作者:饭饭
一、监控搭建
openGemini 测试版本:v1.2
1. 关键监控指标的选取
搭建⼀个好的监控系统可以更好地帮助我们去发现和定位问题,使⽤官⽅推荐的Gemix⼀键部署可以⾃动帮你搭建Grafana,并且官⽅提供很详细的监控模板,可以接⼊openGemini的监控。
手动搭建参考:如何快速搭建openGemini运行状态的实时监控系统
监控模板:
https://github.com/openGemini/gemix/tree/main/embed/templates/dashboards
以下⼏个点是出现写⼊异常能最直观快速发现异常点的⼏个关键监控数据
系统类:CPU、内存、磁盘容量、磁盘IO
读写类:集群流量、store写并发、SQL/Store写延迟、写Wal时延、SQL/Store写QPS、写Memtable时延
压缩合并类:乱序时间线占⽐、平均乱序⽂件、Compact耗时、乱序合并耗时、乱序⽂件总数
2. 异常指标样例
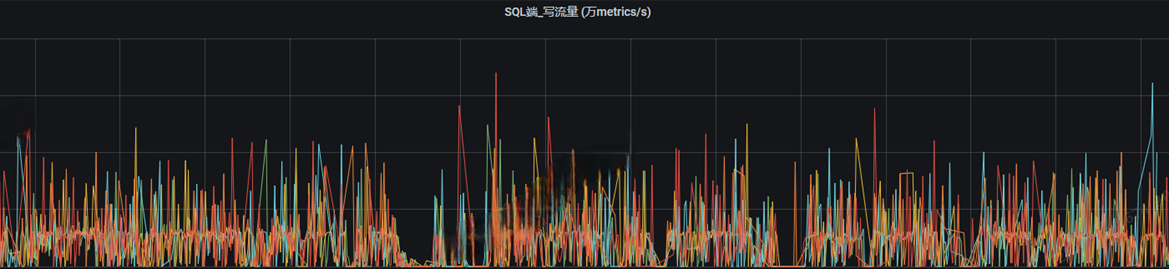
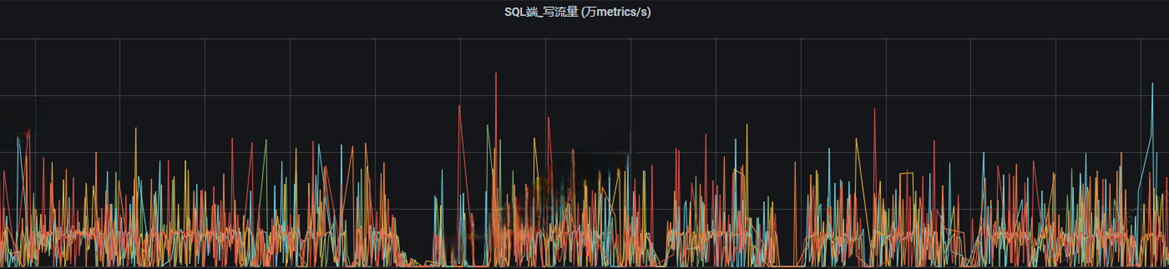
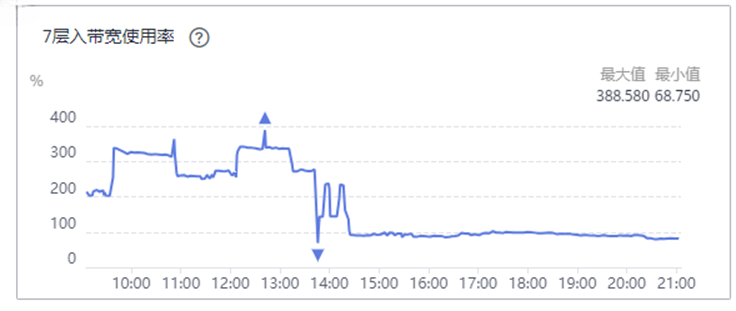
异常的写⼊曲线:
![]()
![]()
异常曲线不论是sql还是store,写流量的波峰和波⾕浮动很⼤,并且不论是sql、store、wal写时延都⾮常的⾼,这就代表写⼊有很⼤部分的时间在阻塞,性能遇到了瓶颈,需要我们进⾏优化。
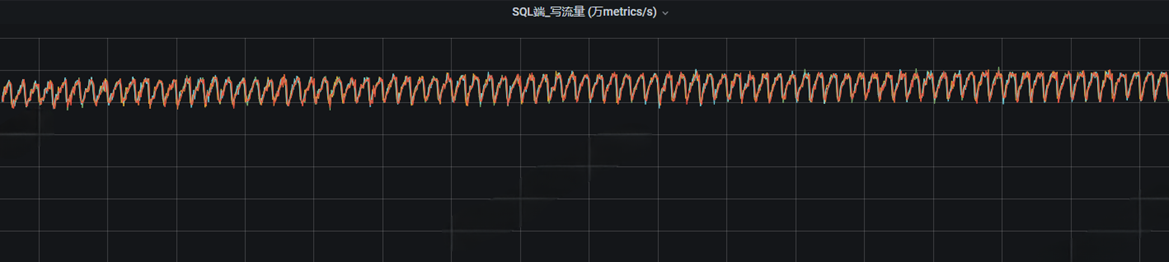
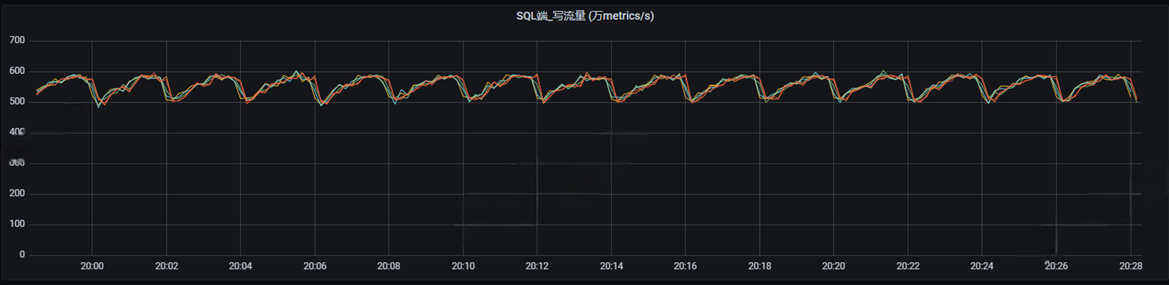
⽽正常的写⼊曲线是⼀个很平稳很稳定的⼀条线:
![]()
二、client端写入优化
1. Tag的选择
尽量选择平稳和基数少的指标作为你的Tag。
基数少:如果Tag基数过⼤会影响写⼊和查询效率,并且如果是多个Tag的模式会导致时间线以成倍的数量暴增。所以在选取字段做Tag的时候要考虑基数问题。
平稳:通常设备id或者传感器id⼀旦上线,不会在短时间内出现⼤量新tag的插⼊。所以在选择tag的时候也要考虑不能频繁的更新和插⼊新的Tag。
2. ts-sql负载均衡
有两种选择,一种是使用代理,另一种为SDK自带的负载均衡功能。
使⽤代理:
使⽤Nginx、云上弹性负载服ELB或者其它负载均衡器在ts-sql上做⼀层代理,使得与openGemini的请求能平均的请求到tssql节点上,避免单ts-sql成为性能瓶颈。
使⽤社区开源SDK:
openGemini官方自研的SDK全部规划了负载均衡功能,但目前仅Go-Client已发布了版本。其他语言还在开发中。若使用InfluxDB 的SDK,需要自己实现。
所以不管使⽤哪种⼯具,最终的结果就是要请求平均访问带每个ts-sql上:
![]()
值得注意的是,当你引入负载均衡器,其实相当于引入一个新的组件,所以引入的负载均衡器的性能也有可能导致写入变慢或者不稳定,所以可以重点关注如下一些指标:
![]()
3. INSET BATCHSIZE 参数配置
批量写入是提升数据写入效率的最直接方法,但并非单批次写入的数据越多越好,因为数据库的处理能力是一定的。然而硬件配置的不同,往往无法给出具体的Batchsize大小建议。
Insert Batchsize大小配置:
不论是Influx-java还是社区的opengemini-client,都提供了批量提交参数 batchsize 和 flushDuration,根据每行的列数和数据量可以多次尝试一个合适的batchsize来实现写入性能的最优,如果列很多,不推荐每批写入数据的过多,batchsize一般设置为500,800,1000,2000,4000进行尝试,来选取最适合自己的写入批次。
开启压缩:
开启压缩在大批量数据写入的时候有可能也可以提升写的效率,influx-java通过influxDB.enableGzip();开启写入压缩。
三、Wal写⼊瓶颈
使用了官方默认参数开始压测写入数据,然后观察写入指标是否正常,主要观察如下几个指标:
-
cpu & 内存使用率
-
sql & store写流量
-
sql & store写时延
一开始表现为写时延非常的高,并且伴随着写流量波动非常大
![]()
其实写流量波动和写时延是息息相关的,写时延小自然写流量就稳定,写时延大自然写流量波动就大。
客户端报的错也都是select timeout in 10s seconds 或者 timeout超时的错误提示,所以第一时间想到的就是修改shard-writer-timeout等类似超时参数,其实这就步入了一个误区,当你的集群吞吐上不去的时候,超时参数改的再大只能增加集群的容错性,最终因为集群吞吐量和集群io跟不上报超时异常也只是时间早晚的问题,不能从根本去解决问题。
最后通过观察指标发现写wal的时延异常的高:
![]()
WAL是openGemini在写入业务数据之前的预写日志,为了防止服务器宕机或者进行异常退出的时候数据丢失而做的可靠性策略。
