号称平替甚至超越 ChatGPT 的产品层出不穷,今天就来做一个横向评测。本次评测的对象有:
- ChatGPT 3.5
- ChatGPT 4
- Google Gemini
- Anthropic Claude 3 Sonnet
- Perplexity
- devv
- 月之暗面 Kimi Chat
评测方法很简单:
- 打开一个新会话
- 提问 What is Bytebase
![]()
挑这个问题的原是因为我们最了解这个主题,只有这样,才能通过细节判定高下。大家也可以根据自己的主题进行验证。好,下面进入正题。
![file]()
ChatGPT 3.5
![file]() 比较简短,基本也对。但是「Organize, document, and share their databases, schemas, and related documentation」这句是 AI 自己提炼的总结,过度发挥了。这里把 Bytebase 描述成了一个数据库文档工具,不过后面一句话又掰回来了。
比较简短,基本也对。但是「Organize, document, and share their databases, schemas, and related documentation」这句是 AI 自己提炼的总结,过度发挥了。这里把 Bytebase 描述成了一个数据库文档工具,不过后面一句话又掰回来了。
ChatGPT 4
![file]() 比 3.5 要丰富很多,不过有两个问题:
比 3.5 要丰富很多,不过有两个问题:
- 没有抓住对象。应该点出针对 Developer 和 DBA。
- 出现了一个幻觉,Bytebase 并不支持 SQLite。也可能是被官网其他地方迷惑了,我们博客上还是有一些 SQLite 内容。
![file]()
![file]()
Google Gemini
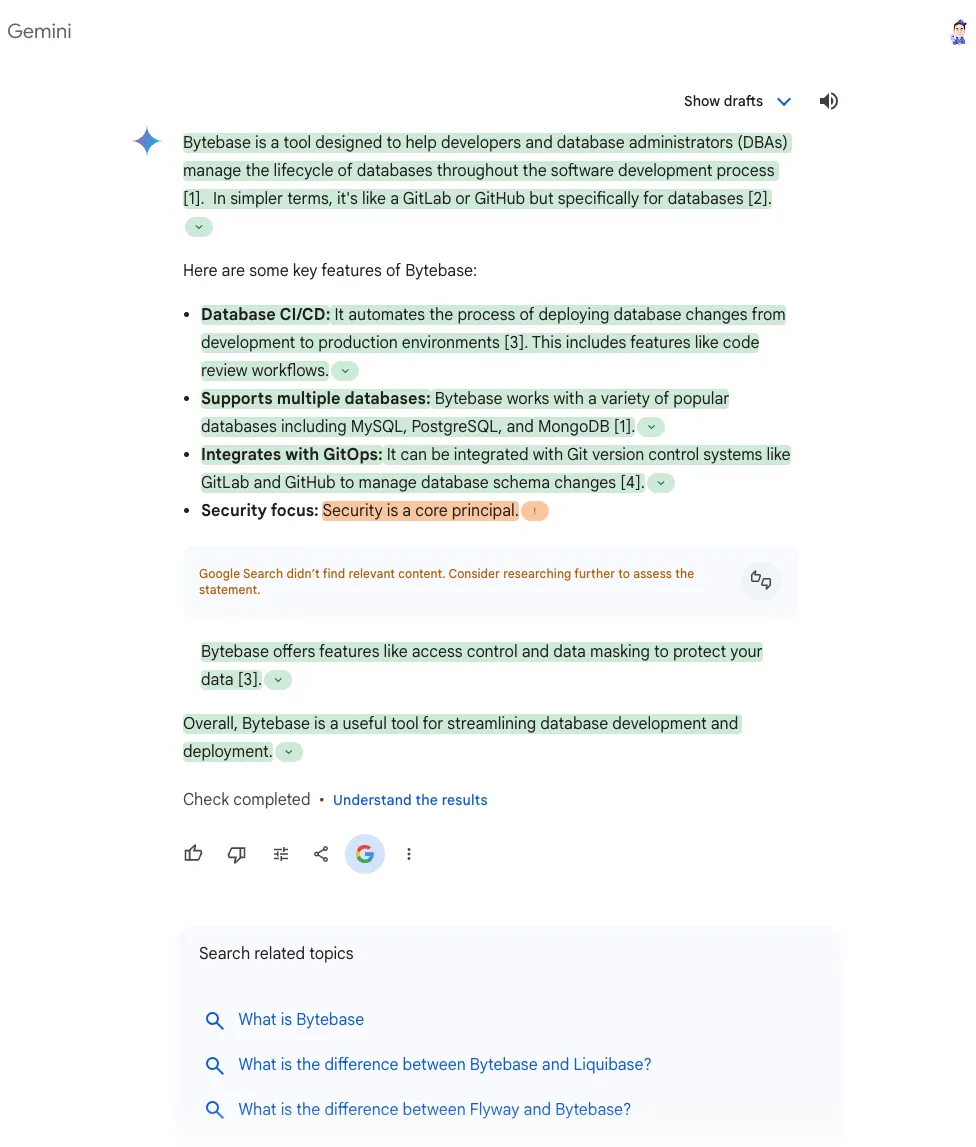
![file]() Gemini 的总结重点抓得很准。我是谁,干什么,卖给谁都提炼了重点,恰到好处。还提供了每一行的出处。给人一种信任感。
Gemini 的总结重点抓得很准。我是谁,干什么,卖给谁都提炼了重点,恰到好处。还提供了每一行的出处。给人一种信任感。
