一、解决什么问题
一个任务中心技术实现的参考案例,可以快速部署实现且仅需关注业务个性落库逻辑实现,其他如任务状态维护、数据解析及异常包装、结果导出均由工具自动实现。
二、基本原理
图1 请求示意图
异步任务中心共分三个模块:
1)任务初始化, 将目标导入文件上传至云存储后得到目标文件url按任务类型(如类目导入、商品导入等)入库任务表并返回前台提交成功,任务初始状态为"待处理";
2)任务调度,使用开源调度组件xxlJob开箱即用。传送门: xxlJob
3)任务Worker执行器核心组成:
1.任务并行分片拉取
分片广播模式下,每个worker按index取模 获取应执行的任务id,参考sql :
from task where status in ('PENDING','FAILURE') and errCnt <= MAX_RETRY_CNT and mod(id,#总worker数量) = 当前worker index
2.根据任务类型命中执行器策略
任务类型: 即导入业务的枚举字段,如类目导入CATE_IMPORT、商品导入PRODUCT_IMPORT等
业务执行器: 执行excel批量导入解析落库的载体,下文介绍。
策略如何命中: 业务执行器class类增加@JobExecutor注解并指明注解值为对应任务类型; 拉取任务后寻找有@JobExecutor修饰的类且其注解值等于任务记录任务类型即为命中目标执行器
3.执行器设计
A.抽象任务接口并定义行为 -> BaseJob<T>
•accept() 接受任务,实现后置任务状态为"处理中"
•parse() 解析任务, 负责解析目标文件(zip、xlsx)为List<Bean>,并实现数据校验
•run() 将业务数据List<Bean>数据落库
•export() 生成导入结果文件,上传至云存储并更新到任务记录结果列
•errHandle() 异常处理,置任务状态为"失败",累计任务失败次数,触发业务报警
B.基础抽象实现类 -> BaseExecutableAbsJob implements BaseJob
accept() 、export()、errHandle() 步骤因其业务无关性故在此抽象类中做通用默认实现;
parse() 有一定通用性,默认实现为excel解析(easyExcel实现)
run() 业务相关不做默认实现,由继承方实现
C.一次性解析抽象实现 -> DisposableAbsJob extends BaseExecutableAbsJob
特征:
解析规则为一次性解析excel所有记录,不适用超大excel解析job
可以在落库前获得全部业务实体信息
导出结果可以显示原始输入
D.分批解析通用实现类 -> BatchableAbsJob extends BaseExecutableAbsJob
特征:
解析规则为按BATCH_CNT来分段操作数据解析及入库,适用于大excel导入场景的使用
解析完毕前拿不到记录总数
导出结果不显示原始输入,仅显示MAX_ERROR_CNT数量以内的错误记录原始信息及错误信息。
三、快速使用
业务类按场景选择继承DisposableAbsJob或BatchableAbsJob,
仅需重写落库方法,其他如拉取、解析、导出结果步骤均由系统自动执行。如需特殊解析逻辑(比如解析zip按特定规则拼装bean)重写parse()方法即可
举个栗子,现需求场景为批量类目信息导入, 则开发过程为:
步骤一 : 落库任务类型为TaskBizTypeEnum.CATE_BATCH_PUBLISH的记录到任务表中,并记录前台上传的excel导入文件url(常规crud本案例不做封装,自行实现即可)
步骤二 : 定义类目Excel导入实体Bean
/**
* 类目导入实体
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
@EqualsAndHashCode(callSuper = true)
public class ImportCateExcelDTO extends BaseWorkerDTO {
/** 类目级别*/
@ExcelProperty(index = 0,converter = CateLevelConverter.class,value = "类目级别")
private Integer cateLevel;
/** 类目中文名*/
@ExcelProperty(index = 1 ,value = "类目中文名")
private String cateName;
/** 类目排序*/
@ExcelProperty(index = 2 ,value = "类目排序")
private Integer sort;
/** 上级类目id*/
@ExcelProperty(index = 3 ,value = "上级管理类目id")
private Long parentCateId;
/** 状态*/
@ExcelProperty(index = 4,converter = StatusConverter.class ,value = "状态")
private Integer status;
}
步骤三 : 编写业务实现类,并自行实现run落库方法.
