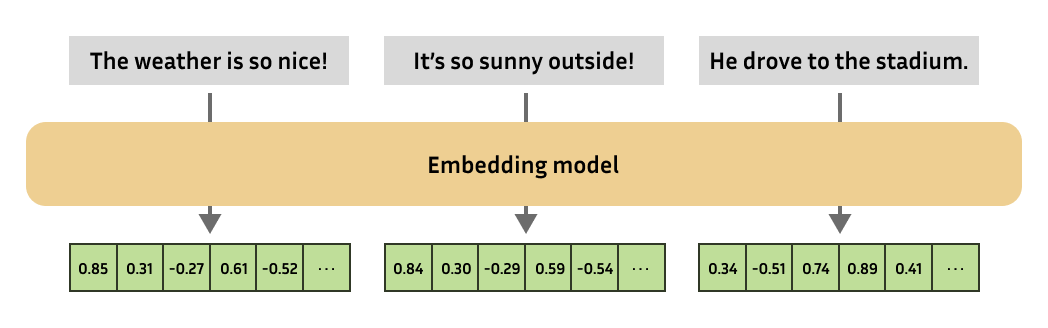
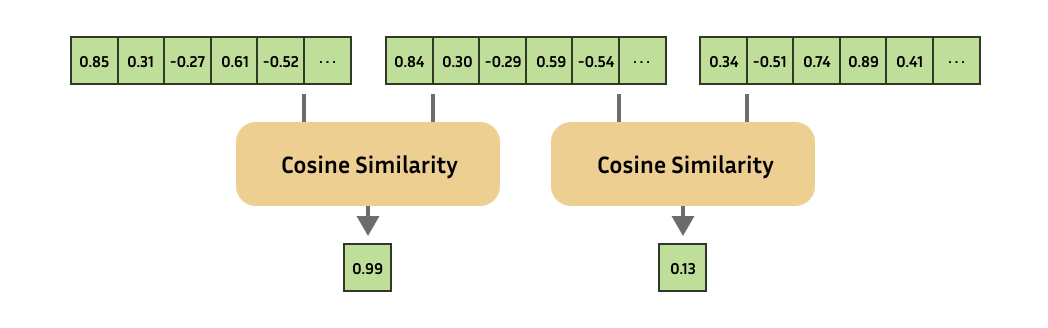
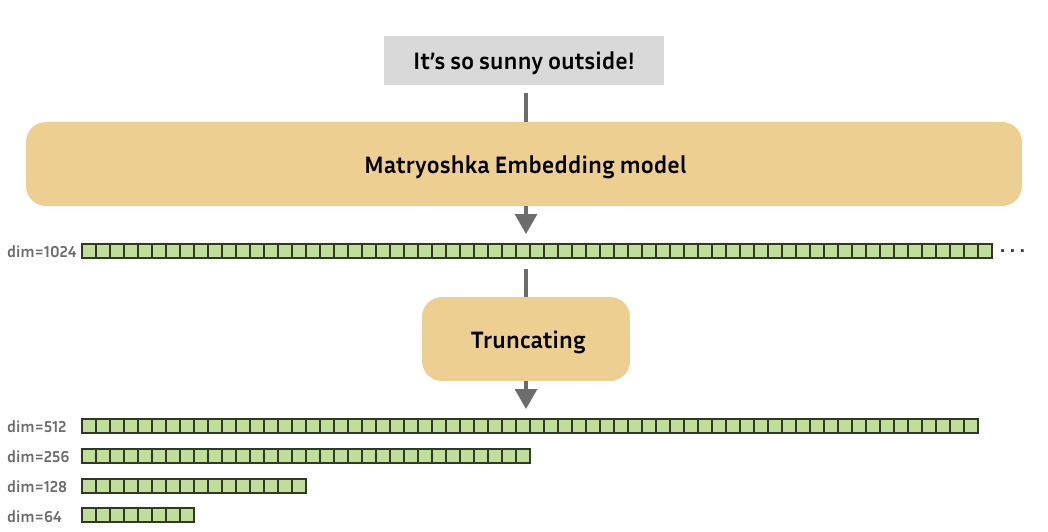
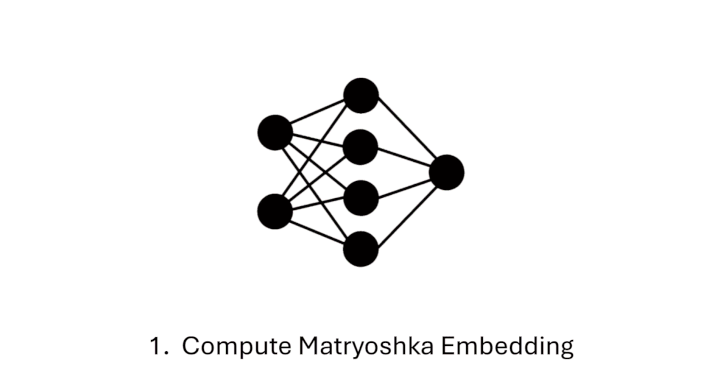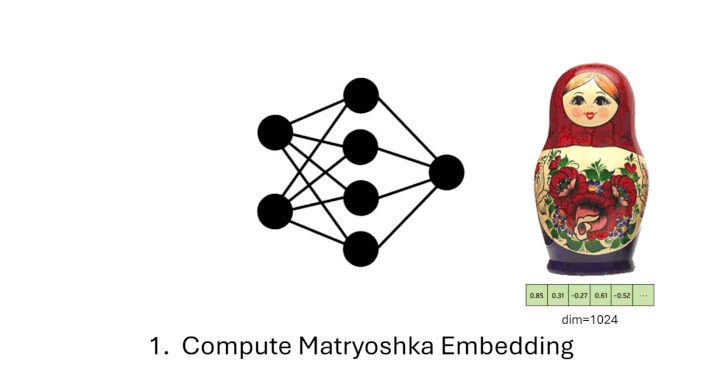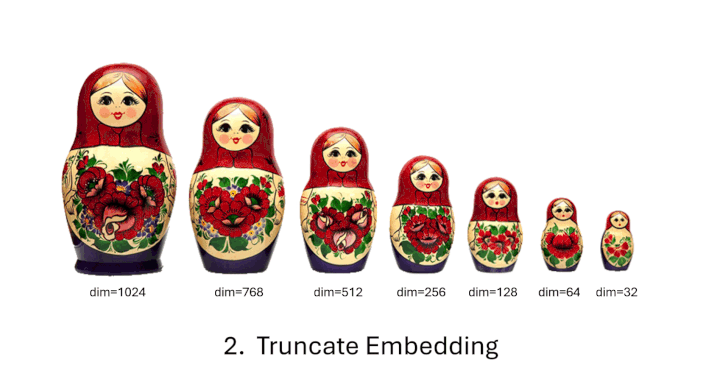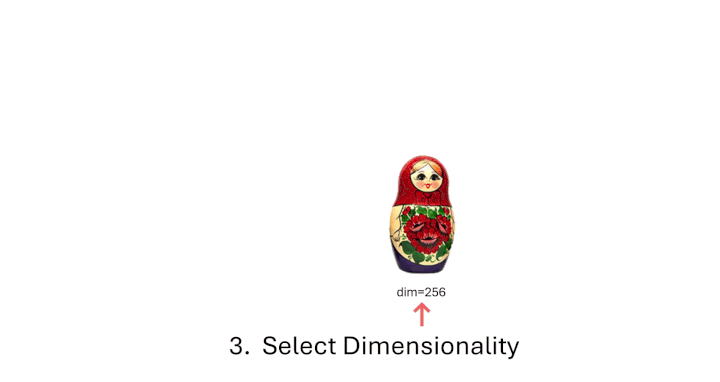
from sentence_transformers import SentenceTransformer from sentence_transformers.util import cos_sim
model = SentenceTransformer("tomaarsen/mpnet-base-nli-matryoshka")
matryoshka_dim = 64 embeddings = model.encode( [ "The weather is so nice!", "It's so sunny outside!", "He drove to the stadium.", ] ) embeddings = embeddings[..., :matryoshka_dim] # Shrink the embedding dimensions print(embeddings.shape) # => (3, 64)
# Similarity of the first sentence to the other two: similarities = cos_sim(embeddings[0], embeddings[1:]) print(similarities) # => tensor([[0.8910, 0.1337]])
模型链接: tomaarsen/mpnet-base-nli-matryoshka
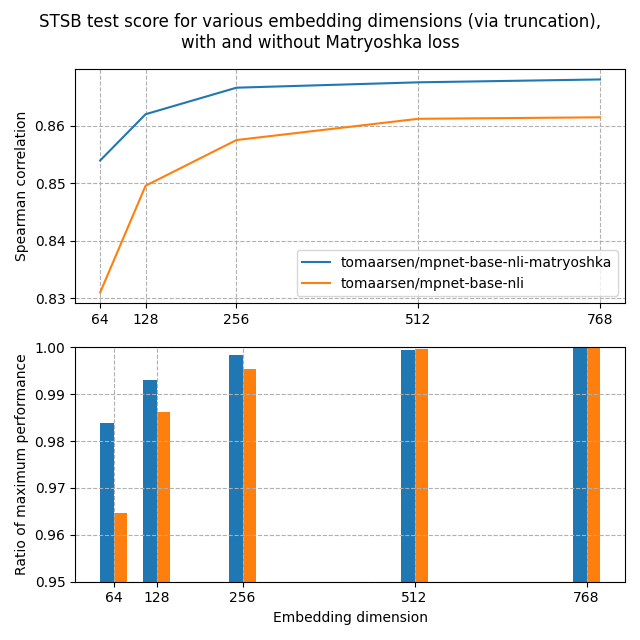
请随意尝试使用不同的 matryoshka_dim 值,并观察这对相似度的影响。你可以通过在本地运行这段代码,在云端运行 (例如使用 Google Colab),或者查看 演示 来进行实验。
参考文献:
SentenceTransformer
SentenceTransformer.encode
util.cos_sim
Matryoshka Embeddings - 推理
点击这里查看如何使用 Nomic v1.5 Matryoshka 模型
from sentence_transformers import SentenceTransformer from sentence_transformers.util import cos_sim import torch.nn.functional as F
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True)
matryoshka_dim = 64 embeddings = model.encode( [ "search_query: What is TSNE?", "search_document: t-distributed stochastic neighbor embedding (t-SNE) is a statistical method for visualizing high-dimensional data by giving each datapoint a location in a two or three-dimensional map.", "search_document: Amelia Mary Earhart was an American aviation pioneer and writer.", ], convert_to_tensor=True, ) # The Nomic team uses a custom architecture, making them recommend Layer Normalization before truncation embeddings = F.layer_norm(embeddings, normalized_shape=(embeddings.shape[1],)) embeddings[..., :matryoshka_dim] # Shrink the embedding dimensions
Kusupati, A., Bhatt, G., Rege, A., Wallingford, M., Sinha, A., Ramanujan, V., … & Farhadi, A. (2022). Matryoshka representation learning. Advances in Neural Information Processing Systems, 35, 30233-30249. https://arxiv.org/abs/2205.13147
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
Sublime Text
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。