Anthropic Claude 3 Sonnet
![file]() 这个幻觉的有点过了,第一句话就问题很多。把我们描述成了一个偏 BI 的工具,是不是把我们和 Metabase 搞混了 (“▔□▔)。虽然没有充值,所以用的 Claude 3 Sonnet 是一个乞丐版。但是相比 ChatGPT 3.5,还是错的有点多。普通为什么又那么自信?
这个幻觉的有点过了,第一句话就问题很多。把我们描述成了一个偏 BI 的工具,是不是把我们和 Metabase 搞混了 (“▔□▔)。虽然没有充值,所以用的 Claude 3 Sonnet 是一个乞丐版。但是相比 ChatGPT 3.5,还是错的有点多。普通为什么又那么自信?
Perplexity
![file]() 用了它的 Pro Search 模式,也是根据网站提炼的。但确实提炼的也很不错,也和 Gemini 一样,提供了内容的出处。不过还是稍稍出了点幻觉,「the use of machine learning and AI technologies to optimize migration processes and schema improvements」。后半部分的 schema improvements 确实有集成了 AI 的慢 SQL 优化,但前半的 optimize migration processes 并没有用 AI。
用了它的 Pro Search 模式,也是根据网站提炼的。但确实提炼的也很不错,也和 Gemini 一样,提供了内容的出处。不过还是稍稍出了点幻觉,「the use of machine learning and AI technologies to optimize migration processes and schema improvements」。后半部分的 schema improvements 确实有集成了 AI 的慢 SQL 优化,但前半的 optimize migration processes 并没有用 AI。
devv
