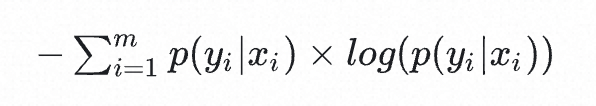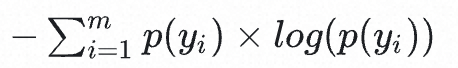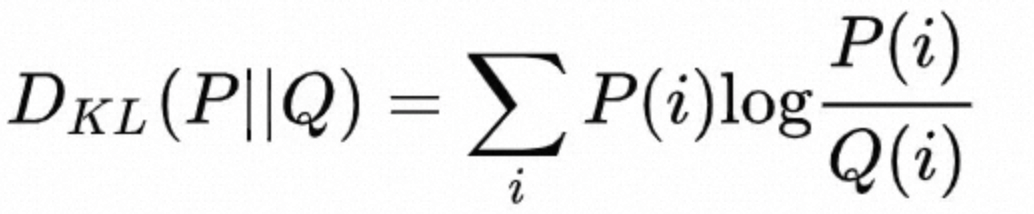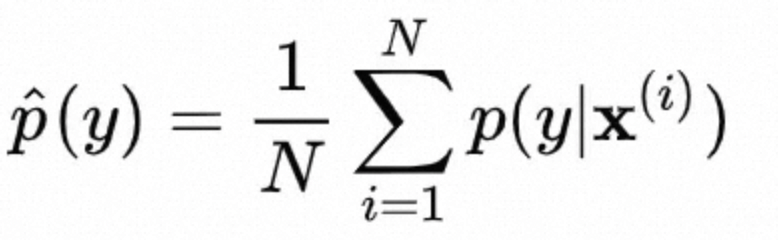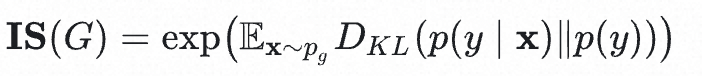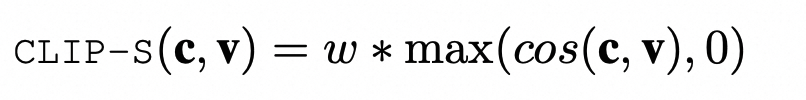![]()
本文总结了近10年来的生图模型论文中用到的评价指标,并尝试解答两个问题
-
不同时期的评价标准都有哪些特点?
-
图片质量的评价如何辅助模型的迭代?
随着各种文生图模型逐渐从toy project进入到生产链路,在线上实际落地并产生业务价值,同时自研/来源模型也进入了快速迭代的阶段。
一套直指问题、综合拓展性和复用性的评价指标变得尤为宝贵,从效果上来讲,如果说数据质量决定了模型效果的上限,那么指标的好坏直接决定了模型下限的位置。
2016年以前图像质量检测主要是在构建各种手动特征,最初图片质量是作为一个二类问题,后来根据不同的对象/场景衍生出多了分类的问题,2016年到2019年期间,GAN方法生成的图片越来越逼真,此时各家的指标更多的关注GAN生成图像和样本图像之间的差异以及生成图片的多样性(mode collapse)。
自2020年往后,transformor火遍机器学习圈,同时多模态大模型能力也越来越强,在图片美观度、真实度这种抽象的指标的评价在LLM上又有比较好的表现,同时因为zero-shot和few-shot的特性,在一些自定义的指标上LLM可以快速响应,对于使用方来说,这种方式也是更友好的。
在深度特征出现以前,传统方法设计了设计大量的手动特征特征来研究计算机美学这个问题。常见做法是通过各种图像变换产出不同的特征并通过一个有监督的模型评价评价整体的图片质量。
▐ 手动特征方法
一般来说我们希望图片主题明确,轮廓清晰,如下图左图内容就是一个较为杂乱的室内场景,右图明显优于左图,由于左图背景杂乱,图片边界有较多的边缘,而右图的边缘集中在图片中心。
具体实现方法,通过一个3*3的拉普拉斯滤波器对每一层通道进行边缘提取并取得均值,然后对整体resize到100*100的范围,将图片像素总和归一化,并分别投影到X轴和Y轴,取 边缘98%作为边框的大小(Wx,Wy),按照前文的假设,越杂乱的图片边缘像素点越多,最终图片的边框面积为 1-Wx*Wy,图a和图b的边框面积分别为0.94和0.56。
统计图片的色彩分布,最直观的就是颜色直方图。好的照片,一般会有一个统一的风格。或偏暖色,或偏冷色,这些都可以通过彩色直方图表征出来。同时,局部直方图的复杂程度,也可以反映出图像风格的一致性。
这是从色调的特性上来分享一张好图。一张好的静物摄影,色调一般会比较单一,不会五颜六色的各种颜色都杂糅在一起。