/**
* 类目批量导入(一次性解析全部excel)
*/
@Service
@Slf4j
@JobExecutor(taskBizType = TaskBizTypeEnum.CATE_BATCH_PUBLISH) // 策略注解,枚举类型全局唯一。 不加该注解则任务调度找不到策略
public class DisposableCateImportHandler extends DisposableAbsJob<ImportCateExcelDTO> {
@Resource
private XXXXService xxxxService;
@Override
public void run(TaskDTO<ImportCategoryExcelDTO> task){
try{
if(CollectionUtils.isNotEmpty(task.getTarget())){
xxxxService.save(task.getTarget())
}
}catch (BaseImportException e){
errHandle(task);
}
}
}
至此开发部分结束,任务执行器会自动调度拉取CATE_BATCH_PUBLISH类型的任务 -> 解析到List<Bean> -> 调用你的run()方法实现落库 -> 将结果流上传到云存储并将结果链接更新到任务表中
四、源码
1. TaskDispatcher - 任务调度派发
/**
* 任务调度派发
*/
@Component
@Slf4j
public class TaskDispatcher {
@Resource
private TaskMangeService taskMangeService;
@Resource
private ApplicationContext applicationContext;
@SneakyThrows
@XxlJob("iscWorker")
public ReturnT<String> iscWorker(String param) {
TaskDTO task = taskMangeService.pullTask();
if(task!=null){
BaseJob executor = getExecutor(task.getTask().getBizType());
if(null!=executor){
executor.of(task).start();
log.info("iscWorker 执行完毕:{} " , JSON.toJSONString(task));
}
}
return ReturnT.SUCCESS;
}
//获取执行器
public BaseJob getExecutor(TaskBizTypeEnum taskBizType){
Map<String, Object> beanMap = applicationContext.getBeansWithAnnotation(JobExecutor.class);
if(beanMap.isEmpty()){
return null;
}
log.info("TaskDispatcher.getExecutor class list:{}" , beanMap.keySet());
for (Map.Entry<String,Object> entry : beanMap.entrySet()) {
try {
JobExecutor ano = AnnotationUtil.getAnnotation(entry.getValue().getClass(), JobExecutor.class);
if(taskBizType.equals(ano.taskBizType()) && entry.getValue() instanceof BaseJob){
log.info("TaskDispatcher.getExecutor 当前任务:{}命中执行策略job:{}" , taskBizType, entry.getValue());
return (BaseJob) entry.getValue();
}
}catch (Exception e){
e.printStackTrace();
}
}
return null;
}
}
2. DisposableAbsJob - 一次性解析任务执行器
/**
* 一次性解析任务执行器,解析规则为一次性解析所有excel记录,不适用超大excel解析job
* 使用方法: 1.使用方继承DisposableAbsJob类,并根据需要重写parse方法(当前默认是按excel解析)
* 2.重写run方法,将解析好的list<Bean>推入数据库
*/
@Component
@Slf4j
public abstract class DisposableAbsJob<T extends BaseWorkerDTO> extends BaseExecutableAbsJob<T> {
//自有个性逻辑,默认就是空逻辑
}
3. BatchableAbsJob - 分段解析任务执行器
/**
* 批次解析任务执行器,解析规则为分批解析excel记录,适用超大excel解析job
* 使用方法: 1.使用方继承BatchableAbsJob类,重写saveOrUpdate方法和excel2Po方法,
*/
@Component
@Slf4j
public abstract class BatchableAbsJob<T extends BaseWorkerDTO,K> extends BaseExecutableAbsJob<T> {
/**
* 批次解析逻辑
* @param task
*/
@Override
public void parse(TaskDTO<T> task){
if(TaskCreateTypeEnum.IMPORT.equals(task.getTaskCreateType())){
log.info("BaseExecutableAbsJob.import parse {} ",task.getTaskId());
BaseBatchExcelDataListener<T,K> listener = new BaseBatchExcelDataListener<>(this);
EasyExcel.read(task.getTargetInputFile().getObjectContent(), getTargetClass(), listener).sheet().doRead();
task.setErrDataList(listener.errDataList);
}
}
/** 批次解析结果逻辑,仅导出有问题的记录(上限100条) */
@Override
public void export(TaskDTO<T> task){
if(task!=null){
log.info("BatchableAbsJob.export {}", task.getTaskId());
if(CollectionUtils.isEmpty(task.getErrDataList())){
taskMangeService.update(new TaskVO(task.getTaskId(), TaskStatusEnum.SUCCESS));
log.info("BatchableAbsJob.export 任务{}全部执行成功" , task.getTaskId());
return;
}
String resultName = task.getFileName() + Constant.UNDER_LINE + System.currentTimeMillis() + ".xlsx";
ByteArrayOutputStream targetOutputStream = new ByteArrayOutputStream();
try (ExcelWriter excelWriter = EasyExcel.write(targetOutputStream).build()) {
if (CollectionUtils.isNotEmpty(task.getErrDataList())) {
excelWriter.write(task.getErrDataList(), EasyExcel.writerSheet(0, "result").head(BatchResultDTO.class).build());
}
task.setEndTime(System.currentTimeMillis());
excelWriter.finish();
try (ByteArrayInputStream inputStream = new ByteArrayInputStream(targetOutputStream.toByteArray())) {
task.setResultUrl(s3Utils.upload(inputStream, FileTypeEnum.BATCH_FILE.getCode(),resultName));
taskMangeService.update(new TaskVO(task.getTaskId(), TaskStatusEnum.SUCCESS, task.getResultUrl()));
}
} catch (Exception e) {
log.error("BaseExecutableAbsJob.export error, target:{} ", task.getTaskId(), e);
throw new TaskExportException(task.getTaskId() + e.getMessage());
} finally {
log.info("BaseExecutableAbsJob.export 任务「{}」执行完毕:{},文件地址:{}", task.getTaskId(), task.getOssPutMd5(), task.getResultUrl());
}
}
}
public List<BatchResultDTO> saveOrUpdate(Map<Integer, K> k) {
return null;
}
public Map<Integer,K> excel2Po(Map<Integer, T> excel) {
return null;
}
}
4. BaseExecutableAbsJob - 通用抽象任务执行器
/**
* 通用抽象任务执行器
*/
@Component
@Slf4j
public abstract class BaseExecutableAbsJob<T extends BaseWorkerDTO> implements BaseJob<T> {
@Resource
public S3Utils s3Utils;
@Resource
public TaskMangeService taskMangeService;
public final static String RESULT_FOLDER = "xxx";
@Override
public void accept(TaskDTO<T> task){
//导入类任务
if(TaskCreateTypeEnum.IMPORT.equals(task.getTask().getCreateType())){
