Structure2Vec
kernel methods在2002年代是处理结构化数据的代表方法,包括两类:基于bag of structures和基于probabilistic graphical models (GM)。但是kernel methods特别依赖于核函数(即特征空间)的设计。缺点是不能处理大规模图。
为了能够处理大规模图,宋乐老师团队开发了Structure2Vec[29,30]。因为不需要存储核矩阵(kernal Matrix)所以占用内存小了很多,应用了随机梯度下降后也具有处理大规模图的能力。Structure2Vec包含了两种传播方式Mean Field 和 Loopy Belief Propagation(后来扩展到了更多种传播方式)。
Structure2Vec[29,30]是什么:
是一个基于知识图谱的深度学习和推理算法,是一种graph embedding算法。不仅仅考虑节点的特征,还考虑了节点和边之间的相互作用以及传播。
讲解原理之前首先介绍聚合算子的概念。图谱可以看作由多个中心节点和对应的邻居节点组成。下一步需要考虑的就是如何将信息从邻居节点汇聚到各个中心节点。下图给出了2跳聚合算子的示例,中心节点A的表示是由其邻居节点B、C、D的信息聚合而来,而节点B、C、D的信息是由它们各自的邻居信息聚合而来。最终得到了聚合算子(aggregator),其作用是对邻居节点的信息进行聚合。为了方便理解,我们类比CNN,聚合算子就相当于卷积层,因为他们都起到了将周围点的信息汇聚起来的作用。
![]()
图: 两跳聚合算子示例
解决了以前的深度学习技术难以用于诸如图形、网络和动态网络等组合结构数据的表示和特征学习。
![]()
![]()
图: Structure2Vec的基本原理[30]
Yi:节点i的标签(label)
Xi: 节点i的属性值(value of attribute)
Hi: 是一个隐变量,是输入Xi的代言
![]() :节点i的向量化表示,其初始化是通过对特征进行信息抽取得到。
:节点i的向量化表示,其初始化是通过对特征进行信息抽取得到。
W1、W2:节点i与自身以及与邻节点的相互作用,包含了图结构以及节点的特征信息。
V:节点i的特征向量![]() 与输出Yi'之间的转换矩阵。注意参数W2和V并不是针对某一个节点的,而是整个网络都采用这同一套参数,即共享参数。
与输出Yi'之间的转换矩阵。注意参数W2和V并不是针对某一个节点的,而是整个网络都采用这同一套参数,即共享参数。
n:节点特征维度。
d:特征向量![]() 的维度。
的维度。
(1)对于第i个节点,该节点的特征信息传递给自己,邻居的信息再传递过来。然后经过K度传播,可以获得以i节点为中心的一个subgraph,作为训练集的一个基本单位。
(2)最小化损失函数 loss=(Yi-V![]() )2。采用训练集训练(随机梯度下降),通过最小化损失函数得到模型W1,W2,V。
)2。采用训练集训练(随机梯度下降),通过最小化损失函数得到模型W1,W2,V。
(3)在infer过程中,先获取节点i的K度subgraph,然后将该subgraph带入模型便可以得到该节点的嵌入向量以及预测结果。
说明:这里介绍的是Mean Field方法,另外作者在文章中还介绍了一种方法Loopy Belief Propagation。这两种方法的区别是:前者的信息传播过程是,在一个超步内,通过对每一个相关节点上的信息进行收集得到的。后者的信息传播过程包含两步,在一个超步内,第一步对每条边上传播的信息进行汇总,第二步再对每条经过节点i的边上面的汇总后的信息进行收集。
Structure2Vec提供了一种能够同时整合节点特征、边特征、网络结构以及网络动态演化特征的深度学习和推理嵌入技术。它可以对网络中的节点和边进行推理,能够挖掘出节点之间的二度、三度甚至更深层次的关系。Structure2Vec平台支持十亿节点、百亿边规模的图模型训练,并且对于实际小于百万节点的小规模业务场景,其也支持使用单机模式迅速训练,用户可以根据自己的需要进行随意切换或让系统自动切换。Structure2Vec平台提供了一整套流式解决方案,从用户原始数据检查、到模型训练和导出模型和预测结果给业务,都可以通过简单配置设置例行运行。
1). 矩阵乘法采用GPU加速;
2). T度传播,当T较小的时候,可以只加载局部图;
3). 利用Parameter Server进行分布式计算。
Structure2Vec需要与有监督学习相结合。其应用分为两类,一类是应用于静态图,一类是应用于动态图。
静态图应用中,Structure2Vec可以分别对节点、边、子图的结构进行分类或回归。应用举例:
1) 垃圾账号识别,这属于节点分类问题。账号和设备之间的登录情况构成图谱,并且账号和设备也各自具有特征。然后利用带有标签的账号数据对经过T次信息传播后的模型进行训练,得到传播权重W1、W2和分类参数V以及每个节点(账号)的嵌入向量 。有了这些参数和嵌入向量就能对未打标签的节点进行预测了。
2) 基于分子结构预测光伏作用大小的问题,如下图所示,这就属于子图结构预测问题(预测的是连续值所以这是回归问题)。首先经过T次传播,然后通过训练得到了传播权重W1、W2和分类参数V以及每个节点的嵌入向量。训练的目标函数是通过对这些嵌入向量的加权求和来表示光伏作用的大小,然后与打标的target之间的平方差定义为loss。训练好了模型以后,就可以预测新的分子结构的光伏作用大小了。
3) 通过药物分子结构预测药物效果,就属于利用结构信息进行分类的问题,原理和过程与2)类似只是由回归问题变成了分类问题。
![]()
图:利用Structure2Vec基于分子结构预测光伏作用大小的问题
![]()
FC_RES数据集描述的是RNA将基因片段定向到DNA。SCOP数据集是蛋白质结构分类,这两个都是子图分类问题。前面四种算法都是kernal method,后面两种是Structure2vec的两种实现方式。可以看到Structure2vec的效果明显好于kernal method。
![]()
这个实验是基于分子结构预测光伏作用大小的问题,WL是kernal method,后面两种是Structure2vec的两种实现方式。MAE是平均误差,RMSE是均方根误差。可以看到Structure2vec的效果明显好于kernal method。另外,一个重要的区别是kernal method是not scalable的,而Structure2vec是scalable的,实验中WL lv-6对于百万大小的数据集其参数数量比后两者多了1万倍,速度却只慢了两倍。
动态图应用中,多了一个时间轴,Structure2Vec可以对节点之间是否会发生交互以及交互的概率进行预测。应用举例:
1). 推荐系统。User和iterm随着时间的交互展开成一个单一方向的图结构,如图所示,通过强化学习得到嵌入向量,对某个时刻的user和item的嵌入向量做内积,就能判断二者在该时刻的交互发生的概率。
2). 对事件的预测,与1)同理。
![]()
![]()
图: 利用Structure2Vec基于时间动态演化进行商品推荐
应用情况:目前Structure2Vec在信用评估、推荐系统、行为预估、垃圾账号识别、保险反欺诈以及芝麻信用团队的反套现模型中都取得了非常好的效果。
GraphSAGE
GraphSAGE[31]和Structure2vec比较类似,都是由聚合算子构建起来的图计算模型,都是共享参数的模型。GraphSAGE是比较早期的经典GNN算法,来自斯坦福发表于2017年。很多文献都会和GraphSAGE进行比较。这篇文章明确提出了图算法中的transductive learning和inductive learning的区别。
直推式(transductive)学习:从特殊到特殊,仅考虑当前数据。在图中学习目标是学习目标是直接生成当前节点的embedding,例如DeepWalk、LINE,把每个节点embedding作为参数进行学习,就不能对新节点进行infer。
归纳(inductive)学习:也就是平时所说的一般的机器学习任务,以共享参数方式进行学习。从特殊到一般:目标是在未知数据上也有区分性。
![]()
GraphSAGE同样采用聚合算子,其信息聚合的过程如上图所示,可以描述为以下三个步骤:
-
- 先对邻居随机采样,降低计算复杂度(图中一跳邻居采样数为3,二跳邻居采样数为5)
- 生成目标节点嵌入向量:先聚合2跳邻居特征,生成一跳邻居嵌入向量,再聚合一跳邻居嵌入向量,生成目标节点嵌入向量,从而获得二跳邻居信息。
- 将嵌入向量作为全连接层的输入,预测目标节点的标签。
算法伪代码如下:
![]()
其中4、5行的for循环描述了汇聚算子的工作过程。第4行描述了信息由k-1层汇聚到第k层。第5行描述了中心节点信息由中心节点的k-1层信息与中心节点的邻居信息进行拼接,并通过一个全连接层转换,最终得到中心节点在第k层的嵌入向量。
GraphSAGE提出了四种不同的聚合方式:平均聚合、GCN归纳聚合、LSTM聚合、pooling聚合。
a. 平均聚合:先对邻居embedding中每个维度取平均,然后与目标节点embedding拼接后进行非线性转换。
![]()
b. GCN归纳聚合:直接对目标节点和所有邻居emebdding中每个维度取平均(替换伪代码中第5、6行),后再非线性转换:
c. LSTM函数不符合“排序不变量”的性质,需要先对邻居随机排序,然后将随机的邻居序列嵌入向量作为LSTM输入。
d. 先对每个邻居节点上一层嵌入向量进行非线性转换(等价单个全连接层,每一维度代表在某方面的表示),再按维度应用 max或者mean pooling,捕获邻居集上在某方面的突出的或者综合的表现 以此表示目标节点嵌入向量。
![]()
![]()
从实验结果上可以看到GraphSAGE的四种聚合方式比传统算法均有所提升。
GAT
Graph Attention Networks (GAT)[32]算法的主要思想是利用attention机制来代替GCN中的卷积层,得到node embedding。同时该算法可以适用于transductive和inductive两种任务。transductive任务是指测试集的节点和节点特征在训练过程中出现过;inductive任务是指测试集中的节点不会在训练过程中出现。下面介绍其核心结构Graph Attention layer.
对于每一层,输入为每一个节点的feature, h={h1,h2,⋯,hN}, hi∈RF,N为节点个数,F为输入特征维数。输出亦为每一个节点的feature, h'={h′1,h′2,⋯,h′N}, h′i∈RF′,F′为输出特征的维数。则attention 机制就是在对输入特征做线性变换W∈RF′×F后计算对于节点i其周围节点(包括自身)的权重,最后加权求和通过激活函数即得到节点i的输出特征。则节点j对节点i的权重(可以看做节点j对于节点i的重要性)为:
![]()
其中![]() 就是attention机制,后面会给出几种具体的形式。则节点i输出可由对其相邻点加权得到:
就是attention机制,后面会给出几种具体的形式。则节点i输出可由对其相邻点加权得到:
![]()
上面这一步softmax为对权重的正则化。
![]()
上面这一步就是一个加权求和。注意到这个模型只用到了节点特征,没有用到边的信息。
文中给出的attention 机制有两类:一类是单层网络,如下:
![]()
另外一类是多头注意力网络(multi-head attention)的两个例子,第一个例子是将不同的head得到的嵌入向量做拼接,第二个例子是做平均,如下:
![]()
![]()
![]()
图: Graph Attention Networks (GAT)算法的Graph Attention layer图示
因为Attention计算相互独立,方便并行计算,所以比传统的GCN高效。
![]()
![]()
可以看到实验结果都还不错,尤其是PPI的结果,比GCN的结果高太多了。文章发表在ICLR 2017[32]上。
GAT算法和下面将要介绍的GeniePath算法比较相似,都是建立在GNN基础之上,只是GAT只添加了对邻居节点信息进行筛选的attention机制,而GeniePath除此之外,还采用了LSTM机制来过滤经过多层传播的信息。从效果来讲,这两种算法的表现也比较接近,并且二者的表现都明显好于之前的GNN算法。
因为算法特性一致,GNN能够使用的场景(比如前面Structure2Vec的应用场景),GAT理论上应该都适用。
GeniePath
![]()
图: GeniePath算法的发展脉络
GraphML团队开发的GeniePath算法[33,34]可以在聚合算子上结合节点的属性信息来判断到底有多少信息需要传播,有多少信息可以过滤掉。简单来讲就是,和structure2vec相比,GeniePath的聚合算子不仅仅采用了结构信息而且还结合了节点属性信息,就具有了更强大的表达能力。
下图揭示了GeniePath的算法结构,其结构是在基本的聚合算子上做了扩展。虚线左边表示在广度上采用了attention机制来筛选邻居节点;虚线右边表示在深度上采用了LSTM机制来过滤经过多层传播的信息。
![]()
下面的方程就描述了GeniePath在深度上的attention机制以及广度上的LSTM机制。
![]()
其中![]() 是输入门;
是输入门;![]() 是遗忘门;
是遗忘门;![]() 是输出门。
是输出门。
![]() (8)
(8)
GeniePath沿用GNN的计算框架,其特点在于会根据优化目标自动选择有用的邻居信息,来生成节点特征(embedding)。GeniePath通过定义两个parametric函数:自适应广度函数、和自适应深度函数,共同对子图进行广度、深度搜索。其中自适应广度函数限定朝哪个方向搜索重要节点,自适应深度函数限定搜索的深度。实现中如上图所示,GeniePath使用一个attention网络表达自适应广度函数来来筛选邻居节点,使用一个LSTM-style网络表达自适应深度函数来过滤经过多层传播的信息。GeniePath后来进行了升级,不仅能考虑节点特征,还能考虑边的特征。
目前所有的图神经网络方法都基于如下框架,做T次迭代,相当于每个节点拿自己走T跳可达的“邻居”节点,来做传播和变换,最后的被用来直接参与到损失函数的计算,并通过反向传播优化参数。在GeniePath之前的算法:Structure2Vec、GCN、GraphSAGE,他们的共同特点是对T步内所有邻居做聚合(aggregate),且以固定的权重做聚合。这些经典的GNN方法只会根据拓扑信息选择邻居并聚合生成特征,不会过滤和筛选有价值的邻居。而我们不但要看拓扑信息还要看节点的行为特征。GeniePath关心在聚合的时候到底应该选取哪些重要的邻居信息、过滤那些不重要的节点信息。
![]()
图:自适应的感知域示例
1). 相比其他GNN算法,在大数据上可能有更好的性能,效率更高!
2). 可解释性更强。注意力权重可以区分出重要的边和次要的边,增加了可解释性。
![]()
Alipay的数据集有1M节点,2M边,4k特征。可以看到数据集越大,效率越高,效果越好。
![]()
对蛋白质相互作用推理,F1值提升明显。
因为GeniePath是其他GNN算法的升级版,因此其他GNN算法的应用场景(比如前面讲到的Structure2Vec的应用场景)GeniePath应该都能实现,并且一般都可以期待更好的性能。GeniePath作为一个通用图神经网络算法已经在蚂蚁金服的风控场景实际使用,并得到较理想的效果,很好地提高了支付宝保护用户账户安全的能力[35]。其论文中还实现了的GeniePath应用场景包括:引用网络、BlogCatalog社交网络、蛋白质相互作用网络。
HeGNN
GraphML团队开发的HeGNN[36]算法在GNN算法的基础上引入了多层次注意力机制。该算法支持异质图,即支持不同类型的节点和不同类型的边。过程可以简单理解为将不同类型的关系做成多个同质图,然后合并在一起。具体如下:
HeGNN算法使用了MetaPath(元路径)。每一条元路径携带着不同的语义,可以帮助我们利用异质信息网络中丰富的结构信息。比如消费图谱中的“User - (fund transfer) - User” (UU)记录了用户与用户之间的转账信息,“User-(transaction) -Merchant-(transaction)-User” (UMU)记录了两个用户同时在一个商家交易的信息。有效地融合这些元路径信息,可以使得模型充分利用不同类型的边的差异信息。下一个问题是如何有效地聚合异质的邻居信息。
层次注意力机制
直觉而言,不同的邻居、特征以及元路径会对节点的表示产生不同的影响。因此,下面介绍如何建模节点对这些方面信息的偏好。
邻居注意力
参照GAT算法的思想计算节点对每个邻居的注意力值,代表着每个邻居的贡献。可以按照如下的计算公式实现:
![]()
![]()
针对具体的场景,作者也给出了两种可替代的实现如下:
(1) avg-pool : 针对大规模的业务场景,可以直接对元路径下的邻居的特征做加权平均。这样可以大大降低计算量,而且一般可以得到一个不错的结果。
![]()
(2) geniepath-pool : 对于每一条元路径下的邻居,可以复用geniepath来实现单一元路径下的特征表示。
特征注意力
不同的特征可能对节点的表示存在不同的贡献。因此,参照文献,作者设计了如下的特征注意力层对每个特征点计算特征贡献值:
![]()
![]()
路径注意力
元路径抽取了节点在异质信息网络中的不同方面的信息,比如元路径“UU”抽取了用户的转账信息,元路径“UMU”抽取了用户的交易信息。所以需要设计路径的注意力层来捕获节点对不同元路径的偏好。具体地,按如下方式为每个节点计算它对元路径集合中每条元路径的注意力值 :
NCLF
NCLF [37](Neural Conditional Logic Field)是一种融合逻辑规则的推理算法。
我们知道神经网络的优点是学习能力强,但是需要的标注样本较多。而逻辑规则推理正好相反,它所需的标注样本少,但学习能力有限。NCLF的出发点是把这两者的优点融合,填补各自的缺点。
把专家经验引入到学习中来提高学习效率最近很火,专家经验可以转述为一阶逻辑,经典的解法是马尔可夫逻辑网络(MLN),并采用变分推断(VI)来加速求解,NCLF进一步引入GCN来近似后验。在实现的过程中我们使用Hinge-Loss Markov Random Fields(HL-MRF)进一步简化计算,将全举过程近似为一次性计算,使其更适用于工业大数据。为了减少GCN消息传播的衰减,引入了Loopy belief propagation。另外在构图上将二部图变为一般图。而引入规则之后,可以基于统计或学习得到规则权重,去掉坏规则可以进一步提高学习效果。在工程计算上,因为一阶逻辑的计算需要进行实例化(Grounding),计算量大,实际使用中需要进行分布式样本生成。
我们在公开数据集和业务规则数据上分别进行了效果对比。
KARI
KARI算法是我们基于ALPS的KGNN[38]框架延伸开发的算法框架。这里简要介绍其原理,详细内容可以查看KARI ATA文章[39]。本文前面介绍的传统的链接预测算法比如基于向量之间距离的Trans系列算法、基于语义匹配模型RESCAL系列算法、基于随机游走的node2vec系列算法,这些算法把嵌入向量作为参数通过学习来获得,在小规模图上能够取得不错的效果,但对于大规模图来讲,参数空间暴涨,难以落地。GraphML团队的KGNN框架提出将传统算法和GNN类算法相结合,就具有了共享参数这个优点。采用共享参数的聚合算子会极大降低参数空间,就能适用于大规模图推理。因此,为了充分挖掘大规模图谱中的结构信息以及充分学习图谱中丰富的异质信息导致的一对多、多对一、对称、非对称、相反、组合等关系,我们在Encoder-Decoder的思想下,Encoder选用GeniePath,Decoder选用DtransE,再结合自对抗负采样等能力结合而成了KARI算法。
Encoder-Decoder框架
KARI默认选取GeniePath为Encoder,默认选取DTransE为Decoder。KARI通过自监督学习生成节点和边的表达(Embeddings),可输出给下游模型使用,补充图结构特征。这里自监督学习是指标签数据不需要人工打标生成,利用边表中已知的三元组可以构成正样本,然后随机生成负样本,就构成了训练集。
![]()
图:KARI的Encoder-Decoder框架示例
KARI目前支持的Encoder和Decoder如下:
- Encoder:GeniePath, GAT, GCN, Graphsage, Structure2Vec, Gin
- Decoder: DTransE, TransH, TransE, TransR, RESCAL, DistMult, Complex
下图中Encoder部分,中心节点A的嵌入向量是由其邻居节点B、C、D的信息聚合而来,而节点B、C、D的信息是由它们各自的邻居信息聚合而来,每一层汇聚就是一次迭代。这样我们通过Encoder中的T次迭代就获得了中心节点A的嵌入向量,重复这一过程还可以获得中心节点B的嵌入向量。关系r的嵌入向量最初由随机过程生成。然后将节点A、节点B和关系r的嵌入向量带入Decoder计算得分,再利用得分来计算loss。
![]()
图:KARI的Encoder和Decoder示意图
Decoder的作用是将嵌入向量中的节点特征和图结构信息直观的表达为三元组的打分,该打分可以理解为三元组成立的“概率”。KARI的Decoder默认选择我们团队自研的DTransE算法。
KARI算法的特性总结如下:
- 能够充分融合图谱中点和边的属性信息以及图的结构信息
- 支持异质图谱,即多种类型的节点和边
- 支持1-N,N-1,N-N的复杂关系
- 支持对称/非对称、反转、组合关系
- 支持自我对抗负采样
- 模型共享参数能够支持大规模图推理
- 支持常见推理任务(实体相似度计算、链接预测、节点分类、社区发现等)
- 可自监督学习进行预训练,提取图谱的特征信息,生成节点和边的通用向量表达,输出给下游模型使用
KARI目前支持的业务包括:最终受益人UBO关系预测、可信关系降打扰、支付推荐、支付搜索、财富内容带货等等,并取得了较好的效果。
GraphSAINT
当数据有热点时,限制随机采样邻居个数这类做法可能导致采样到的邻居中有不重要的邻居,并且丢失了重要邻居的信息。特别是当我们需要计算多层邻居时,子图大小指数暴涨,难以计算。GraphSAINT[40]旨在解决稠密点的问题,它从根本上改变了采样方式。它不再在原图上采样邻居,而是从原图上采样一个子图下来,在这个子图上做局部的、完全展开的GCN。优点:
-
- 图变小了,计算效率高
- 效果好
- 前置采样,无需修改GCN模型
采样策略倾向于影响大的节点被保留下来。采样概率只和链接信息有关,和节点特征无关。很适合提前预采样,下游GCN模型不用做改造。
![]()
上表给出了四种采样策略:
-
- Node sampler:第一步先采样节点得到一个节点子集,节点的采样概率正比于该节点的入度;第二步在该节点子集中补充好边。
- Edge sampler:第一步先采样边得到一个边的子集,边的采样概率反比于边的度(即反比于头节点和尾节点的度),然后将这些边涉及到的头、尾节点作为节点子集。
- Random walk sampler:第一步随机选择r个根节点开始随机游走h步;第二步将随机游走路径上的节点作为点的子集,边的子集就是这些点之间的边。
- Multi-dimensional random walk sampler:和方法c类似,区别是每步随机游走的概率正比于对应点的度。
GCN的通用表达式:
![]()
因为采样的图的分布和原图往往有差别,这会引入采样偏差。接下来的目的是尽量消除这个偏差。方法如下,采样以后中心节点的表达式修正如下:
![]()
其中![]() 和
和![]() 是指当v被采样到的前提下,u被采样到的概率,二者概率的期望会互相抵消。这样就消除了采样的偏差。同理,在损失函数中也除以一个参数,消除采样偏差。
是指当v被采样到的前提下,u被采样到的概率,二者概率的期望会互相抵消。这样就消除了采样的偏差。同理,在损失函数中也除以一个参数,消除采样偏差。
![]()
其中![]() 指在一次采样图中采样到v的概率。
指在一次采样图中采样到v的概率。
![]()
可以看到效果提升明显,特别是PPI数据集。而且效果比Cluster-GCN略有提升。GraphSAINT效果好的可能原因:
1.消除了噪音信息
2.朴素采样的GCN的mini-batch的方差较大,收敛性不好。
3.小图计算量小,可以训练更多个epoch
Cluster-GCN
Google开发的Cluster-GCN[41]算法,通过聚类形成一个个簇,并将链接尽量限制在簇内,起到了前置采样的效果。论文中介绍了两个算法方案,朴素版本的Vanilla cluster-GCN,和升级版本的Multiple cluster-GCN。下面分别介绍。
Vanilla cluster-GCN
该算法先做一次聚类,每个聚类的子图用来进行训练。聚类的目的是使簇内连接远大于簇间连接。图变小了,算法效果也不错。从热点角度来看相当于从多个热点中选出了少量几个热点作为簇,并隔离了不同的簇。该算法最大的优点是减小了batch之间的variance(偏差),效果提升,以及多层计算量呈线性而非指数增长。
![]()
![]()
只保留对角处的矩阵,近似忽略非对角处的矩阵。其含义是保留簇内的连接,忽略簇间的连接。对于Vanilla cluster-GCN,每个簇对应一个batch。这样导致计算效率增加,计算精度提高。效率增加是因为随着层数增加,节点数量呈线性增长,而其他GCN呈指数增长;精度增加其解释是减小了batch间的Variance(偏差),以及增加了计算层数。
Multiple cluster-GCN
尽管朴素Cluster-GCN实现了良好的时间和空间复杂度,但仍然存在两个潜在问题:
- 图被分割后,一些连接被删除。因此性能可能会受到影响。
- 图聚类算法往往将相似的节点聚集在一起,因此聚类的分布可能不同于原始数据集,从而导致在执行SGD更新时对 full gradient的估计有偏差。
为了解决上述问题,文中提出了一种随机多聚类方法,在簇接之间进行合并,并进一步减少batch间的偏差(variance)。作者首先用一个较大的p把图分割成p个簇V1,...,Vp,然后对于SGD的更新重新构建一个batch B,也就是一个batch中有多个簇。随机地选择q个簇,定义为t1,...,tq ,并把它们的节点包含到这个batch B中。此外,在选择的簇之间的连接也被添加回去。作者在Reddit数据集上进行了一个实验,证明了该方法的有效性。
![]()
实验中在两个公开数据集上达到了State-of-art的效果。
![]()
讨论
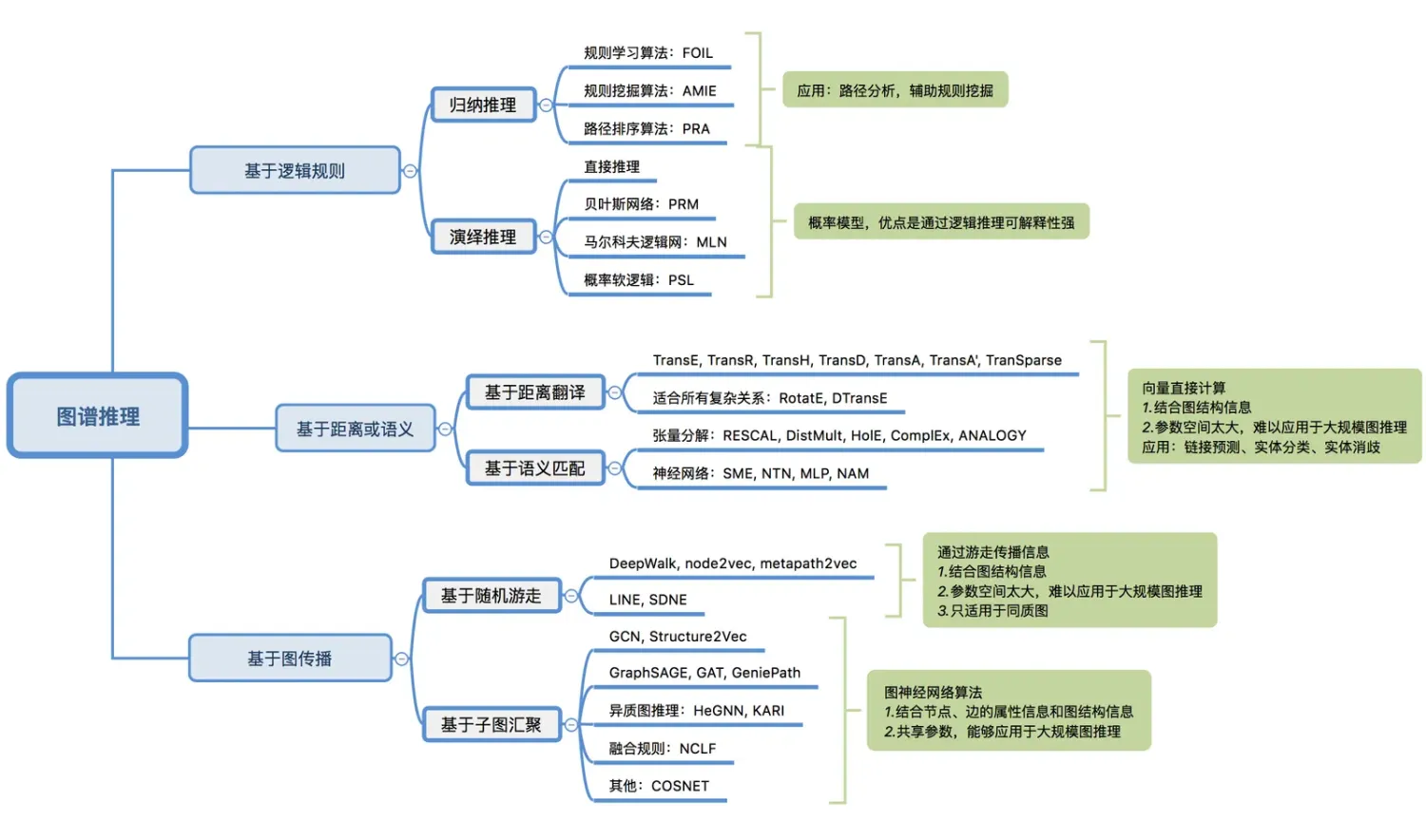
从算法分类角度
无监督:Deepwalk、Node2Vec、Metapath2vec、LINE、Louvain
有监督:GCN(半监督)、GraphSAGE、SDNE(半监督)、GeniePath、GAT、Structure2Vec、HeGNN
支持异质图:HeGNN、metaPath2vec、KGNN
支持同质图:Deepwalk、Node2Vec、LINE、SDNE、GCN、GraphSAGE、GeniePath、GAT、Structure2Vec
从应用角度
所有的embedding算法都支持链接预测。有一个区别是同质图模型支持一种关系预测,而异质图模型支持多种关系预测。(另外加上ALPS平台尚未包括的trans系列也可以做链接预测)。
所有的embedding算法都支持相似度计算。相似度是由具体的任务目标来定义并体现在loss中,一般的任务目标有距离相似性(两个节点有几度相连)、结构相似性、节点类型相似性(label预测)。
GCN、GraphSAGE、GeniePath、GAT、Structure2Vec、HeGNN等。
持续分享 SPG 及 SPG + LLM 双驱架构相关干货及进展
官网:https://spg.openkg.cn/
Github:https://github.com/OpenSPG/openspg