登堡首都地区约有620万人口,是德国第二大都市区,仅次于莱茵-鲁尔区,并且是欧盟第六大都市区(按GDP计算)。",
"欧文·柏林(原名以色列·贝林)是一位美国作曲家和词曲作者。他的音乐是《伟大的美国歌本》的一部分。柏林获得了许多荣誉,包括奥斯卡奖、格莱美奖和托尼奖。",
"柏林是美国康涅狄格州首都规划区的一个城镇。2020年人口普查时人口为20,175。",
"柏林是德国的首都和最大城市,无论是面积还是人口。其超过385万居民使其成为欧盟人口最多的城市(按城市限界内人口计算)。",
"《柏林,柏林》是一部为ARD制作的电视剧,于2002年至2005年在德国第一电视台的晚间节目中播出。导演包括弗朗茨斯卡·迈耶·普莱斯、克里斯托夫·施内、斯文·温特瓦尔特和蒂图斯·塞尔格。"
]
}'
还要注意 top_n 参数,它指定检索时返回的文档数量。如果你只需要最优的匹配结果,可以把 top_n 设置为 1。
有关更多的 Python 或其他语言的示例代码,请访问 https://jina.ai/embeddings 页面,或在 https://jina.ai/reranker/ 的下拉菜单中选择 jina-colbert-v2。
通过 Stanford ColBERT
如果你用过 Stanford ColBERT 库,你现在可以无缝替换成 Jina ColBERT v2 版本。只需指定 jinaai/jina-colbert-v2 作为模型源。
from colbert.infra import ColBERTConfig
from colbert.modeling.checkpoint import Checkpoint
ckpt = Checkpoint("jinaai/jina-colbert-v2", colbert_config=ColBERTConfig())
docs = ["你的文本列表"]
query_vectors = ckpt.queryFromText(docs)
通过 RAGatouille
Jina ColBERT v2 同样集成在 RAGatouille 系统中,通过 RAGPretrainedModel.from_pretrained() 方法就能下载使用,非常方便。
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("jinaai/jina-colbert-v2")
docs = ["你的文本列表"]
RAG.index(docs, index_name="your_index_name")
query = "你的查询"
results = RAG.search(query)
通过 Qdrant
从 Qdrant 1.10 版本开始,Qdrant 支持了多向量和迟交互模型,你可以直接使用 jina-colbert-v2。不论是本地部署还是云端托管的 Qdrant,只需要在客户端中正确配置 multivector_config 参数,就可以把文档插入到多向量集合中。
使用 MAX_SIM 操作创建新集合
from qdrant_client import QdrantClient, models
qdrant_client = QdrantClient(
url="<YOUR_ENDPOINT>",
api_key="<YOUR_API_KEY>",
)
qdrant_client.create_collection(
collection_name="{collection_name}",
vectors_config={
"colbert": models.VectorParams(
size=128,
distance=models.Distance.COSINE,
multivector_config=models.MultiVectorConfig(
comparator=models.MultiVectorComparator.MAX_SIM
),
)
}
)
⚠️ 正确设置 multivector_config 参数是 Qdrant 中使用 ColBERT 模型的关键。
将文档插入多向量集合
import requests
from qdrant_client import QdrantClient, models
url = 'https://api.jina.ai/v1/multi-vector'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer <YOUR BEARER>'
}
data = {
'model': 'jina-colbert-v2',
'input_type': 'query',
'embedding_type': 'float',
'input': [
'在此输入你的文本',
'你可以发送多个文本',
'每个文本最长可达 8192 个标记'
]
}
response = requests.post(url, headers=headers, json=data)
rows = response.json()["data"]
qdrant_client = QdrantClient(
url="<YOUR_ENDPOINT>",
api_key="<YOUR API_KEY>",
)
for i, row in enumerate(rows):
qdrant_client.upsert(
collection_name="{collection_name}",
points=[
models.PointStruct(
id=i,
vector=row["embeddings"],
payload={"text": data["input"][i]}
)
],
)
查询集合
from qdrant_client import QdrantClient, models
import requests
url = 'https://api.jina.ai/v1/multi-vector'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer <YOUR BEARER>'
}
data = {
'model': 'jina-colbert-v2',
"input_type": "query",
"embedding_type": "float",
"input": [
"Jina AI 的Embedding模型支持多少个标记的输入?"
]
}
response = requests.post(url, headers=headers, json=data)
vector = response.json()["data"][0]["embeddings"]
qdrant_client = QdrantClient(
url="<YOUR_ENDPOINT>",
api_key="<YOUR API_KEY>",
)
results = qdrant_client.query_points(
collection_name="{collection_name}",
query=vector,
)
print(results)
总结
jina-colbert-v2 在前代版本的基础上,覆盖了 89 种全球语言,以及多种 Embedding 输出维度的选择,用户能够灵活平衡精度和效率需求,节省计算和时间成本。点击 https://jina.ai 立即试用,还可获得 100 万个免费 Token。
本文由 Hugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。 文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。 了解更多请关注公众号:
如果你有与开源 AI、Hugging Face 相关的技术和实践分享内容,以及最新的开源 AI 项目发布,希望通过我们分享给更多 AI 从业者和开发者们,请通过下面的链接投稿与我们取得联系: