基于语义的匹配模型--张量分解模型
![]()
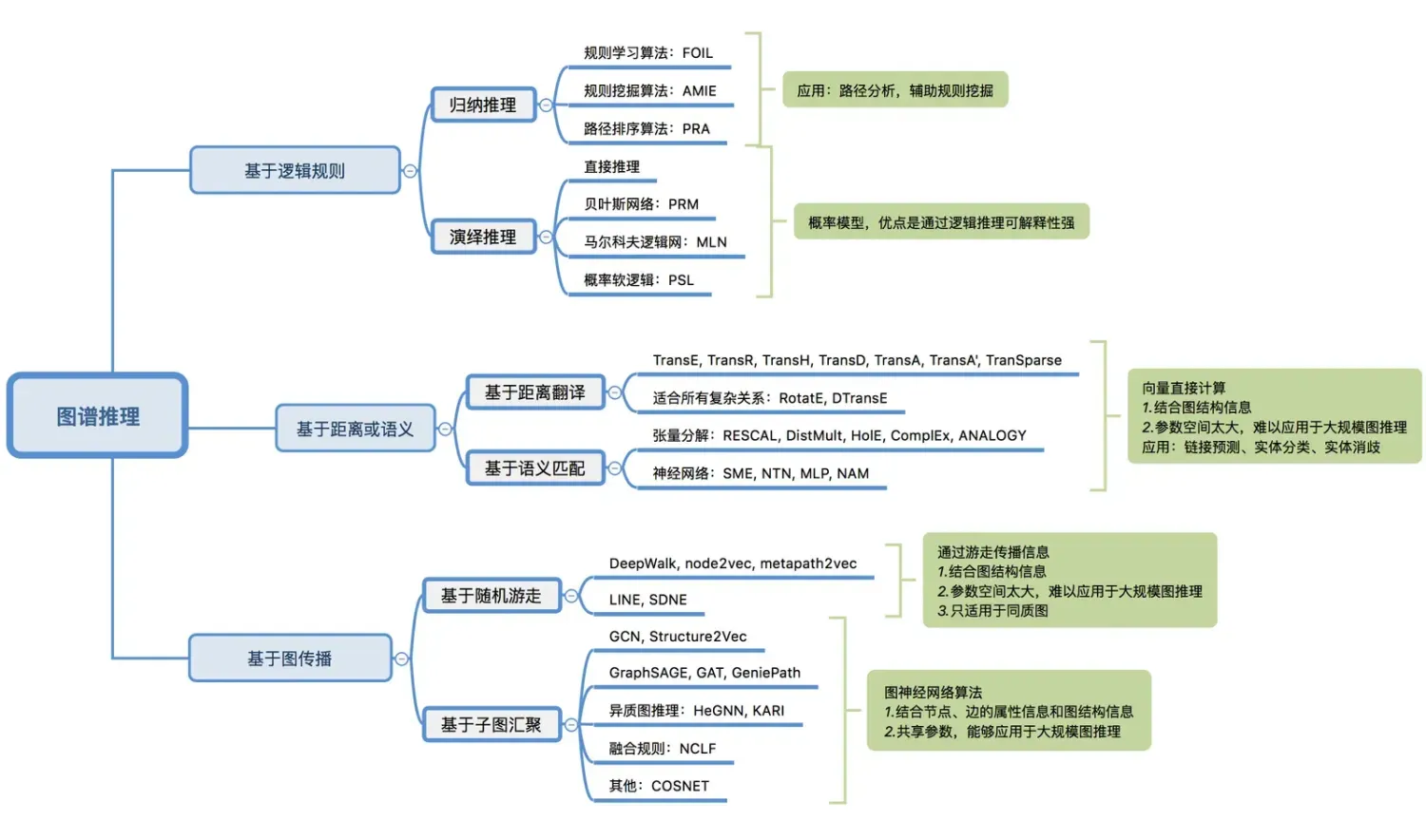
RESCAL
Trans系列算法是利用求和来表达关系![]() 对头结点
对头结点![]() 的影响,而RESCAL[14]是利用旋转、拉伸来表达关系
的影响,而RESCAL[14]是利用旋转、拉伸来表达关系![]() 对头结点
对头结点![]() 的影响。旋转、拉伸操作在数学上就是乘以矩阵Mr。RESCAL张量分解算法是将整个知识图谱看作一个大的张量,通过张量分解技术分解为多个小的张量片,即将高维的知识图谱进行降维处理,大幅减少计算时的数据规模。张量构建的基本方法是,如果实体i和实体j存在关系k,则
的影响。旋转、拉伸操作在数学上就是乘以矩阵Mr。RESCAL张量分解算法是将整个知识图谱看作一个大的张量,通过张量分解技术分解为多个小的张量片,即将高维的知识图谱进行降维处理,大幅减少计算时的数据规模。张量构建的基本方法是,如果实体i和实体j存在关系k,则![]() 否则为0。
否则为0。
其目标函数如下(一种向量内积):
![]()
DistMult
DistMult[15]是为了减少RESCAL的参数空间,而采用了一个对角矩阵diag(r)来代替矩阵Mr。这一点与TransH和TransE之间的关系有异曲同工之妙。其目标函数如下:
![]()
需要留意的是,因为采用了对角矩阵diag(r),而h、t互换后是相等的,见下式,导致DistMult只能处理对称关系。比如"A-同学-B",而不能处理非对称关系,比如"A-父亲-B"。
![]()
HolE
HolE[16]是为了在缩小RESCAL的参数空间前提下,依然能够处理非对称关系而开发的。方法就是每次先利用快速傅里叶变换对头向量和尾向量做一个shift i 位,然后再做内积运算。因为头向量和尾向量shift的位数不一样,就打破了对称性,就可以处理非对称关系了。其目标函数如下:
