源自北京大学软件工程研究所的 aiXcoder 团队宣布,推出全新自研 aiXcoder-7B 代码大模型;聚焦真实开发场景,专为企业私有部署设计。其中,aiXcoder-7B Base 版将开源共享给开发者,并陆续在 Github、Gitee、Gitlink 等平台上线。
公告称,在多个主流评估标准评测集中,无论是代码生成、代码补全还是跨文件上下文代码生成效果,aiXcoder-7B模型均有极佳表现,甚至超越参数量大5倍的34B代码大模型,已达到当前SOTA水准,堪称最适于实际编程场景的基础模型。
![]()
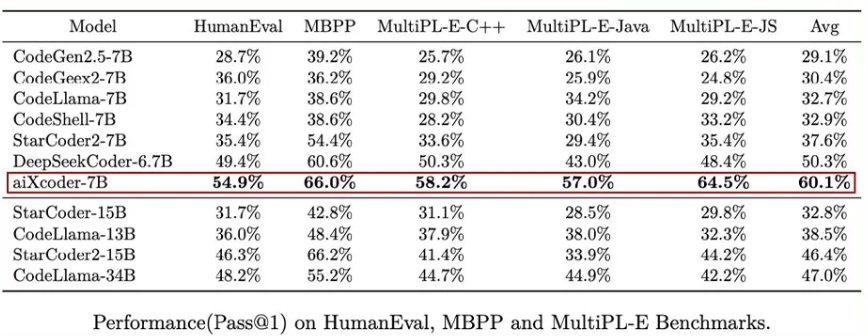
在 HumanEval(由 164道Python编程问题组成)、MBPP(由974个 Python编程问题组成)和 MultiPL-E(包含了18种编程语言)等主流代码生成效果评估测试集上,aiXcoder 7B 准确率显著超越当前同级别代码大模型。
![]()
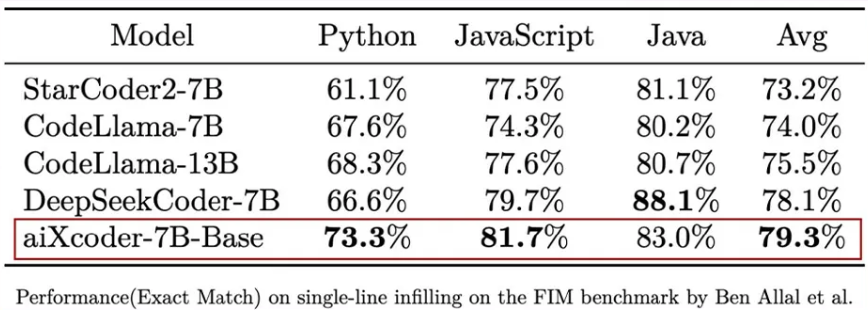
在Santacoder(Ben Allal et al., 2023) 提出的考虑上下文补全评测集上,aiXcoder-7B Base版在与 StarCoder 2、CodeLlama 7B/13B、DeepSeekCoder 7B 等主流同量级开源模型的较量中取得了综合最佳效果。
![]()
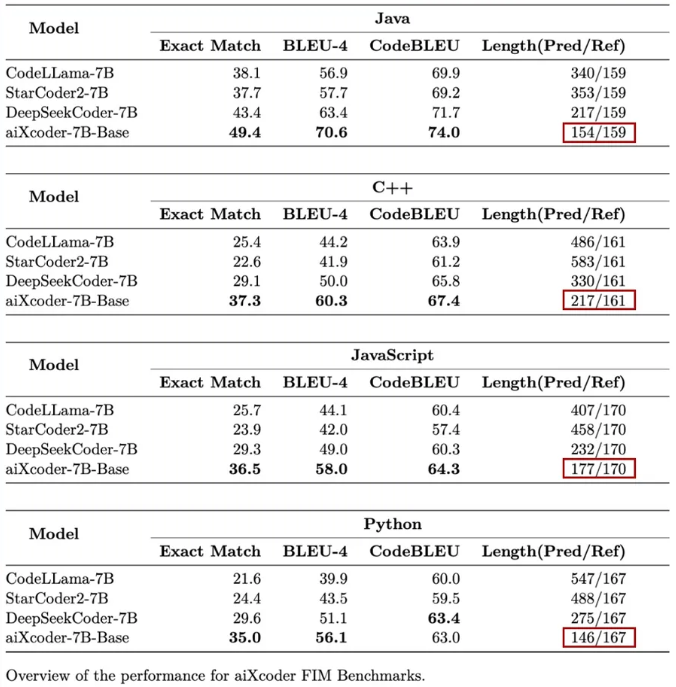
为了进一步精细地评测代码大模型在代码补全上的能力,aiXcoder 构建了一个比SantaCoder数据量更大,被测代码多样性更高、被测代码上下文长度更长、更接近实际开发项目的评测集 (16000多条来自真实开发场景的数据),在此测评集上aiXcoder-7B 同样效果最好。