而写入一条数据的时延 = 写wal时延 + 写store时延。比如写wal耗时2s,写store时延80μs,那么些一条数据的耗时就是2s + 80μs,数据写入是串行进行的,先写wal,在写store,所以写Wal耗时过高是一种非常影响写性能的一个现象。
所以下面有两种方案可以对此现象进行优化:
1. 关闭WAL,验证瓶颈点
修改ts-store的data配置
[data]wal-enabled = false
关闭wal之后,wal时延监控一栏时间明显大幅度降低,并且sql和store写入时延降低,写入速率变得平稳,由此可以判断引起写入波动的原因是在WAL这里。
2. WAL文件目录单独挂盘
作为保证数据不丢失的重要功能,基本上都会开启Wal功能,开启Wal的情况下,建议如下:
[data]wal-enabled = truestore-data-dir = ""store-wal-dir = ""
因为我们store盘的I/O是非常强大的,并且性能没有拉满,所以当时的想法就是store和wal共用一块磁盘。但是实际效果不是很理想,但是通过监控发现其实磁盘的写入速率还有I/O都不存在任何瓶颈,但是为啥速率上不去呢。
因为wal和store数据如果共用一块盘,在大量写入数据的时候,WAL和数据都会频繁写文件,存在磁盘I/O竞争关系,磁盘需要在两个请求之间来回切换,所以同样也会导致wal写入过慢,从而整体影响store的写入时延。
所以store-data-dir 和 store-wal-dir的写入磁盘强烈建议分开,就算你的一块磁盘的性能还剩余很多,也强烈不建议把store-data-dir 和 store-wal-dir放在一个磁盘路径下。
因为数据写入时延 = 写wal时延 + 写store时延,所以在store时延固定的情况下,同样建议wal写入的磁盘同样使用高I/O高性能磁盘降低wal写入时延,从而降低数据写入时延。
四、磁盘io瓶颈
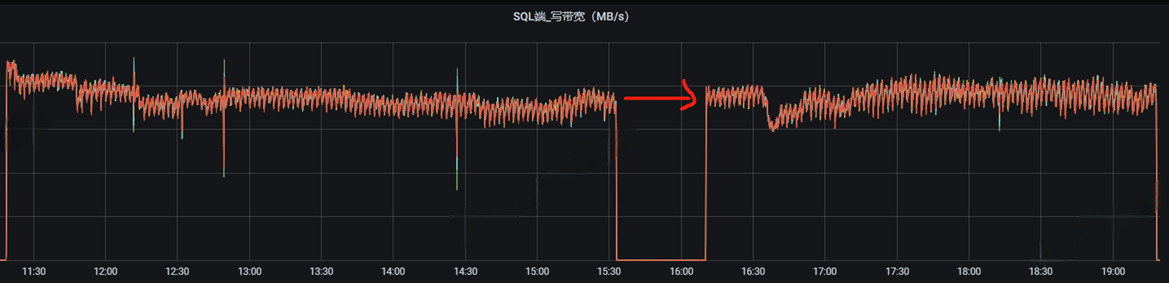
Wal时延优化了之后,随着进行数据量的不断压测,写store的时延还在持续增加,写入波动持续增大,但是机器的cpu和内存还有盈余,这时候就考虑是store所在磁盘I/O的瓶颈。
![]()
![]()
磁盘的I/O使用率一直在100%左右徘徊,解决这个问题也很简单,把Store的写磁盘直接上高吞吐量,使用高I/O的硬盘。
五、内存配置 & 吞吐量调优
Wal瓶颈和磁盘I/O瓶颈解决之后,在一定数据量范围内可以写入平稳,但是内存和cpu仍然没有完全使用,并且稍微数据量稍微再上调一点就变得十分不稳定。
![]()