一般来说一个模糊图片的质量要比清晰图片的质量更差的,假设一张模糊的图片是经过用高斯平滑滤波器处理后的,那么要在仅知道模糊图片的情况下计算出平滑参数即可评估出图片质量,这里是通过一个二阶傅立叶变化并计算大于某个阈值a(这里使用5)的频率数量来表示清晰图片的最大频率,自此我们评估出图片质量的一个评分。如下,a图的质量分数为0.91,b图为0.58
▐ 深度特征
-
RAPID: Rating Pictorial Aesthetics using Deep Learning (ACM MM2014)
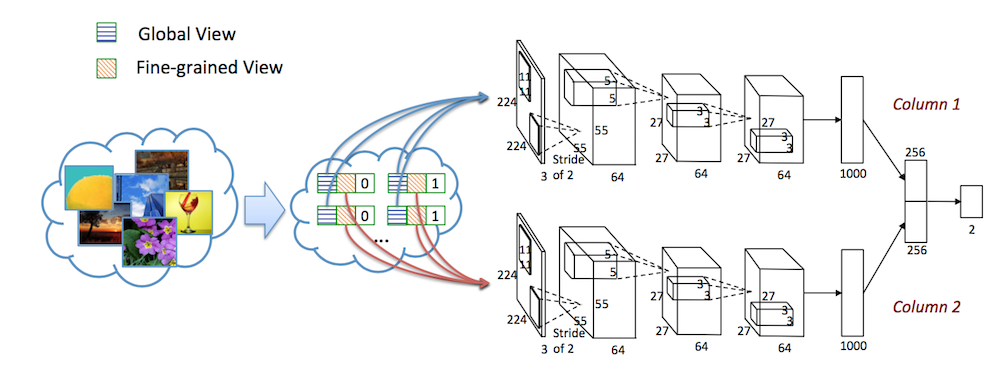
第一个使用深度学习做美学评分的论文了。作者考虑了在美学评估中要同时考虑整体布局和细节内容。因此作者除了将图片整体输入模型,还会从图片中抠出很多(patch)输入网络,两者结合起来进行分类。其在图片中抠取patch的方式在后续论文中都有借鉴。
-
Composition-preserving Deep Photo Aesthetics Assessment (CVPR 2016)
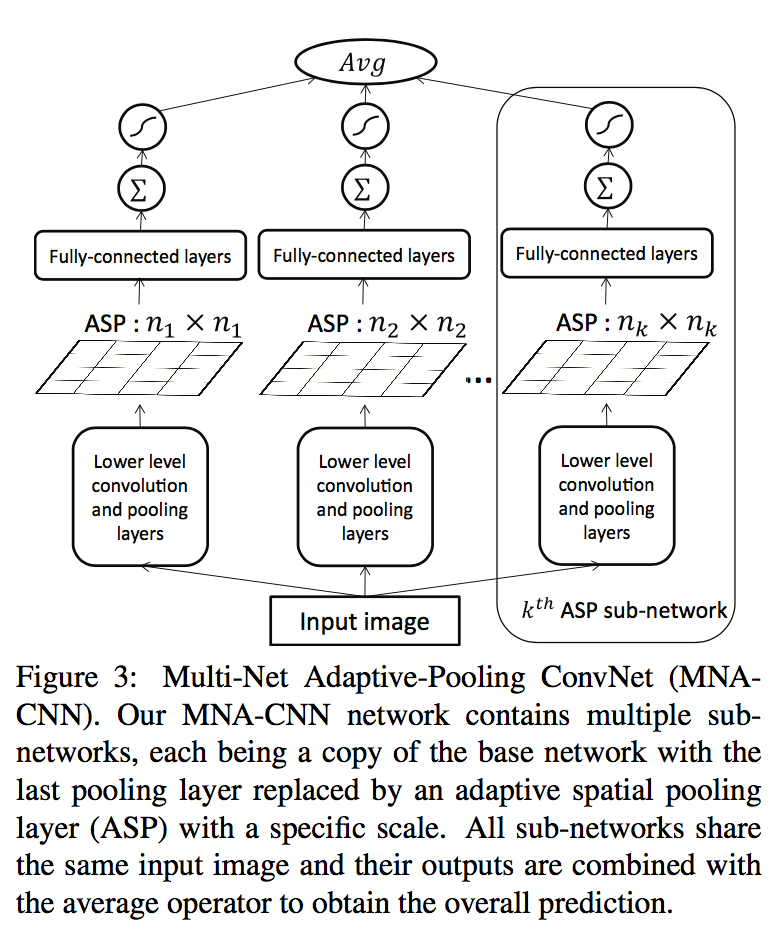
由于CNN中必须将图片resize到固定尺寸输入到网络,这种方式往往会破坏图片的布局,这种方法没有使用patch的分割方法,提出了一种Adaptive Spatial Pooling 的操作:动态地将不同 size 的 feature map 处理成指定的 size 大小,这个操作可以参考SPPNet。结合多个 Adaptive Spatial Pooling 得到多个 size 的 feature map。同时这时期一些论文也证明了场景语意信息对美学评分会有提升,后续论文也陆续尝试了将场景特征加入到网络中。
2016~2019
生成式对抗网络(Generative Adversarial Networks, GAN)自在2014年被Ian Goodfellow提出后,就在深度学习领域掀起了一场革命,GAN 主要分为两部分:生成模型和判别模型。生成模型的作用是模拟真实数据的分布,判别模型的作用是判断一个样本是真实的样本还是生成的样本,GAN 的目标是训练一个生成模型完美的拟合真实数据分布使得判别模型无法区分。从这里我们可以看出来,GAN的最终结果的好坏一定是要比较样本集和生成集的差距,同时为了不让最终的图片过于单一,多样性的指标也是要被考虑在内,又因为GAN本身是无监督的,一个好的评价方法(损失函数)直接会对结果造成影响。
▐ Inception Score(IS)
Inception Score(IS)FID中使用了Inception-v3,这个网络最初由google在2014年提出,用于ImageNet上的图片分类,输入一个图片,输出一个1000维的tensor代表输出类别,在GAN生成数据中常用来评价数据的多样性和数据的质量。
假定x为生成的图像,y为生成的图片的判别器的分类结果在IS中即为一个1000类别的分类,那么图片的质量越高则判别器的分类结果越稳定(属于某一个类别的概率越高),即P(y|x)的熵越小。