task.setTargetInputFile(s3Utils.download(task.getTask().getReqParam()));
task.setFileName(task.getTask().getName());
//导出类任务
}else if(TaskCreateTypeEnum.EXPORT.equals(task.getTask().getCreateType())){
// 方式1. 保存 前台勾选的记录id到任务入参中
// 方式2. 根据前台勾选的查询条件命中记录id,再保存到任务入参中<限制总导出记录数>
String req = task.getTask().getReqParam();
if(StringUtils.isNotBlank(req)){
task.setKey(Arrays.stream(req.split(Constant.COMMA)).map(Long::valueOf).collect(Collectors.toSet()));
}
}
task.setTaskBizTypeEnum(task.getTask().getBizType());
task.setTaskId(task.getTask().getId());
task.setStartTime(System.currentTimeMillis());
//更新任务状态
taskMangeService.update(new TaskVO(task.getTaskId(),TaskStatusEnum.PROCESSING));
}
/**
* 通用解析逻辑
* @param task
*/
@Override
public void parse(TaskDTO<T> task){
if(TaskCreateTypeEnum.IMPORT.equals(task.getTaskCreateType())){
if(task.getTargetInputFile()!=null && task.getTargetInputFile().getObjectContent()!=null){
List<T> target = EasyExcel.read(task.getTargetInputFile().getObjectContent(), getTargetClass() ,
new PageReadListener<T>(dataList -> {})).sheet(0).headRowNumber(1).doReadSync();
task.setTarget(target);
}
}
}
/**
* 导入通用落库逻辑/导出构建list<Bean>逻辑
* @param task
*/
@Override
public void run(TaskDTO<T> task){ }
@Override
public void export(TaskDTO<T> task){
if(task!=null){
if(CollectionUtils.isEmpty(task.getTarget())){
taskMangeService.update(new TaskVO(task.getTaskId(), TaskStatusEnum.SUCCESS));
log.info("BaseExecutableAbsJob.export 空任务{},跳过执行" , task.getTaskId());
return;
}
String resultName = RESULT_FOLDER + task.getTaskBizTypeEnum().getName() + Constant.UNDER_LINE + System.currentTimeMillis() + ".xlsx";
ByteArrayOutputStream targetOutputStream = new ByteArrayOutputStream();
try (ExcelWriter excelWriter = EasyExcel.write(targetOutputStream).build()) {
if (CollectionUtils.isNotEmpty(task.getTarget())) {
excelWriter.write(task.getTarget(), EasyExcel.writerSheet(0, "result").head(getTargetClass()).build());
}
task.setEndTime(System.currentTimeMillis());
excelWriter.finish();
try (ByteArrayInputStream inputStream = new ByteArrayInputStream(targetOutputStream.toByteArray())) {
task.setResultUrl(s3Utils.upload(inputStream, FileTypeEnum.BATCH_FILE.getCode(),resultName));
taskMangeService.update(new TaskVO(task.getTaskId(), TaskStatusEnum.SUCCESS, task.getResultUrl()));
}
} catch (Exception e) {
log.error("BaseExecutableAbsJob.export error, target:{} ", task.getTaskId(), e);
throw new TaskExportException(task.getTaskId() + e.getMessage());
} finally {