因为Wal写时延和store写时延我们通过上述调优已经非常完美了,所以这时候就考虑是不是openGemini的默认参数,比如内存,吞吐量配置和我们集群规模不匹配导致集群不能充分发挥他的特性。
当前虚拟机规格为16U64GB,经过与社区的沟通和讨论,将参数做出如下的修改:
shard-mutable-size-limit = "1g"
单个shard中写数据缓存大小限制上调到1GB,默认值: memorySize/256,并强制介于 8MB - 1GB 之间。
node-mutable-size-limit = "16g"
节点中写数据缓存大小限制上调到16GB,默认值: memory-size/16,并强制介于 32MB - 16GB 之间。
snapshot-throughput = "300m"
snapshot-throughput-burst = "300m"
缓存加大,需要随之调整系统刷盘带宽,否则依然不起作用。写数据流程是先写wal然后写mutable,再等待刷盘,snapshot-*参数负责数据刷盘的流控,控制磁盘I/O带宽的,当前上调到300MB。
因为我们集群内存比较充裕,并且磁盘I/O还有盈余,所以我们配置的值都是比较大的,可以根据大家自己的集群规模可以适当的更改。
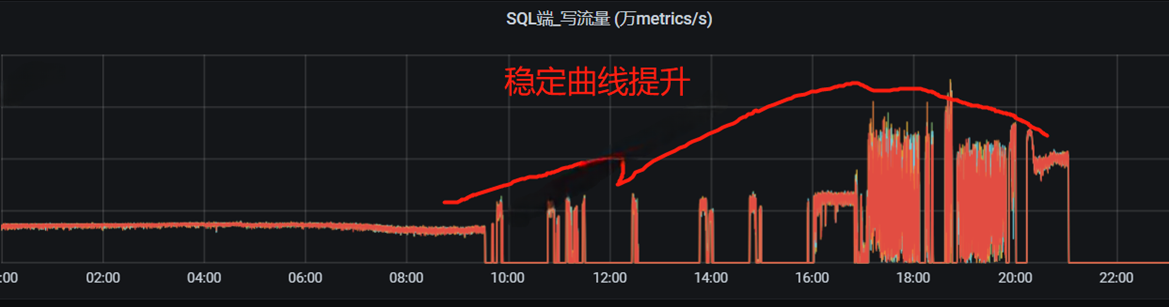
![]()
平稳写入曲线有了质的提升,平稳写入速率大约提升了一倍多,目的达到。
六、compact参数调优
openGemini的compaction分为普通level compaction和full compaction,前者是在数据一边写入一边工作,而full compaction则是超过一定时间没写数据就会触发,或者在业务低峰时触发。
#compact吞吐量。
compact-throughput = "300m"
#compact吞吐量突发。
compact-throughput-burst = "300m"
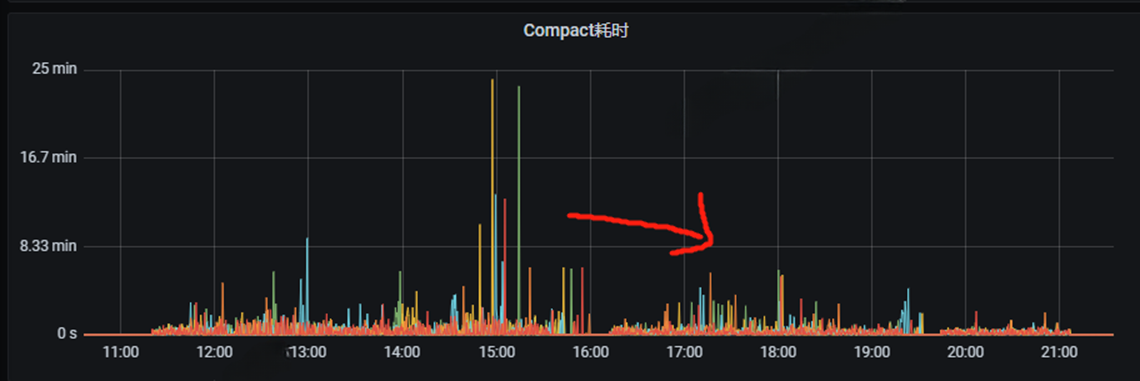
数据量大的情况下,会频繁的进行level compaction,增大compaction的吞吐量就可以减少compaction的耗时,相应的提升集群的吞吐量。
![]()
![]()
compact耗时下降,速度有一定的提升并且更加稳定了些。
七、乱序数据处理
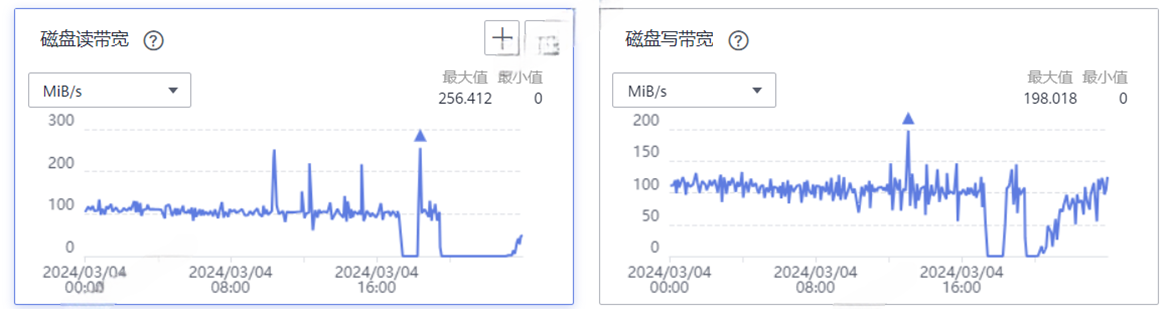