同时aiXcoder-7B 表现出了相较于其他代码大模型的又一大亮点,即倾向于使用较短代码来完成用户指定的任务。在针对Java、C++、JavaScript和Python编程语言的代码补全测评时,aiXcoder 7B Base不仅效果最好,四处红框圈出的生成答案长度明显短于其他模型,并且非常接近于标准答案长度(Ref)。
![]()
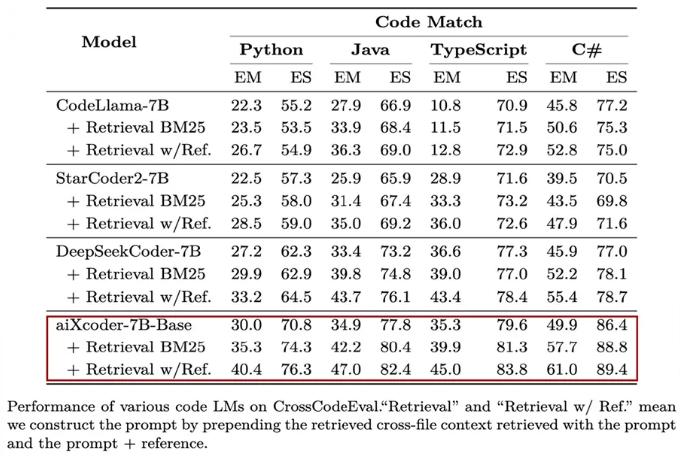
在 CrossCodeEval 测评集上,aiXcoder-7B一举拿下了同级别模型的最好效果:
![]()
在真实开发场景中,aiXcoder-7B模型具有更多优势。比如预训练采用32K token的上下文长度,并且推理时可扩展至256K,能覆盖整个开发项目中的绝大部分代码;可准确判断何时需要生成新代码、何时代码逻辑已完整无需补全,直接生成完整的代码块、方法体、控制流程;可以准确地抽取项目级的上下文信息,大大降低大语言模型在预测API时产生的幻觉。
aiXcoder-7B模型训练集涵盖1.2T Unique token数据,覆盖数十种主流编程语言。aiXcoder团队在构建训练数据时,针对数十种主流编程语言进行了语法分析,过滤掉错误的代码片段,还对十多种主流语言的代码进行了静态分析,总共剔除了163种bug和197种常见代码缺陷,确保了训练数据的高质量。
为了增强模型对代码语义和结构的建模能力,aiXcoder团队采取了多种创新策略。一方面利用代码聚类和函数调用关系图的方式,捕捉多个文件之间的相互注意力关系;另一方面,将抽象语法树的结构信息融入了预训练任务中,帮助模型学习代码的语法和模式特征。
总体而言,测评发现 aiXcoder-7B 在考虑代码项目上下文这种更真实开发场景下,具有当前代码大模型中最佳的效果。