在此基础上,从一个图片集合的角度考虑,如果图片是多种多样的,那么他们涵盖的类目数也应该是尽可能多的,即P(y)的熵应该越大越好。
说到衡量两个概率分布的距离的方式,那就是KL散度了,KL散度的一般形式如下:
![]()
由于实际中,选取大量生成样本,用经验分布模拟 p(y):
![]()
最终得到的IS计算公式为:
![]()
其实还是求P(y|x)和P(y)的KL散度套了一个exp,并不影响最终的单调性。
-
当一个图片的类目本身并不确定,或者在原数据集中并没有出现过,那么此时的p(y|x)的概率密度就不再是一个尖锐的分布,而是趋于平缓,
-
不能判别出网络是否过拟合,当GAN生成数据和训练集完全相同时,会得到极高的IS分数,但是这种模型毫无作用。
-
如果某一个物体的类别本身就比较模糊,在几种类别会得到相近的分数,或者这个物体类别在ImageNet中不存在,那么p(y|x)的概率密度就不再是一个尖锐的分布;如果生成模型在每类上都生成了 50 个图片,那么生成的图片的类别边缘分布是严格均匀分布的,按照 Inception Score 的假设,这种模型不存在 mode collapse,但是,如果各类中的50个图片,都是一模一样的,仍然是 mode collapse(相同模式大量出现)。Inception Score 无法检测这种同类目下的重复出图的情况。
综上,Inception Score可以表现出数据的多样性和质量,适用于分类模型和生成模型数据集相近的情况,但是存在数值受内部权重影响较大和不能区分过拟合情况的问题,虽然在论文中非常常见,但是实际上生产使用的模型数据集会持续迭代,因此这个指标用于模型自身的迭代还是不够稳定。另外从文生图模型的角度来看,这个指标也无法表现模型对文本的响应程度。
▐ Fidelity (FID)
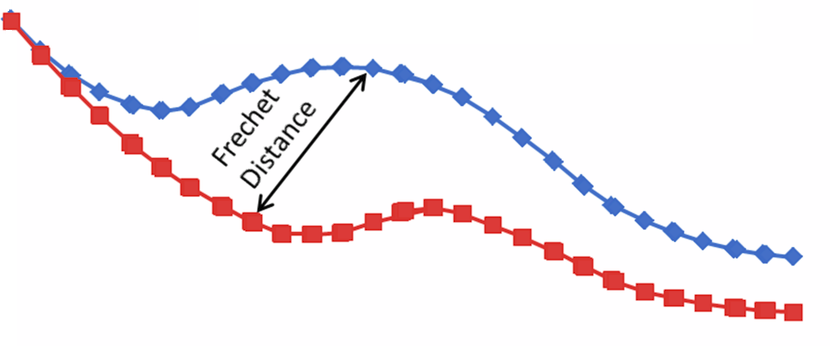
FID(Frechet Inception Distance)是GAN等定量评价指标之一,最早提出于2017年,由于IS在ImageNet上的局限性,当生成的数据样本超出ImageNet的范围时,该图片的效果是不好的,因此FID中使用的是生成数据分布和真实世界数据分布之间的距离,和Inception Score一样,FID也使用了Inception-v3模型,而FID并没有直接使用Inception-v3的分类结果,而是获取了最后一个池化层用于提取图片特征,通过计算两组图像(生成图像和真实图像)的均值和协方差,将激活函数的输出归纳为一个多变量高斯分布。然后将这些统计量用于计算真实图像和生成图像集合中的Frechet距离。同时因为Frechet距离关注的是多维空间中移动一个分布到另一个分布所需的“工作”量,所以对于不在ImageNet中,图片差距较大的情况下也可以有比较好的泛化能力。原文见https://arxiv.org/abs/1706.08500
![]()
Frechet距离的几何含义
-