log.info("BaseExecutableAbsJob.export 任务「{}」执行完毕:{},文件地址:{}", task.getTaskId(), task.getOssPutMd5(), task.getResultUrl());
}
}
}
@Override
public void errHandle(TaskDTO<T> taskDTO,Exception e){
taskMangeService.errHandle(taskDTO,e.toString());
}
public Class<T> getTargetClass(){
Type res = getClass().getGenericSuperclass();
if(res instanceof ParameterizedType){
ParameterizedType pRes = (ParameterizedType) res;
Type[] type = pRes.getActualTypeArguments();
if(type.length>0){
if(type[0] instanceof Class){
Type typeE = type[0];
return (Class<T>)typeE;
}
}
}
return null;
}
}
5. BaseBatchExcelDataListener - 批处理excel解析监听器
/**
* 批处理excel解析监听器
* @param <T> Excel DTO
* @param <K> 落库 PO
*/
@Slf4j
public class BaseBatchExcelDataListener<T extends BaseWorkerDTO,K> implements ReadListener<T> {
private static final int BATCH_COUNT = 100;
private static final int MAX_ERROR_COUNT = 100;
/** 业务服务*/
private final BatchableAbsJob<T,K> batchableAbsJob;
/** 每批待处理业务数据*/
private Map<Integer,T> cachedDataList = Maps.newHashMapWithExpectedSize(BATCH_COUNT);
/** 业务处理失败数据,行号&错误报文 */
public List<BatchResultDTO> errDataList = Lists.newArrayListWithExpectedSize(MAX_ERROR_COUNT) ;
public BaseBatchExcelDataListener(BatchableAbsJob<T,K> batchableAbsJob) {
this.batchableAbsJob = batchableAbsJob;
}
@Override
public void invoke(T data, AnalysisContext context) {
cachedDataList.put(context.readRowHolder().getRowIndex(),data);
if (cachedDataList.size() >= BATCH_COUNT) {
saveData();
cachedDataList = Maps.newHashMapWithExpectedSize(BATCH_COUNT);
}
}
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
saveData();
}
/** 持久化 */
private void saveData() {
Map<Integer, K> po = batchableAbsJob.excel2Po(cachedDataList);
if(po!=null && !po.isEmpty()){
List<BatchResultDTO> errRes = batchableAbsJob.saveOrUpdate(po);
if(errDataList.size()<MAX_ERROR_COUNT && CollectionUtils.isNotEmpty(errRes)){
errDataList.addAll(errRes);
}
}
}
}
6. BaseJob - 任务接口
public interface BaseJob<T> {
void accept(TaskDTO<T> task);
void parse(TaskDTO<T> task);
void run(TaskDTO<T> task);
void export(TaskDTO<T> task);
void errHandle(TaskDTO<T> task,Exception e);
default AbsExecutor<Void> of(TaskDTO<T> task){
return () -> {
try {
accept(task);
try {
parse(task);
}finally {
if(task.getTargetInputFile()!=null){
task.getTargetInputFile().close();
}
}
run(task);
export(task);
}catch (Exception e){
errHandle(task,e);
}
return null;
};
}
}
7. JobExecutor- 策略注解
/**
* 任务执行器
*/