当停止写入数据并且确认SQL端和Store端写请求为0的时候发现数据磁盘IO一直处于40%左右的繁忙状态,那么只有可能是openGemini系统再做操作,那就只可能是压缩数据的compaction操作和乱序数据的merge操作。但是经过compaction的监控数据发现数据停止写入大概几小时后就会停止compaction操作,所以定位到该操作就是乱序merge引起的。
![]()
![]()
针对乱序数据的解决方案:
1、确保单条时间线数据是有序的,比如tag作为key插入kafka当中保证单tag数据在单partition的有序性。并且每次批量插入数据时保证批量数据局部有序,这样可以最大程度减少乱序文件数量。
什么是时间线?参考:
https://docs.opengemini.org/zh/guide/reference/specification.html
2、因为乱序数据合并会占磁盘I/O,如果业务上面是在无法去除乱序数据,可以采用高I/O磁盘来削平合并乱序数据对磁盘I/O产生的影响
3、升级openGemini的版本,v1.2 版本针对内核进行了优化,经过测试也会针对乱序数据的处理提升了效率,并且社区表示后续的版本也会针对compaction和merge操作进行更深层次的优化。
八、集群规模更改
假设我一个集群是10台16U64G,那么我换成20台8U32G,那么我整个的集群吞吐效率是否会有提升呢?
首先说下为什么会有这么一个想法:
衡量一台机器性能无非就是内存,CPU和磁盘I/O,但是经过多次实验发现每次最先达到瓶颈的是磁盘I/O,但是又不想上成本非常昂贵的高I/O磁盘,那么我们是不是可以降低单台机器性能 + 相对中等的I/O磁盘,增加节点数来扩充集群吞吐呢?
这么做从理论上有这么几点好处:
1、节点增多意味着单时间范围shard增多,增多节点意味着写的并行度增大
2、节点增多,意味着在总请求不变的情况下,每个节点处理的写请求变小,也有益于提升写入效率
3、并且大机器分为两个小机器,磁盘用稍微逊色的I/O磁盘,机器成本是降低的
经过多次实验写入也发现,适当的调整集群规模,在集群总cpu和内存不变的情况下用多机器代替高性能少机器其实对写入的效率也会有很大的提升。
结束
本文主要介绍了我在使用openGemini进行性能调优过程中的一些做法。在海量数据写入场景下实测,通过适当的参数优化,openGemini是完全可以满足性能要求,并且openGemini的内存控制的非常好,希望可以给大家做参考
openGemini官网:http://www.openGemini.org
Star for me😊:https://github.com/openGemini
openGemini公众号:
![]()
欢迎关注~ 诚邀你加入 openGemini 社区,共建、共治、共享未来!