FID和IS一样,依赖于现有特征的出现或不出现,即无法判断到生成的图片中产生的一些异常结构(头上出现一张嘴),这种情况FID也会认为是一张好图。
-
同IS,FID无法区分过拟合等。
-
FID中假设了激活函数的输出(2048维度的Inception特征)是符合高斯分布的,但实际上这在ReLU之后的结果恒为正数,所以在FID的计算方式下不存在无偏的评估指标。
相较于IS,FID更专注于对于图片真实性的评价,在样本集之外的数据中也有比较好的效果,在mode collapsing问题上也适用,适合用作IS之外的补充,作者也证明FID优于IS,因为它对图像中的细微变化更敏感,即高斯模糊、高斯模糊、椒盐噪声。FID使用Inception网络将生成图像集合和真实图像集合转换为保留图像高维信息的特征向量。假设这两个特征向量的分布为高斯分布,并计算其均值和协方差矩阵。通过测量概率分布之间的“距离”(相似程度)来评估生成图像与真实图像的相似程度。值越小,质量越高。
▐ Kernel Inception Distance(KID)
论文:https://openreview.net/pdf?id=r1lUOzWCW
按照作者的描述,KID没有像FID那样的正态分布的假设,是一种无偏的估计。不同的是将图像的2048维Inception特征通过maximum mean discrepancy(MMD)的方法分别求两个分布不同样本在映射空间中的值,用于度量两个分布之间的距离。通过比较生成样本和真实样本之间的距离来评价图片生成的效果。
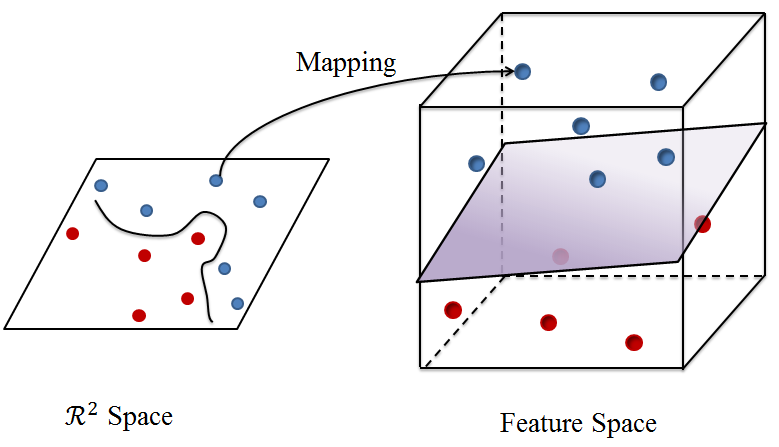
MMD是迁移学习中最常见的损失函数之一,MMD在设计之初重新考虑了对一个随机变量的表现形式,对于简单的方式我们可以给出一个概率分布函数,像正态分布函数,只要给出均值+方差就可以确定其分布,像高斯分布等,如果两个分布的均值和方差如果相同的话,这两个分布应该比较接近,但对于一些高阶的、复杂的随机变量,我们就没有办法给出其分布函数,也需要更高阶的参数(矩)描述一个分布。
论文《A Hilbert Space Embedding for Distributions》提出了一个高斯核函数,它对应的映射函数恰好可以映射到无穷维上,映射到无穷维上再求期望,正好可以得到随机变量的高阶矩。简单理解就是将一个分布映射到再生希尔伯特空间(RKHS)(每个核函数都对应一个RKHS)上的一个点,两个分布之间的距离就可以用两个点的内积进行表示。至此我们获得了一个随机变量的任意阶矩的表示。
![]()
当两个红点和蓝点在二维空间时,我们很难把他们分开,当映射到多维空间后事情就很容易了
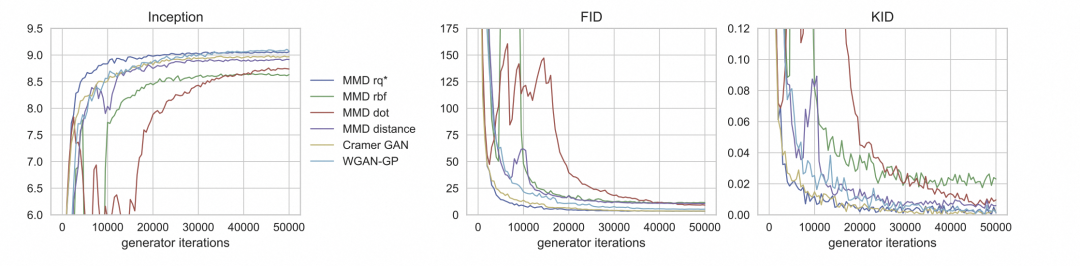
这种方法相比于FLD可以小数据集上更快达到稳定的效果。同时因为KID有一个三次核的无偏估计值,它更一致地匹配人类的感知。
![]()
对比FID,KID是无偏的,FID是有偏的,在时间效率上,FID为O(n),KID为O(n^2)
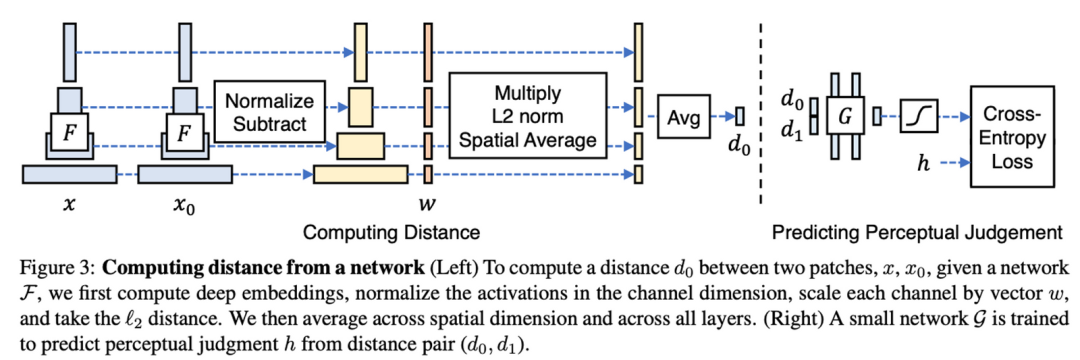