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface JobExecutor {
//任务业务类型
TaskBizTypeEnum taskBizType() ;
}
8. TaskMangeService- 任务执行类
/**
* 任务读写服务
*/
@Service
@Slf4j
public class TaskMangeServiceImpl extends BaseManageSupportService<TaskVO, TaskPO> implements TaskMangeService {
private final static Integer MAX_ERR_CNT = 2;
private final static Long LIMIT = 1L;
@Override
public TaskPO saveOrUpdate(TaskVO taskVO) {
return taskService.save(input);
}
@Override
public Page<TaskPO> hashList(TaskReqVO taskReqVO) {
Page<TaskPO> page = Page.of(taskReqVO.getIndex(), taskReqVO.getSize());
LambdaQueryWrapper<TaskPO> wrapper = Wrappers.<TaskPO>lambdaQuery()
.in(CollectionUtils.isNotEmpty(taskReqVO.getStatus()), TaskPO::getStatus, taskReqVO.getStatus())
.eq(taskReqVO.getBizType() != null, TaskPO::getBizType, taskReqVO.getBizType())
.le(taskReqVO.getErrCnt() != null, TaskPO::getErrCnt, taskReqVO.getErrCnt())
.apply("mod(id," + taskReqVO.getShardTotal() + ") =" + taskReqVO.getShardIndex() + " ")
.orderByAsc(TaskPO::getCreateTime);
return taskService.page(page, wrapper);
}
private TaskVO getTask(String fileName,String pin, String key,TaskBizTypeEnum bizType,TaskCreateTypeEnum taskCreateType){
// build task
return res;
}
@Override
public TaskDTO pullTask(){
TaskDTO target = null;
ShardingUtil.ShardingVO shardingVo = ShardingUtil.getShardingVo();
log.info("iscWorker.pullTask workerIndex: {}, total:{}" , shardingVo.getIndex(),shardingVo.getTotal());
TaskReqVO queryDTO = new TaskReqVO();
queryDTO.setShardIndex(shardingVo.getIndex());
queryDTO.setShardTotal(shardingVo.getTotal());
queryDTO.setStatus(Lists.newArrayList(TaskStatusEnum.PENDING,TaskStatusEnum.FAILURE));
queryDTO.setErrCnt(MAX_ERR_CNT);
queryDTO.setIndex(0L);
queryDTO.setSize(LIMIT);
Page<TaskPO> targetList = hashList(queryDTO);
if(CollectionUtils.isNotEmpty(targetList.getRecords())){
log.info("PublishMkuBySkuWorker.pullTask 准备执行:{}" , JSON.toJSONString(targetList));
target = new TaskDTO<>(targetList.getRecords().get(0));
}
return target;
}
@Override
public Boolean error(TaskVO taskInfo) {
return task.update(taskInfo);
}
/** 失败处理*/
@Override
public void errHandle(TaskDTO task, String errMsg){
error(new TaskVO(task.getTaskId()));
Profiler.businessAlarm(UmpKeyConstant.BUSINESS_KEY_TASK_WARNING,("excel批量导入-任务执行异常:"+errMsg+task.getTaskId()));
log.info("TaskMangeServiceImpl.errHandle 任务Id{}执行失败:{}", task.getTaskId(),errMsg);
}
}
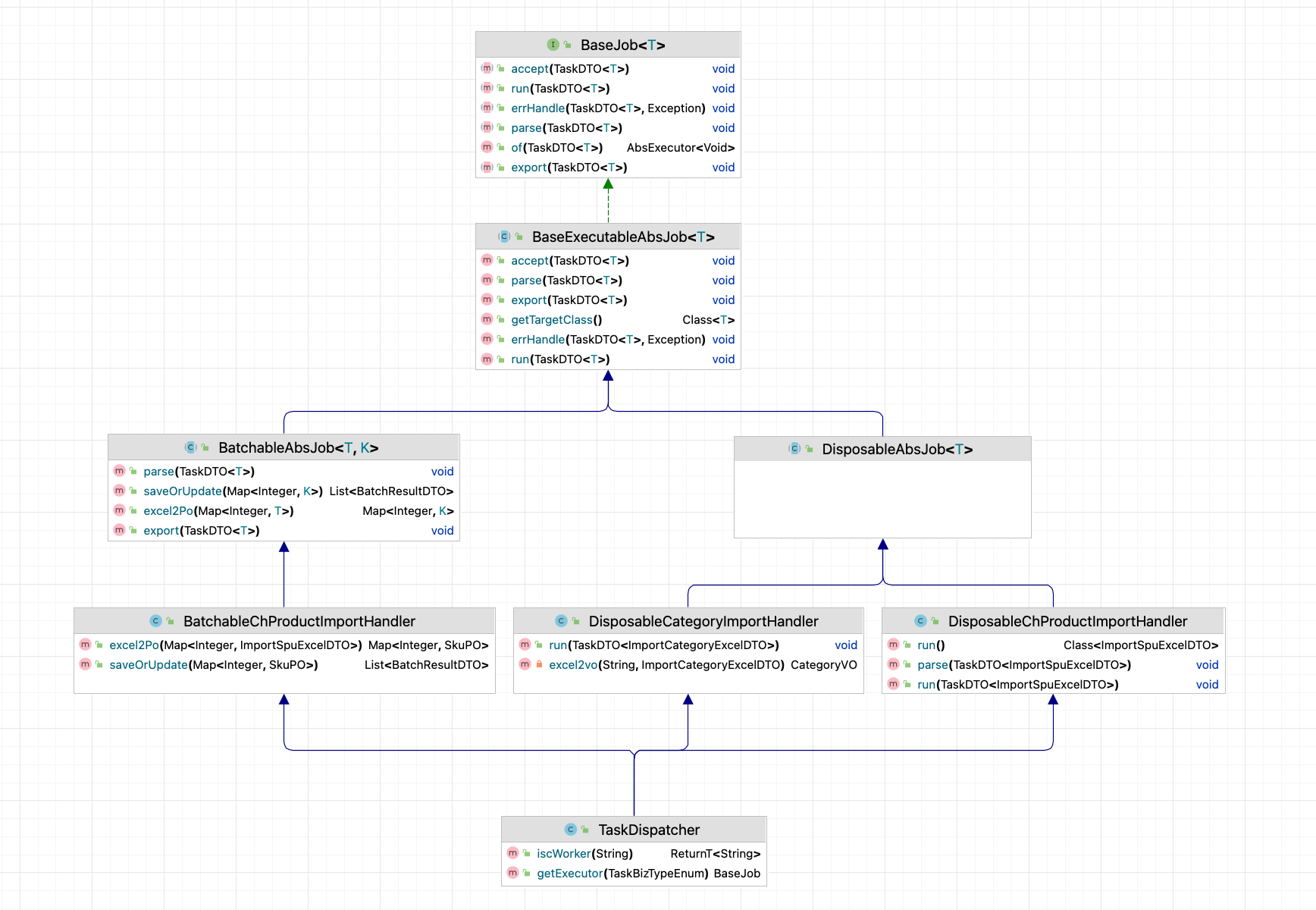
五、类图
图2 类图
作者:京东工业 于洋
来源:京东云开发者社区 转载请注明来源