社区王牌专栏《一问一实验:AI 版》全新改版归来,得到了新老读者们的关注。其中不乏对 ChatDBA 感兴趣的读者前来咨询,表达了想试用体验 ChatDBA 的意愿,对此我们表示感谢 🤟。
目前,ChatDBA 还在最后的准备阶段,会尽快跟大家见面。想预约试用的朋友,可以扫码文末的 意见反馈 二维码或点击 原文链接 填写调研问卷。我们正在对 DBA 群体试用大模型的情况进行调研,这对我们打磨 ChatDBA 的使用体验非常重要。
下面让我们正式进入《一问一实验:AI 版》的第 52 期。
完整操作视频见 社区 B 站及视频号更新
![]()
问题
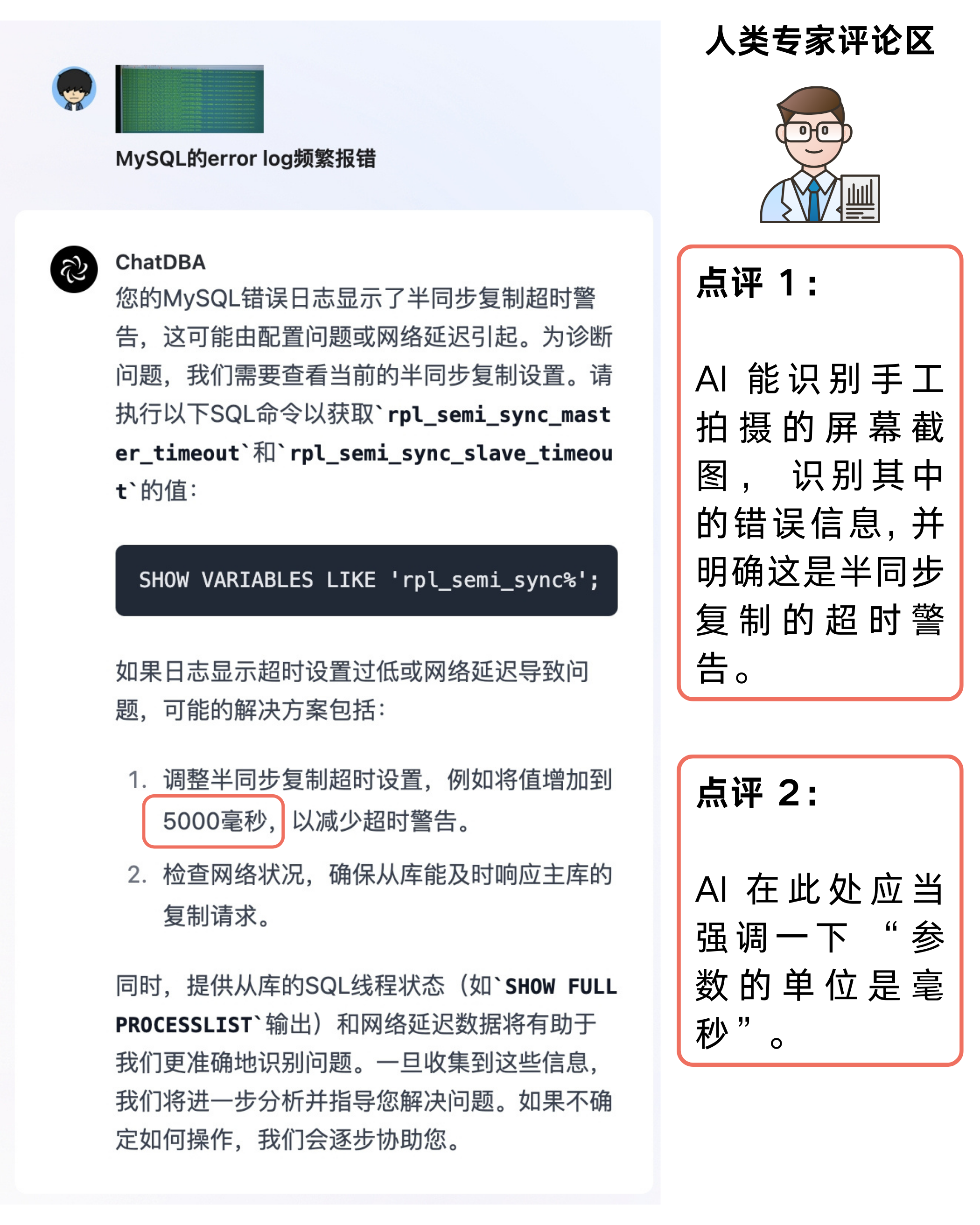
MySQL 的 error log 频繁报错
在 DBA 日常工作场景中经常会遇到业务方的如下行为:
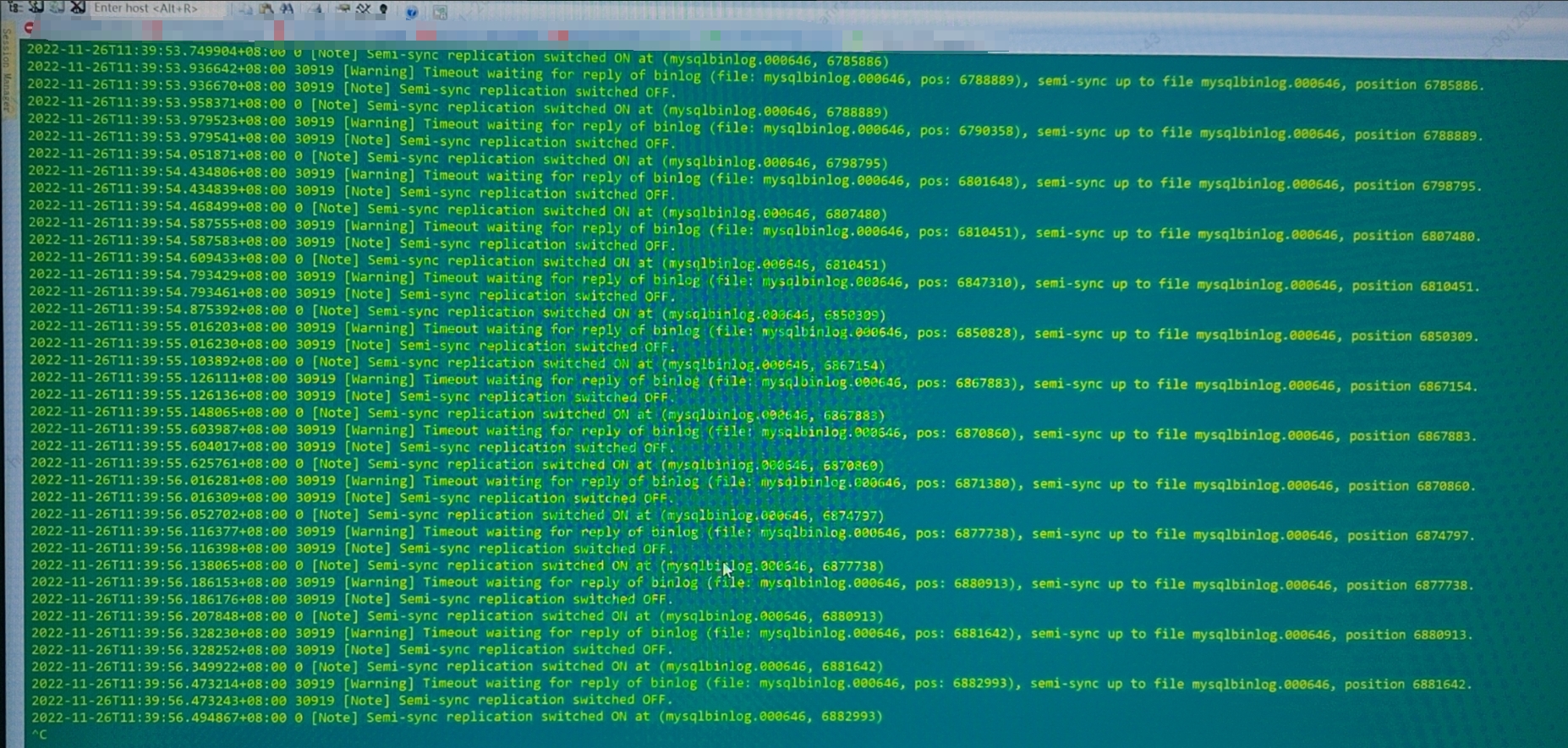
![]()
从图片里面可以看到错误日志里面出现了很多的报错信息:
![]()
实验
1. 将问题丢给 ChatDBA
![]()
我们先把这个问题丢给 ChatDBA,让他看下具体出了什么问题。
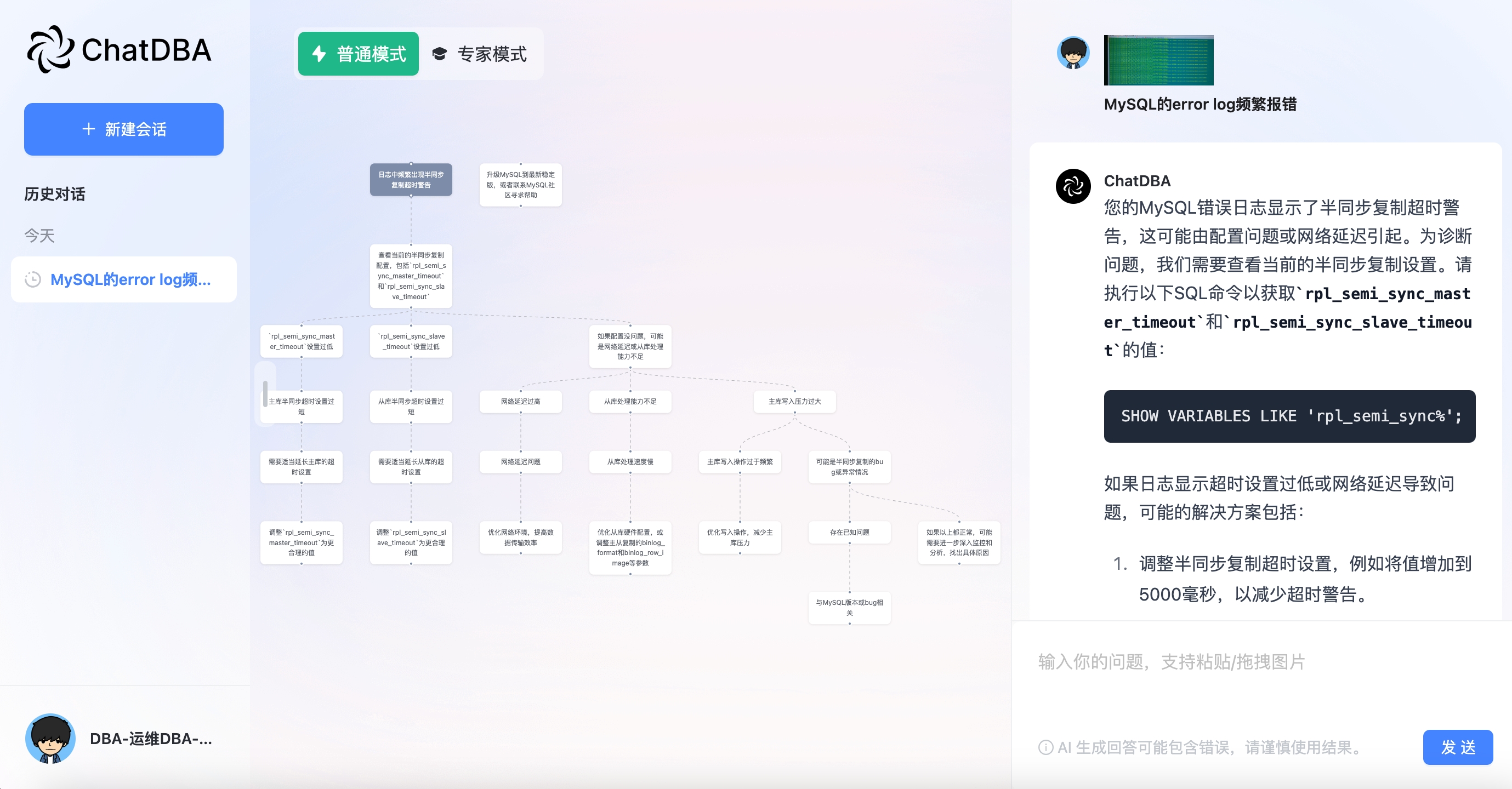
![]()
左侧为流程分析画布,展示 ChatDBA 对此问题的排查逻辑;右侧为互动区域
从左侧的问题逻辑图可以看到,ChatDBA 通过分析图片中的报错信息认为最有可能得原因是因为参数配置的问题导致的,其次是网络延迟或者写入压力比较大。
2. ChatDBA 协助问题排查
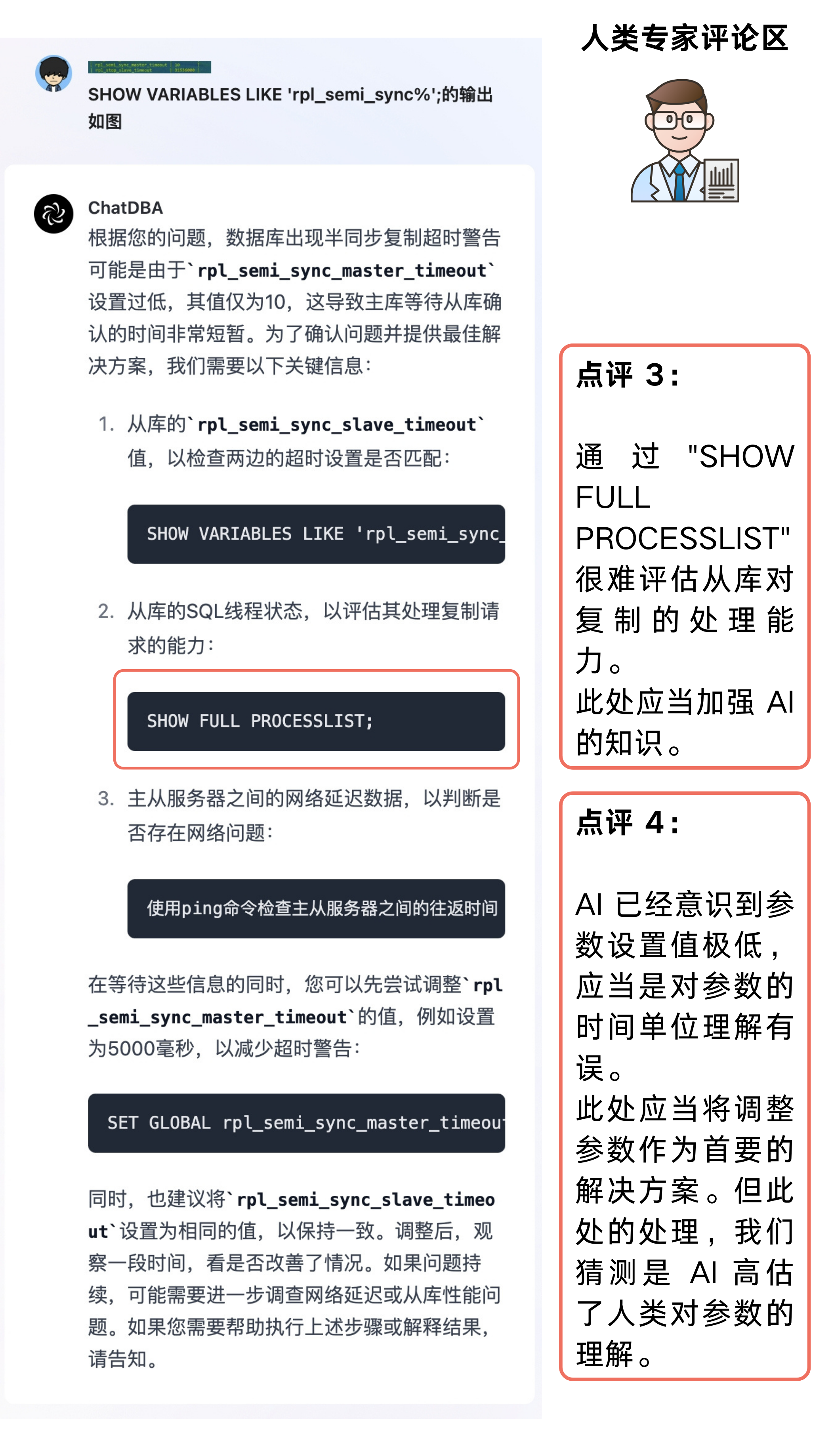
根据对应的排查逻辑,ChatDBA 首先希望获取到对应的参数配置。
![]()
在这里我们给了ChatDBA 一个通过 show variables like '%timeout%' 命令返回结果的部分截图。
![]()
再次输入给 ChatDBA。
3. ChatDBA 给出解决方案
![]()
ChatDBA 识别出其中参数的配置是 10ms,这个值对于此场景下过小了,所以需要调整其为更大的值,这个小问题就顺利解决了。
4. 实验总结
从日志的报错信息可以看到 MySQL 半同步复制在不断切换状态,并且多次遇到等待 binlog 回复超时的情况,此问题大概率的原因有以下几种:
- 配置问题
- 原因:MySQL 的半同步复制配置不当,导致超时设置过短。
- 解决方法:检查半同步复制相关的配置参数,例如 rpl_semi_sync_master_timeout,适当增加超时时间。
- 网络延迟或不稳定
- 原因:主从服务器之间的网络不稳定会导致 binlog 传输延迟或丢失。
- 解决方法:检查和优化网络连接,确保主从服务器之间的网络稳定性。
- 从服务器负载过高
- 原因:从服务器的负载过高,无法及时处理主服务器发送的 binlog。
- 解决方法:检查从服务器的性能,可能需要增加资源或优化查询。
- 主服务器问题
- 原因:主服务器在生成 binlog 或发送 binlog 时出现问题。
- 解决方法:检查主服务器的性能和错误日志,确保其运行正常。
配置与网络情况相对比较好排查,可以从这两处入手快速去排查问题原因,再逐步深入。
问问 Gemini
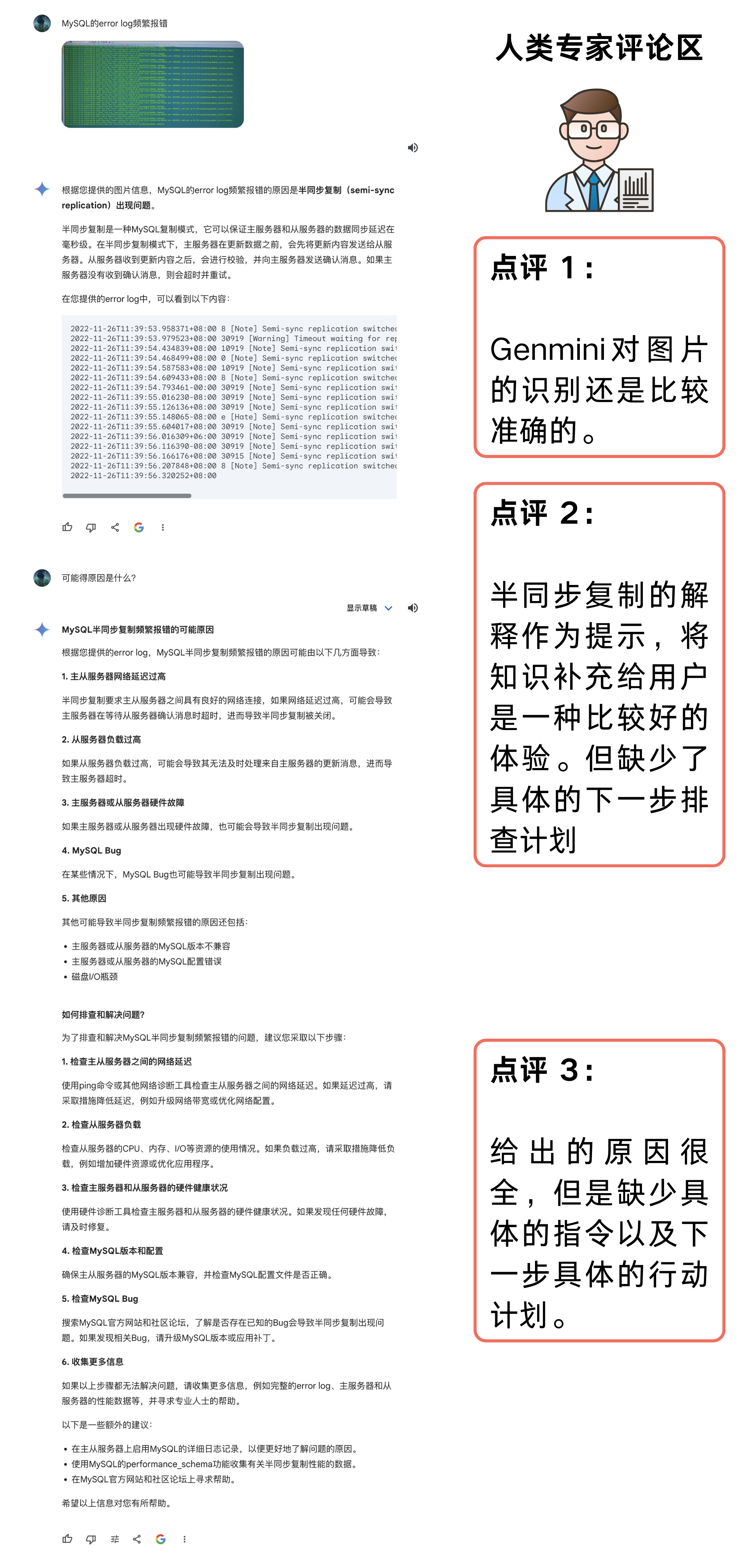
我们也将相同的问题送给了 Gemeni,让我们看看效果如何。
![]()
我们将这个问题分别送给了 ChatGPT-4o 与 Gemini,ChatGPT-4o 回答的效果与 ChatDBA 相当,但是 Gemini 的回答比较奇怪,虽然他也准确的识别出了对应图片的内容,但是只是总结了一下并没有做过多解释,当我们进行追问的时候发现他回答了多种原因,但是每个原因还是缺少具体指向性的操作,从而解决问题。
什么是 Chat DBA?
![]()
更多技术文章,请访问:https://opensource.actionsky.com/
关于 SQLE
SQLE 是一款全方位的 SQL 质量管理平台,覆盖开发至生产环境的 SQL 审核和管理。支持主流的开源、商业、国产数据库,为开发和运维提供流程自动化能力,提升上线效率,提高数据质量。
SQLE 获取