![]()
![]()
ComplEx
ComplEx[17]和HolE目的相同,为了能够缩小RESCAL的参数空间,同时依然能够处理非对称关系。ComplEx采用了复数的方式,扩充到实部和虚部以增加自由度的方式来解决非对称关系。其目标函数如下:
![]()
ANALOGY
ANALOGY[18]融合了DistMult、HolE、ComplEx这三类模型,以期待得到更好的效果。
基于语义的匹配模型--神经网络类型
![]()
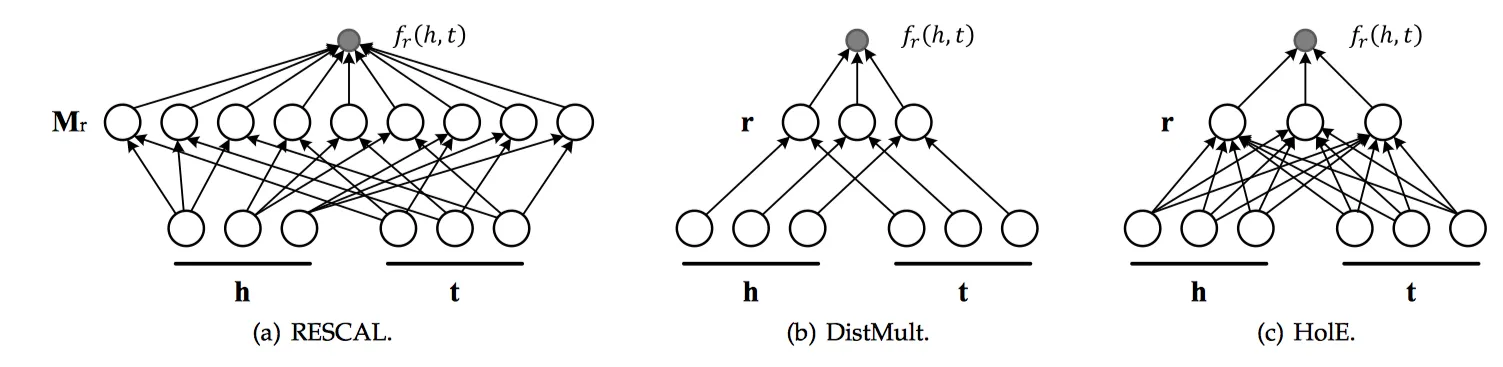
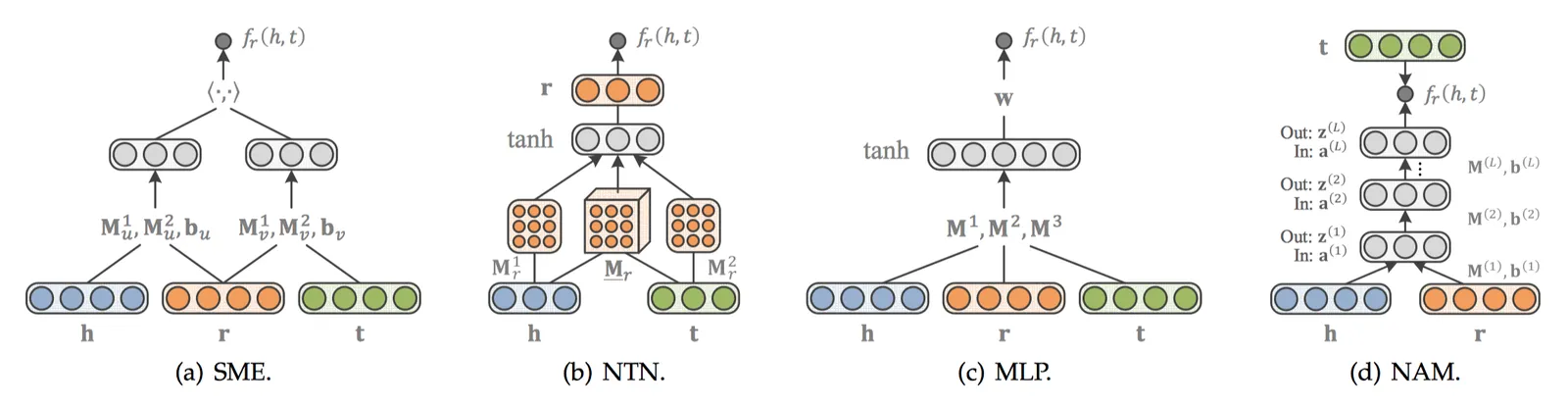
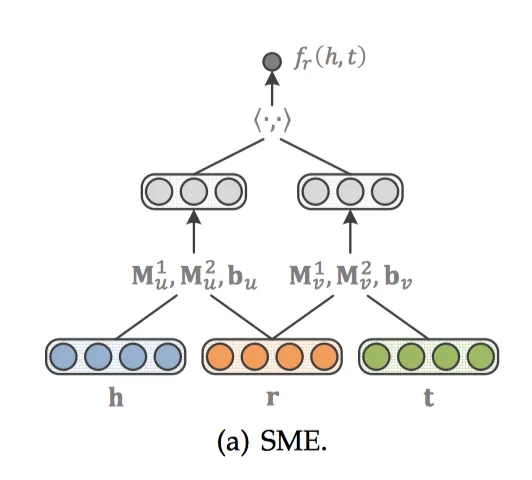
SME
SME[19]利用深度神经网络构造一个二分类模型,将h、r和t输入到网络中。先经过隐藏层gu和gv分别将h、r以及t、r结合,然后将这两个结果在输出层做内积作为得分。如果(h,r,t)在知识图谱中真实存在,则应该得到接近1的概率,如果不存在,应该得到接近0的概率。得分函数如下:
![]()
隐藏层gu和gv分别将h、r以及t、r结合。有两个版本,其中一个是线性版本:
![]()
![]()
另外一个是双线性版本:
![]()
![]()
![]()
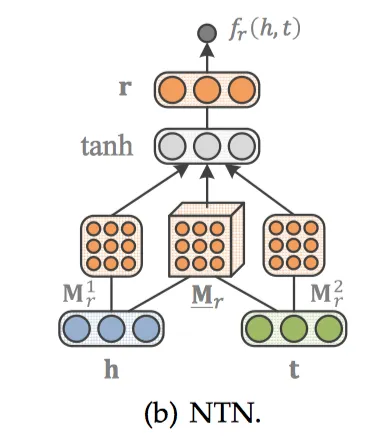
NTN
NTN[20]是另外一种神经网络结构。与SME打平的结构不同,NTN先用隐藏层将h、t结合起来,经过一个激活函数tanh以后,在输出层与关系向量r相结合。得分函数如下:
![]()
![]()
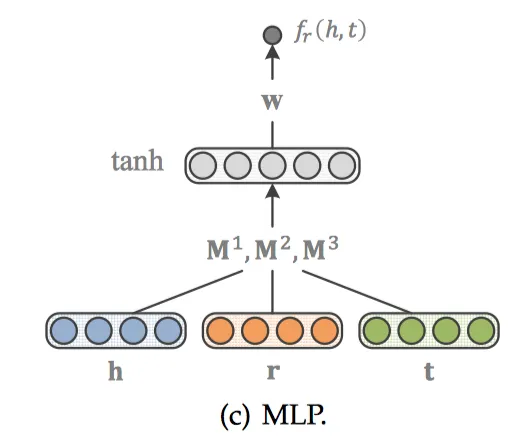
MLP
MLP[21]模型更简单一些,h、r、t经过输入层结合在一起,通过激活函数tanh后得到非线性的隐藏层,权重为M1、M2、M3,最后再经过一个线性的输出层,权重为w。得分函数如下:
![]()
![]()
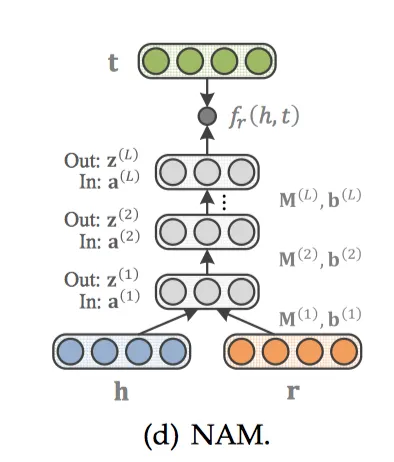
NAM
NAM[22]先将h和r经过输入层后结合在一起,然后使用多层DNN作为隐藏层,第![]() 层为z(
层为z(![]() )。
)。
![]()
![]()
得分函数如下:
![]()
![]()
两种loss
Logistic loss适合RESCAL系列模型。是基于Close World假设,即将未观察到的三元组视为不成立。对正确的三元组进行奖励,对错误的三元组进行惩罚。
![]()
Pairwise ranking loss更适合Trans系列模型。是基于Open World假设,将未观察到的三元组视为不一定成立。将事实三元组和未观测到三元组从距离上尽量分开。
![]()
这里![]() 是给定常数margin,用于将正、负三元组分开。
是给定常数margin,用于将正、负三元组分开。![]() 是正样本的打分,
是正样本的打分,![]() 是负样本的打分。
是负样本的打分。
上面这些算法默认都是随机初始化的。初始化这里也有发挥的空间,比如可以利用外部知识源做一些预训练等。
应用
给定三元组(h, r, t)中任意两个预测第三个。
评估指标有:
-
- MR(mean rank)预测排序的平均值
- MRR(mean reciprocal rank)排序倒数的平均值
- Hits@N 排序高于N的百分比
- AUC-PR 精度-召回曲线下方的面积
对给定三元组(h, r, t)判定成立还是不成立。
这里用了一个技巧,即将实体分类转化为求 “Is A” 关系。
若两个实体的向量相等,就判定为同一个实体
Trans系列、RESCAL系列、SME系列这三类模型的参数数量与节点数量成正比,面对大规模图谱时往往捉襟见肘。为了克服这个困难,人们引入了图神经网络模型GNN,图神经网络后来发展成为了一个体系,本文后面会介绍到包括GCN、GAT、Structure2vec、GeniePath等等图神经网络算法。图神经网络算法通过共享参数的方式降低了参数空间,就能适用于大规模图推理了。
文献已经下表将上述各类算法做了一个汇总,将上述算法的实体、关系嵌入向量,打分函数,约束信息的表达式做了整理如下:
![]()
![]()
小结
从算法分类角度
无监督:Deepwalk、Node2Vec、Metapath2vec、LINE、Louvain
有监督:GCN(半监督)、GraphSAGE、SDNE(半监督)、GeniePath、GAT、Structure2Vec、HeGNN
从应用角度
链接预测:所有的embedding算法都支持链接预测。有一个区别是同质图模型支持一种关系预测,而异质图模型支持多种关系预测。(另外加上ALPS平台尚未包括的trans系列也可以做链接预测)。
实体归一(相似度计算):所有的embedding算法都支持相似度计算。相似度是由具体的任务目标来定义并体现在loss中,一般的任务目标有距离相似性(两个节点有几度相连)、结构相似性、节点类型相似性(label预测)。
属性值预测(label预测):GCN、GraphSAGE、GeniePath、GAT、Structure2Vec、HeGNN等。
持续分享SPG及SPG + LLM双驱架构及应用相关进展
查看官网:https://spg.openkg.cn/
Github:https://github.com/OpenSPG/openspg