一个工作日下午,某大型通信运营商业务人员报告,一套 ClickHouse 集群在进行插入数据操作的时候,系统报错 too many mutations(1036),插入数据失败!
作者:张宇,爱可生DBA,负责数据库运维和故障分析。擅长 ClickHouse、MySQL、Oracle,爱好骑行、AI、动漫和技术分享。
爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
本文约 1500 字,预计阅读需要 5 分钟。
回到现场
一个工作日下午,某大型通信运营商业务人员报告,一套 ClickHouse 集群在进行插入数据操作的时候,系统报错 too many mutations(1036),插入数据失败!
![]()
排查过程中发现,系统表 system.mutations 里(is_done=0)存在大量的未处理的更新(mutations)操作,且都是 alter table xxx update xxx 语句。
与业务沟通之后得知,业务每天有 50 次左右的数据更新操作,若更新失败则会重试直至成功。每个节点会因数据不同,对应数量不等的 mutations 操作。
先说故障原因。系统设置的 mutations 最大值为 1000,超过会导致插入操作失败(业务数据无法新增)。
基本信息
先了解一下这套 ClickHouse 集群的情况。
- ClickHouse 版本:23.9.1
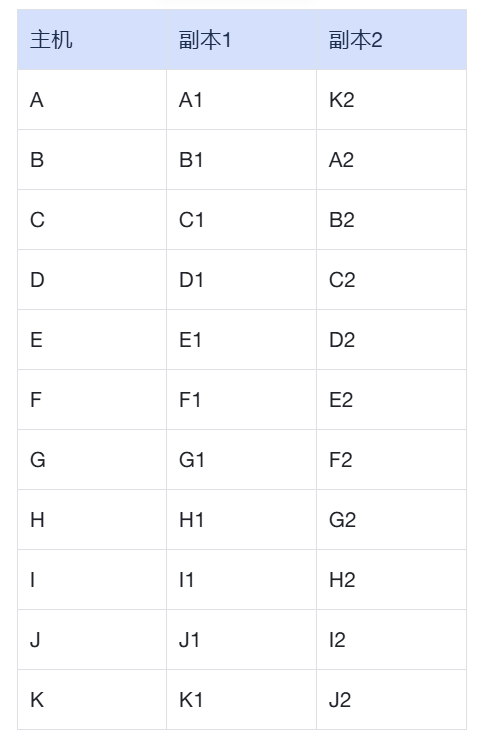
- 集群架构:2 副本,11 分片
- 数据量:约 4 TB(11×362GB)
- 部署规划:
![]()
副本交叉部署,高可用业务无感知。
恢复思路
在 ClickHouse 数据库当中,mutations 操作语句 alter table xxx update/delete 操作会对表产生非常大的工作负载。
再确认业务操作流程无法修改后,只能选择适配这类操作,计划将表引擎改造为更适合覆盖更新的类型,如:
- ReplacingMergeTree
- CollapsingMergeTree
- VersionedCollapsingMergeTree
这几种类型的引擎,可以通过复制功能(Replicated)来控制更新。这样既能保证快速查询能力,也不会让系统耗费大量的资源,保证系统的健壮性。
三种类型的使用方式本文不做介绍,可以在官方文档查询。
现在,需要尽快回复业务。经业务沟通后,将按照以下流程恢复服务:
- 清理 mutations
- 更新表引擎
- 启动服务
- 验证解决
1. 清理 mutations
我们选择整个集群 23805 个 mutations 通过 kill mutation 的方式"杀掉"。然后尽快修改表引擎类型,回复业务使用。
-- kill 掉未完成的 mutation
KILL MUTATION WHERE database = 'default' AND table = 'table'
2. 更新表引擎
三种表引擎有多种优化方式,这里演示 ReplacingMergeTree 的一种。
准备数据库
-- 创建 ReplacingMergeTree 表
CREATE TABLE hackernews_rmt (
id UInt32,
author String,
comment String,
views UInt64
)
ENGINE = ReplacingMergeTree
PRIMARY KEY (author, id)