▐ Learned Perceptual Image Patch Similarity(LPIPS)
LPIPS在2018年提出,是一种基于深度方法提取图片比较两幅图片相似度的方法,相比于传统使用的L2、SSIM等方法,LPIPS方法尝试解决在判断相似度时更符合人类的感知。如下图:
![]()
实际上,两张图片是否相似,这是一个比较主观的结果,从人类判断的角度上来看,甚至可能受到视觉上下文的影响,该方法尝试不使用人工的判断来训练一个贴近人类感官的相似度的概念。从前文来看,通过深层网络的内部激活(即便是在图片分类任务上训练的)在更广泛的数据集也是可以适用的,也更符合人类的判断。
相比于FID,LPIPS 也是利用深度卷积网络的内部激活,不同的是,LPIPS衡量的是感知相似性,而不是质量评估。
▐ 总结
2016到2019期间,各家学者对生成图片度量的方法持续优化,基本上还是聚焦在“什么样的图片更贴近真实”,直到2018年,图片的真实性达到的一定水平,LPIPS提出对于图片的评价不仅局限于”有多真实“,同时关注到怎么样让图片效果更贴近人类的感官。
Transformer由谷歌团队在2017年论文《Attention is All You Need》提出,DDPM的UNet可以根据当前采样的t预测noise,但没有引入其他额外条件。但是LDM实现了“以文生图”,“以图生图”等任务,就是因为LDM在预测noise的过程中加入了条件机制,即通过一个编码器(encoder)将条件和Unet连接起来。一方面,图片生成的效果在这段时间大幅度提高,另一方面,可以通过自然语言控制生图模型的输出,模型的评价指标除了符合人类感官外,图像美学和图文对的匹配程度也是后期评价生图结果的重要指标。
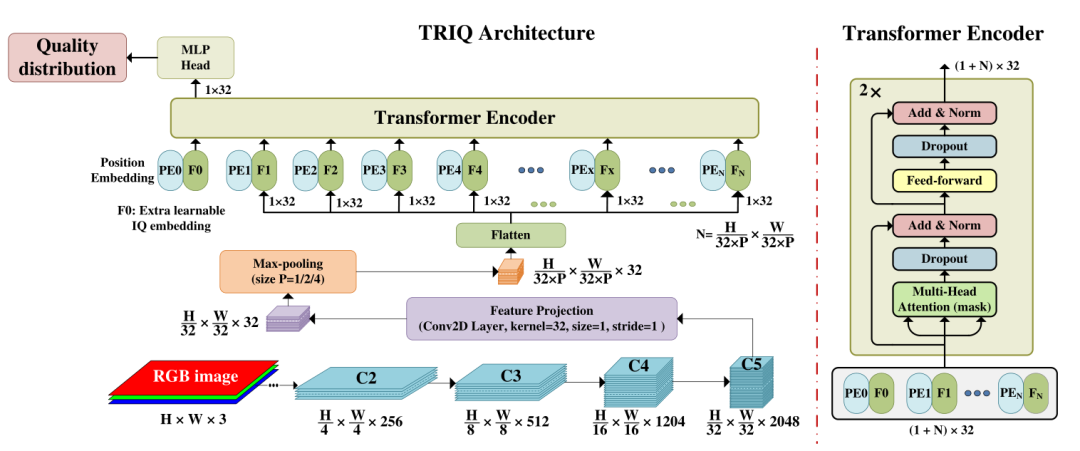
▐ Transformer for image quality(TRIQ)
这是第一个使用Transformer架构用于图片质量评价的模型,推出自2020年,主要思想是先使用卷积神经网络(CNN)提取特征,并在其上方使用了一个浅层Transformer编码器。为了处理不同分辨率的图像,该架构采用了自适应的位置嵌入。考虑到压缩图片的分辨率可能对图片质量校验造成负向的影响,TRIQ框架中保留了图片的原始大小,首先通过ResNet-50作为特征提取器,C5的输出在经过1*1的卷积之后可以得到H/32*W/32*32维的特征,考虑到大分辨率的图片会占用非常多的内存,这里在进入Transformer之前增加了一个池化层,会通过图片分辨率动态确定一个P值。
Transformer Encoder后的MLP网络头部由两个全连接(FC)层和一个中间的dropout层组成,用于预测感知图像质量,最终输出一个五维向量用于表述图片的质量分布。
![]()
code:https://github.com/junyongyou/triq
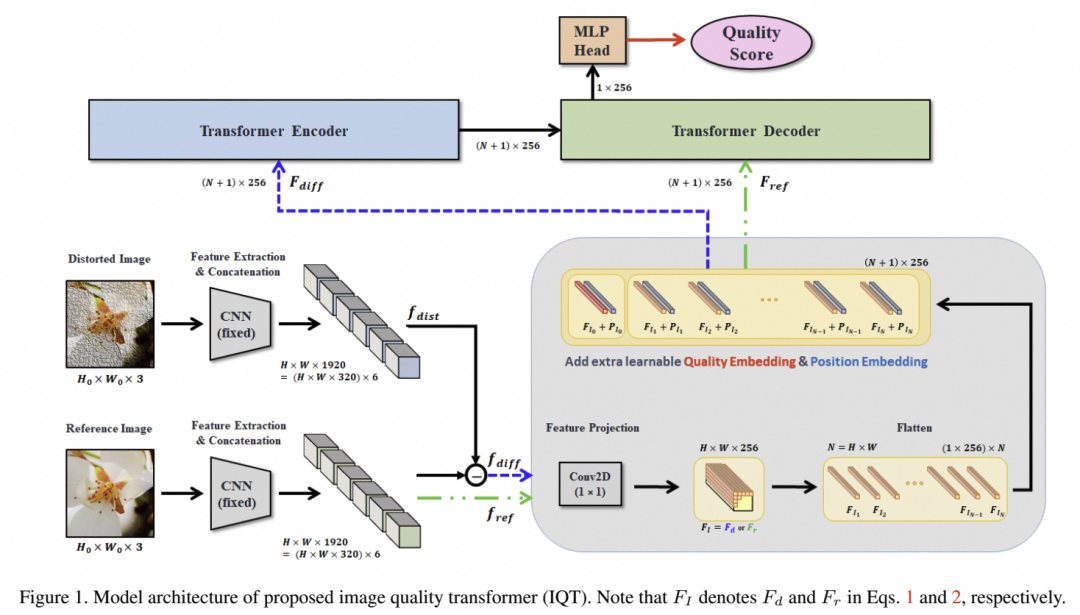