![file]() devv.ai 从名字上也能看出来,是一个针对研发场景的 ChatGPT 类产品。devv 的界面和 Perplexity 比较类似,提炼的内容比 Perplexity 更加全面,重点都覆盖到了,也没有看到幻觉。devv 的回答没有 Perplexity 里提及的 AI 内容,不知道是否是索引时间的原因。其实没有包括是对的,因为 Bytebase 的 AI 功能相比于 devv 列出来的几条来说,重要度是更低的。devv 相比 Perplexity 欠缺的是对于内容出处的注解。
devv.ai 从名字上也能看出来,是一个针对研发场景的 ChatGPT 类产品。devv 的界面和 Perplexity 比较类似,提炼的内容比 Perplexity 更加全面,重点都覆盖到了,也没有看到幻觉。devv 的回答没有 Perplexity 里提及的 AI 内容,不知道是否是索引时间的原因。其实没有包括是对的,因为 Bytebase 的 AI 功能相比于 devv 列出来的几条来说,重要度是更低的。devv 相比 Perplexity 欠缺的是对于内容出处的注解。
Image月之暗面 Kimi Chat
![file]() 最后再测试一下最近很火的月之暗面 Kimi Chat。Kimi 的推广力度很大,现在 B 站上,到处是它的广告 (¬_¬) 。
最后再测试一下最近很火的月之暗面 Kimi Chat。Kimi 的推广力度很大,现在 B 站上,到处是它的广告 (¬_¬) 。
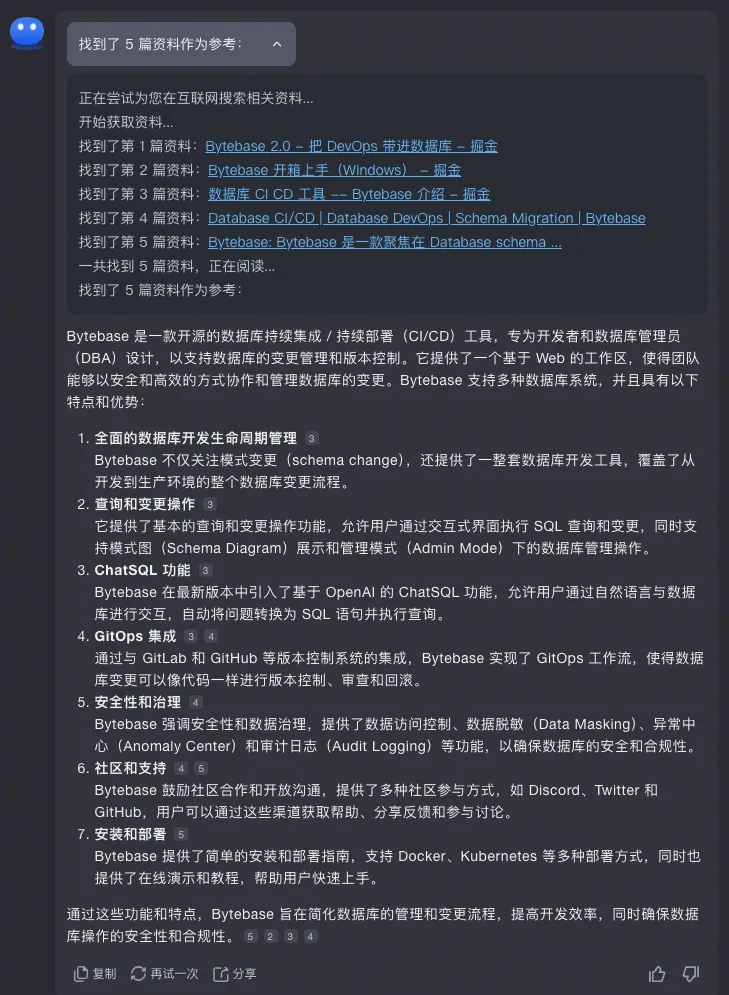
首先 Kimi 和前面几家不同的,即时我用了英文提问,他还是用中文回答的,充分表明了自己的立场。整体总结的也比较好。没有出现幻觉,也能给出引用。但 Kimi 也有一个问题,就是它是根据 5 篇资料生成的。所以选的资料不同,回答的侧重点就完全不同了。下面我又试了一次,因为参考资料不同,就形成了差异不小的回答。
![file]()
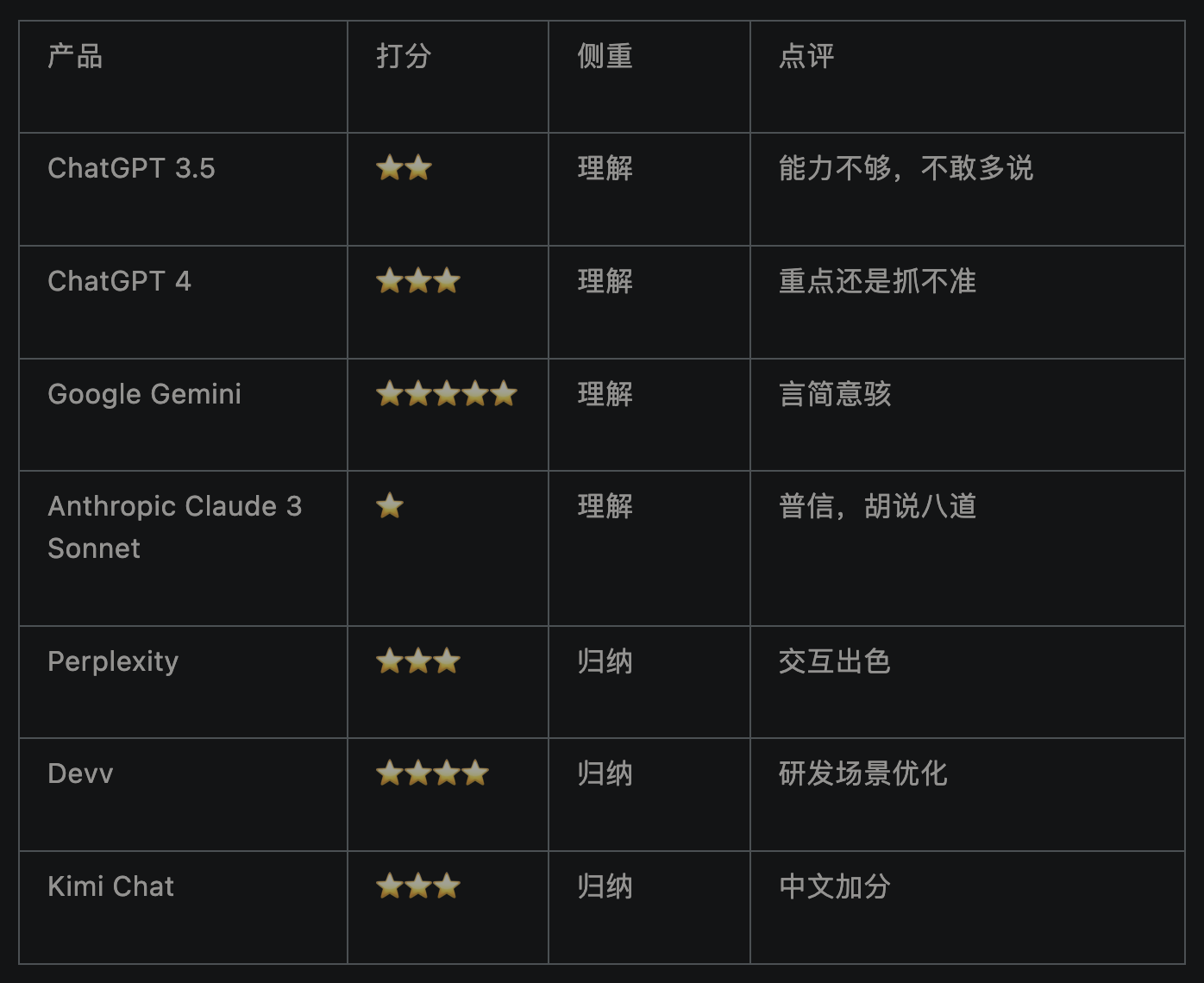
总结
![file]()
通过交互的感受,把产品分成了两大侧重类型,归纳型和理解型。所谓归纳型,主要工作是聚合。所谓理解型,是在聚合基础上更多形成了自己的想法。当然归纳也需要理解,但程度不同。举个可能不太恰当的例子,就像周报的汇总,小组长可以提取组员的要点汇总上去(归纳型),也可以阅读完组员的后自己写一份新的(理解型)。
针对「What is Bytebase」这个问题,这次评测下来我个人觉得最好的是 Google Gemini,它做到几点:
- 没有废话,抓住了所有核心点。
- 没有出现幻觉。
- 给出了引用,给人信任感。
Devv 的表现也不错,额外期望的是加上类似 Gemini / Perplexity 这样的 inline 出处注解。Kimi 的表现中规中矩,中文加分。
这次只是一个简单的测试,所以结论肯定是片面的。理解型和归纳型的分类也不太严谨,可能理解型听上去更加高大上,但从效果上来说,理解型未必就比归纳型要好。理解型因为夹带了自己的私货,就容易出现幻觉,严重的像 Claude 3 Sonnet 这样有点胡说八道了。但这一年 AI 的发展之快是有目共睹的,之前让人惊艳的 ChatGPT 3.5 现在看已经落伍了。
AI 一天,人间一年。
💡 更多资讯,请关注 Bytebase 公号:Bytebase


 比较简短,基本也对。但是「Organize, document, and share their databases, schemas, and related documentation」这句是 AI 自己提炼的总结,过度发挥了。这里把 Bytebase 描述成了一个数据库文档工具,不过后面一句话又掰回来了。
比较简短,基本也对。但是「Organize, document, and share their databases, schemas, and related documentation」这句是 AI 自己提炼的总结,过度发挥了。这里把 Bytebase 描述成了一个数据库文档工具,不过后面一句话又掰回来了。 比 3.5 要丰富很多,不过有两个问题:
比 3.5 要丰富很多,不过有两个问题:
 Gemini 的总结重点抓得很准。我是谁,干什么,卖给谁都提炼了重点,恰到好处。还提供了每一行的出处。给人一种信任感。
Gemini 的总结重点抓得很准。我是谁,干什么,卖给谁都提炼了重点,恰到好处。还提供了每一行的出处。给人一种信任感。 这个幻觉的有点过了,第一句话就问题很多。把我们描述成了一个偏 BI 的工具,是不是把我们和 Metabase 搞混了 (“▔□▔)。虽然没有充值,所以用的 Claude 3 Sonnet 是一个乞丐版。但是相比 ChatGPT 3.5,还是错的有点多。普通为什么又那么自信?
这个幻觉的有点过了,第一句话就问题很多。把我们描述成了一个偏 BI 的工具,是不是把我们和 Metabase 搞混了 (“▔□▔)。虽然没有充值,所以用的 Claude 3 Sonnet 是一个乞丐版。但是相比 ChatGPT 3.5,还是错的有点多。普通为什么又那么自信?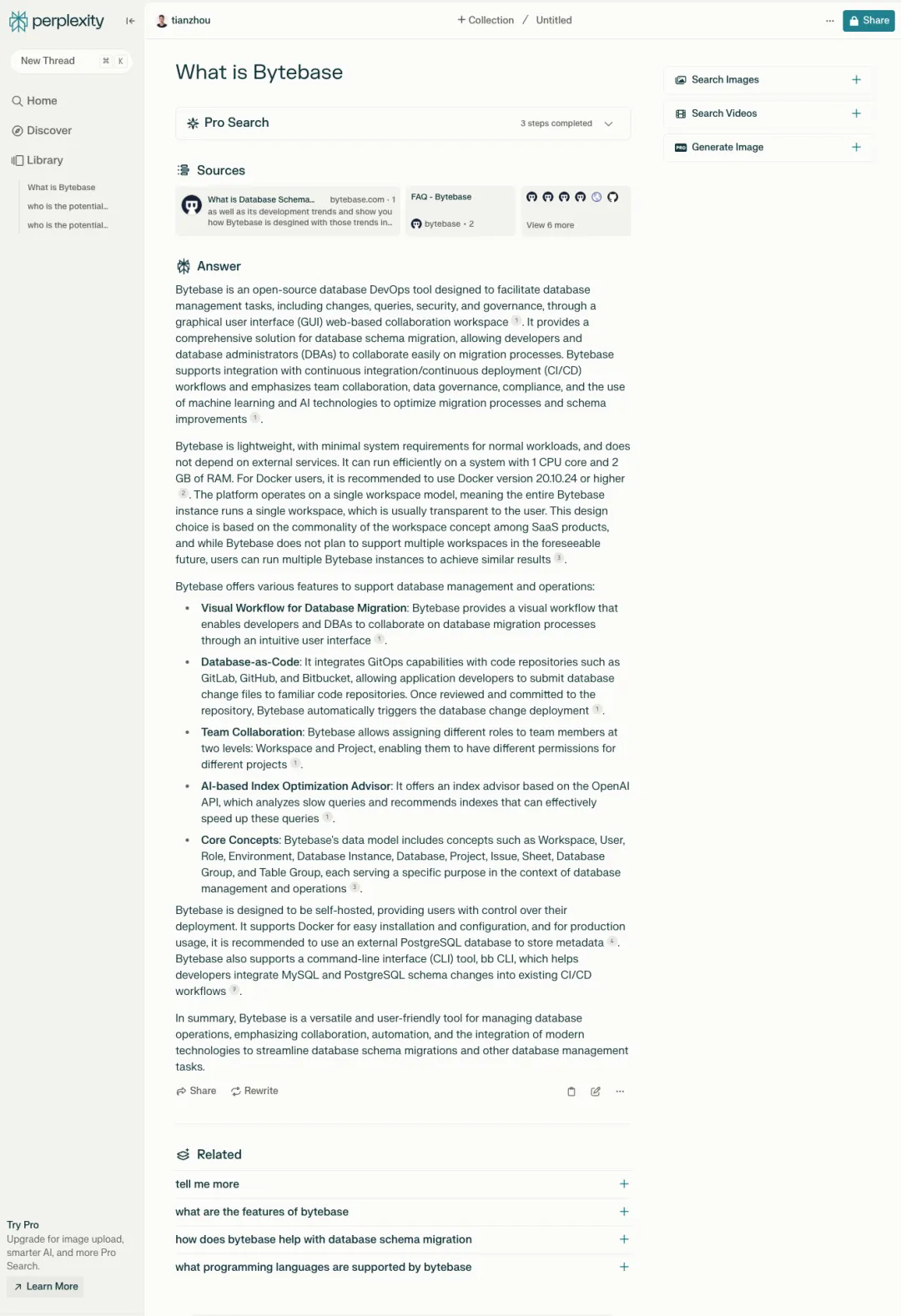 用了它的 Pro Search 模式,也是根据网站提炼的。但确实提炼的也很不错,也和 Gemini 一样,提供了内容的出处。不过还是稍稍出了点幻觉,「the use of machine learning and AI technologies to optimize migration processes and schema improvements」。后半部分的 schema improvements 确实有集成了 AI 的慢 SQL 优化,但前半的 optimize migration processes 并没有用 AI。