-- 插入两行数据
INSERT INTO hackernews_rmt VALUES
(1, 'ricardo', 'This is post #1', 0),
(2, 'ch_fan', 'This is post #2', 0)
-- 在插入两行数据
INSERT INTO hackernews_rmt VALUES
(1, 'ricardo', 'This is post #1', 100),
(2, 'ch_fan', 'This is post #2', 200)
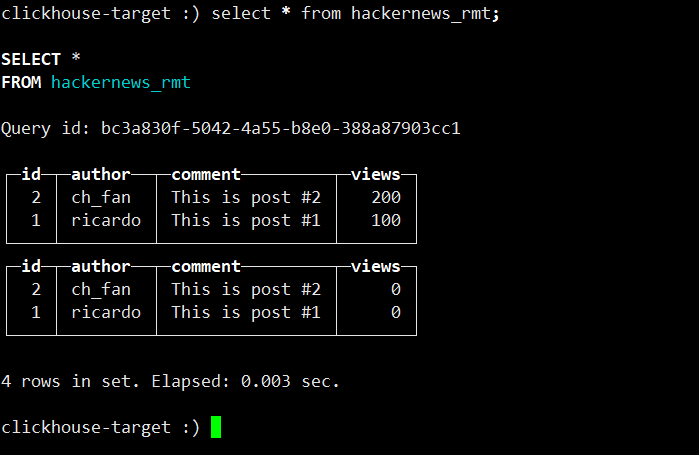
经过查询,表里面存在 4 行数据。建表的时候主键是author 和 id,当没有指定 ORDER BY 的时候,和主键一致。
![]()
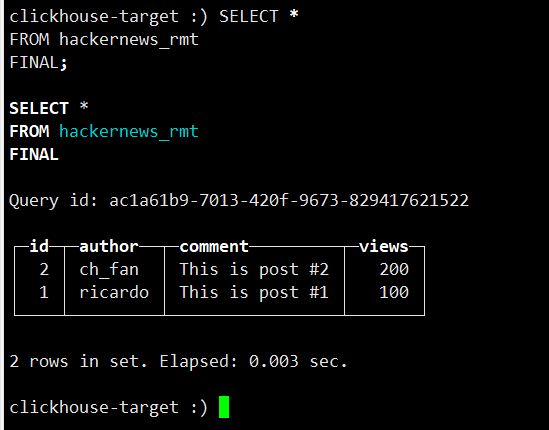
现在使用 final 查询,如果排序键相同(在这里是 id,author)会自动选择最新的插入的数据。
![]()
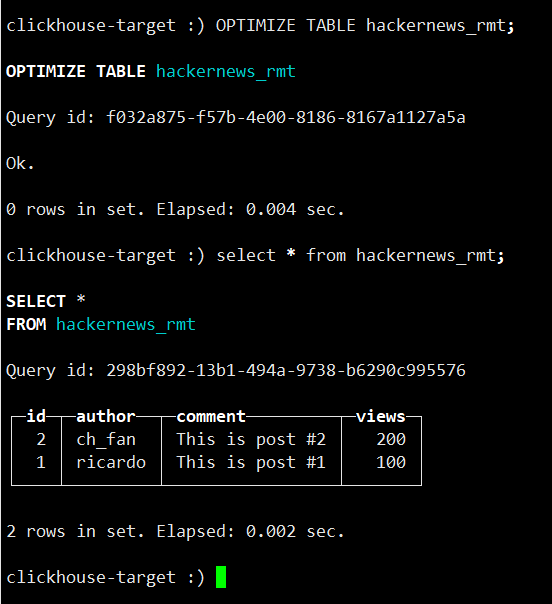
然后当我们使用 optimize 进行分区合并的时候,会直接删除旧数据保留新数据。合并是 ClickHouse 系统自动判断,无需手工处理,这里是为了演示手工执行了 optimize 的效果。
![]()
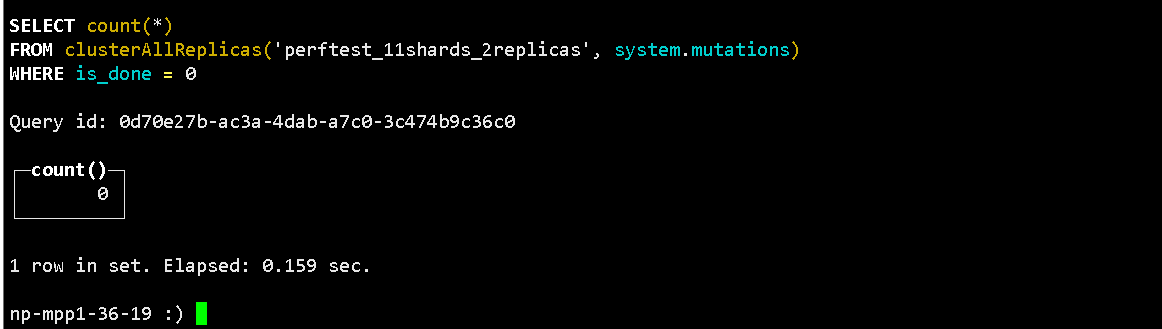
我们使用以上方式进行表引擎更改优化,优化后查询判断是否产生新的 mutations。
-- default 是集群名称,不是用户名称
SELECT count(*)
FROM clusterAllReplicas('default', system.mutations)
WHERE is_done = 0;
![]()
选择替换数据库引擎替换成 ReplacingMergeTree 后业务恢复正常,本次故障共造成业务暂停 30 分钟。
总结
- 及时监控,分析 mutations 的原因并根据业务需求进行分析和处理。
- 如果业务存在频繁的 UPDATE 或 DELETE 操作产生大量 mutations,建议更换表引擎。
- 如果 mutations 是由于增加字段或列等操作产生的,可忽略第 2 条。
优化数据更新和删除策略: 设计数据更新和删除策略时,应考虑系统的承载能力和潜在的风险。优化业务逻辑来减少不必要的数据更新和删除操作,并在操作失败时采取更合理的重试策略,如果是少量或者偶尔的删除可以使用 ClickHouse 轻量级删除(Lightweight Deletes)。
后记:经过该解决方案处理后,至今已稳定运行 4 个月。
更多技术文章,请访问:https://opensource.actionsky.com/
关于 SQLE
SQLE 是一款全方位的 SQL 质量管理平台,覆盖开发至生产环境的 SQL 审核和管理。支持主流的开源、商业、国产数据库,为开发和运维提供流程自动化能力,提升上线效率,提高数据质量。
✨ Github:https://github.com/actiontech/sqle
📚 文档:https://actiontech.github.io/sqle-docs/
💻 官网:https://opensource.actionsky.com/sqle/
👥 微信群:请添加小助手加入 ActionOpenSource
🔗 商业支持:https://www.actionsky.com/sqle