▐ Image Quality Transformer(IQT)
IQT方法提出于2021年,参考了TRIQ的方法,也是是一种基于transformer的图像质量评估(IQT),模型的输出结果更接近人类的感知结果,用于全参考图像质量评估,类似于LPIPS。作者宣称在CVPR 2021的NTIRE 2021挑战赛中获得Top1。如下图作者利用Inception-Resnet-V2 分别对生成图片和参考图片的提取感知特征表征,感知特征表征结果来自于6个中间层的输出并通过级联的结果,将参考图的特征向量(f ref),和参考图与生成图的特征向量取差值(f diff)并输入到Transformer;最后,transformer的输出通过一个MLP Head,用于预测一个最终的图像质量分数。
![]()
▐ CLIPScore
提出于2021年,这是一种用于评价文本和图片关联程度的方法,原理比较简单,通过一个跨模态检索模型分别对图像和文本进行embeding,并比较两者的余弦相似度。公式如下:
![]()
其中,c和v是CLIP编码器对Caption和图像处理输出的embedding,w作者设置为2.5。这个公式不需要额外的模型推理运算,运算速度很快,作者称在消费级GPU上,1分钟可以处理4k张图像-文本对。
▐ Aesthetic Predictor
目前自2022年之后,出现了基于CLIP+MLP的美学评价方案,创作者都表示“结果令人兴奋”,从大模型的能力可以YY到其在小样本的泛化性上必然非同凡响,同时可以衍生到不同的评价目标上,但是具体对比之前的方案怎么样就不得而知了。
laion在2022年提出的一个用于评估图片的美学评价模型,使用了clip-ViT-L-14模型和MLP组合,仅模型开源。
官网:https://laion.ai/blog/laion-aesthetics/
结果见:http://captions.christoph-schuhmann.de/aesthetic_viz_laion_sac+logos+ava1-l14-linearMSE-en-2.37B.html
-
CLIP+MLP Aesthetic Score Predictor
代码:https://github.com/christophschuhmann/improved-aesthetic-predictor
▐ Human Preference Score
2023往后,出现了用于预测图片是否符合人类偏好模型,这类模型多使用人工标注的图文偏好数据微调CLIP实现。
为了做 文生图Diffusion的奖励反馈学习对Diffusion进行调优,作者设计了ImageReward,一个由BLIP(ViT-L作为图像编码器的,12层Transformer作为文本编码器)+ MLP(打分器)组成的人类偏好预测模型。
-
Human Preference Score (HPS)