用了它的 Pro Search 模式,也是根据网站提炼的。但确实提炼的也很不错,也和 Gemini 一样,提供了内容的出处。不过还是稍稍出了点幻觉,「the use of machine learning and AI technologies to optimize migration processes and schema improvements」。后半部分的 schema improvements 确实有集成了 AI 的慢 SQL 优化,但前半的 optimize migration processes 并没有用 AI。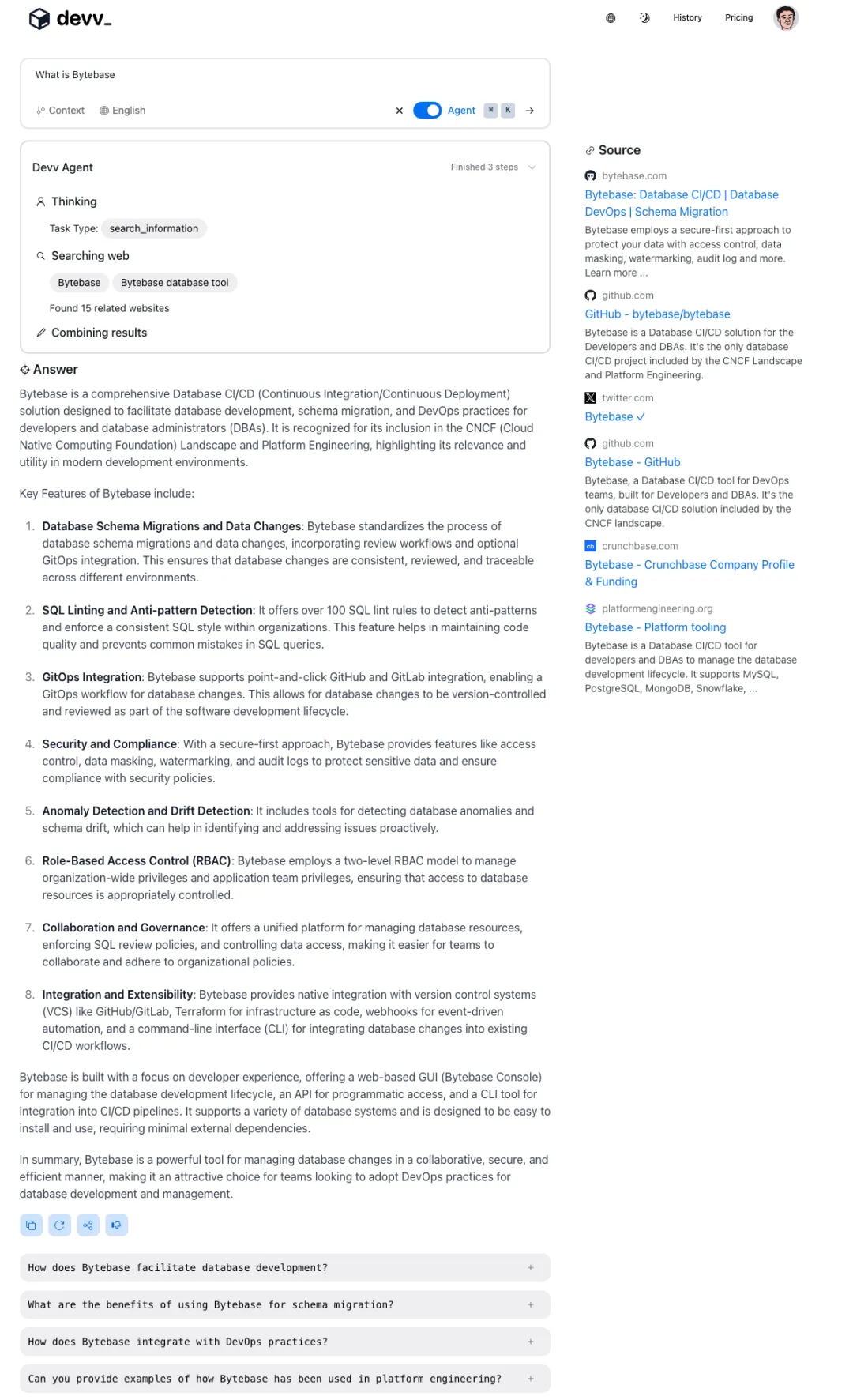 devv.ai 从名字上也能看出来,是一个针对研发场景的 ChatGPT 类产品。devv 的界面和 Perplexity 比较类似,提炼的内容比 Perplexity 更加全面,重点都覆盖到了,也没有看到幻觉。devv 的回答没有 Perplexity 里提及的 AI 内容,不知道是否是索引时间的原因。其实没有包括是对的,因为 Bytebase 的 AI 功能相比于 devv 列出来的几条来说,重要度是更低的。devv 相比 Perplexity 欠缺的是对于内容出处的注解。