商汤在CLIP模型上基于798,090条人类偏好标注数据微调了这个模型,标注的图片来源于各类文生图模型的输出,据称其数据集是同类型数据集中最大的一个。其将clip模型视为一个评分器,用于计算提示词和图片的相关程度(同clipscore)。
code: https://github.com/tgxs002/HPSv2
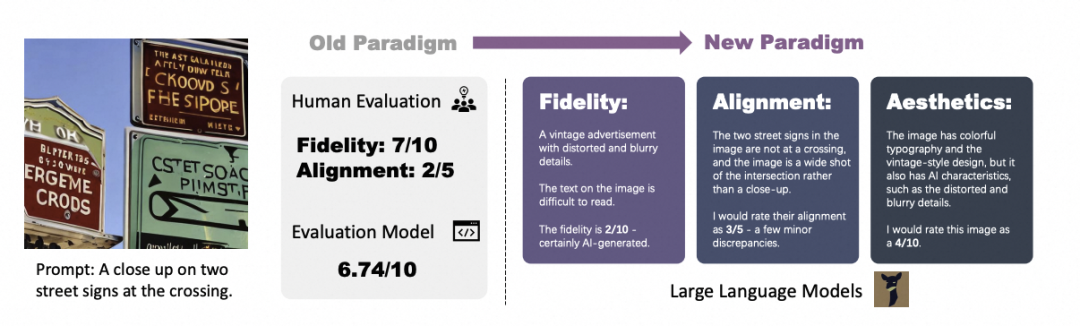
基于视觉大语言模型(MiniGPT-4)进行文本到图像生成的可解释图像质量评估,它从 Fidelity(真实度),Alignment(图文对应程度),Aesthetics(美观度)三个指标分别进行评分。从COCO和DrawBench数据集的测试结果上看,和ImgRwd和HPS接近。
主要的prompt见: https://github.com/Schuture/Benchmarking-Awesome-Diffusion-Models/blob/main/X-IQE/README.md
![]()
总结
从计算方法上看,似乎没有前一个时期那么精彩,通过微调CLIP再套用一个MLP几乎成为了这个时期的评价范式,但是评价指标要远比前一个时期更抽象和复杂。但这并不意味着FID这类指标已经没用了,相反,这个指标几乎在每个新模型的发布后都会拿出来比较。
本来只是想梳理一下图像质量度量的方法,但是层层挖掘却越可以看出图片生成模型的发展历程,从最初的 图像基础变换到人脸、动物,到现在可控制的图像生成,图片生成技术越来越趋于专业性,我们审视一张图片的方式从“能看懂”到 “像真的”到“符合美学标准“,可以想到未来一套美学标准是无法通吃的,对于不同行业和场景,生图模型会越来越细分,而美学标准也会随之分化。
![]()
-
Heusel, Martin et al. “GANs Trained by a Two Time-Scale Update Rule Converge to a Nash Equilibrium.” ArXiv abs/1706.08500 (2017): n. pag.
-
https://www.jiqizhixin.com/articles/2019-01-10-18
-
Dziugaite, Gintare Karolina et al. “Training generative neural networks via Maximum Mean Discrepancy optimization.” Conference on Uncertainty in Artificial Intelligence (2015).
-
Binkowski, Mikolaj et al. “Demystifying MMD GANs.” ArXiv abs/1801.01401 (2018): n. pag.
-
https://www.jiqizhixin.com/articles/2019-01-10-18
-
https://laion.ai/blog/laion-aesthetics/
-
https://www.jianshu.com/p/fc5526b1fe3b#comments