devv.ai 从名字上也能看出来,是一个针对研发场景的 ChatGPT 类产品。devv 的界面和 Perplexity 比较类似,提炼的内容比 Perplexity 更加全面,重点都覆盖到了,也没有看到幻觉。devv 的回答没有 Perplexity 里提及的 AI 内容,不知道是否是索引时间的原因。其实没有包括是对的,因为 Bytebase 的 AI 功能相比于 devv 列出来的几条来说,重要度是更低的。devv 相比 Perplexity 欠缺的是对于内容出处的注解。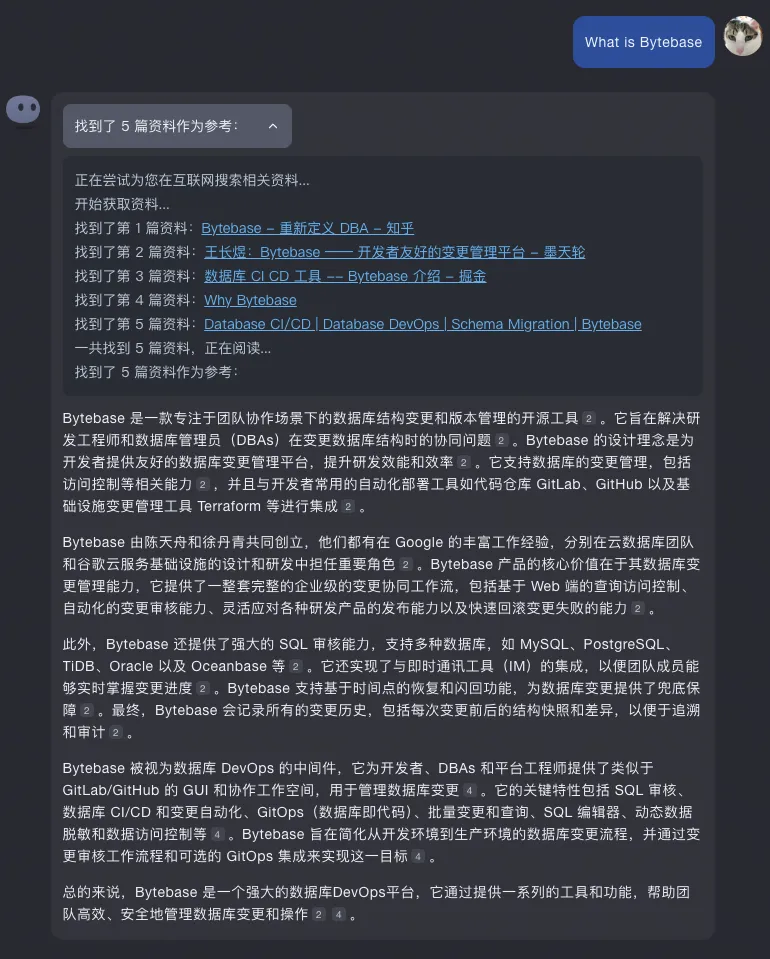 最后再测试一下最近很火的月之暗面 Kimi Chat。Kimi 的推广力度很大,现在 B 站上,到处是它的广告 (¬_¬) 。
最后再测试一下最近很火的月之暗面 Kimi Chat。Kimi 的推广力度很大,现在 B 站上,到处是它的广告 (¬_¬) 。