-
https://deep-generative-models.github.io/files/ppt/2021/Lecture%2019%20Evaluation%20-%20Sampling%20Quality.pdf
-
Zhang, Richard et al. “The Unreasonable Effectiveness of Deep Features as a Perceptual Metric.” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (2018): 586-595.
-
You, Junyong and Jari Korhonen. “Transformer For Image Quality Assessment.” 2021 IEEE International Conference on Image Processing (ICIP) (2020): 1389-1393.
-
Cheon, Manri et al. “Perceptual Image Quality Assessment with Transformers.” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2021): 433-442.
-
Hessel, Jack et al. “CLIPScore: A Reference-free Evaluation Metric for Image Captioning.” ArXiv abs/2104.08718 (2021): n. pag.
-
Wu, Xiaoshi et al. “Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis.” ArXiv abs/2306.09341 (2023): n. pag.
-
https://www.e-learn.cn/topic/1480759
![]() 我们是淘天集团-场景智能技术团队,一支专注于通过AI和3D技术驱动商业创新的技术团队, 依托淘宝天猫丰富的业务形态和海量的用户、数据, 致力于为消费者提供创新的场景化导购体验, 为商家提供高效的场景化内容创作工具, 为淘宝天猫打造围绕家的场景的第一消费入口。我们不断探索并实践新的技术, 通过持续的技术创新和突破,创新用户导购体验, 提升商家内容生产力, 让用户享受更好的消费体验, 让商家更高效、低成本地经营。
我们是淘天集团-场景智能技术团队,一支专注于通过AI和3D技术驱动商业创新的技术团队, 依托淘宝天猫丰富的业务形态和海量的用户、数据, 致力于为消费者提供创新的场景化导购体验, 为商家提供高效的场景化内容创作工具, 为淘宝天猫打造围绕家的场景的第一消费入口。我们不断探索并实践新的技术, 通过持续的技术创新和突破,创新用户导购体验, 提升商家内容生产力, 让用户享受更好的消费体验, 让商家更高效、低成本地经营。