本文介绍了Apache DolphinScheduler的内置参数及其用于调度的应用,包括基础和衍生参数的使用方法。
![file]()
此外,文章还详细阐述了如何在 DolphinScheduler 中引用依赖资源,例如使用资源中心管理文件和引用脚本,以 Shell 任务为例进行说明。
内置参数
DolphinScheduler提供了一些时间相关的系统参数,方便定时调度使用。
1)基础内置参数
| 变量名 |
参数 |
说明 |
| system.biz.date |
${system.biz.date} |
定时时间前一天,格式为 yyyyMMdd |
| system.biz.curdate |
${system.biz.curdate} |
定时时间,格式为 yyyyMMdd |
| system.datetime |
${system.datetime} |
定时时间,格式为 yyyyMMddHHmmss |
2)衍生内置参数
可通过衍生内置参数,设置任意格式、任意时间的日期。
(1)自定义日期格式
可以对[yyyyMMdd],[yyyyMM-dd]。
(2)使用add_months() 函数
该函数用于加减月份, 第一个入口参数为[yyyyMMdd],表示返回时间的格式 第二个入口参数为月份偏移量,表示加减多少个月。
| 参数 |
说明 |
| $[add_months(yyyyMMdd,12*N)] |
后 N 年 |
| $[add_months(yyyyMMdd,-12*N)] |
前 N 年 |
| $[add_months(yyyyMMdd,N)] |
后 N 月 |
| $[add_months(yyyyMMdd,-N)] |
前 N 月 |
(3)直接加减数字
在自定义格式后直接“+/-”数字,单位为“天”。
| 参数 |
说明 |
| $[yyyyMMdd+7*N] |
后 N 周 |
| $[yyyyMMdd-7*N] |
前 N 周 |
| $[yyyyMMdd+N] |
后 N 天 |
| $[yyyyMMdd-N] |
前 N 天 |
| $[HHmmss+N/24] |
后 N 小时 |
| $[HHmmss-N/24] |
前 N 小时 |
| $[HHmmss+N/24/60] |
后 N 分钟 |
| $[HHmmss-N/24/60] |
前 N 分钟 |
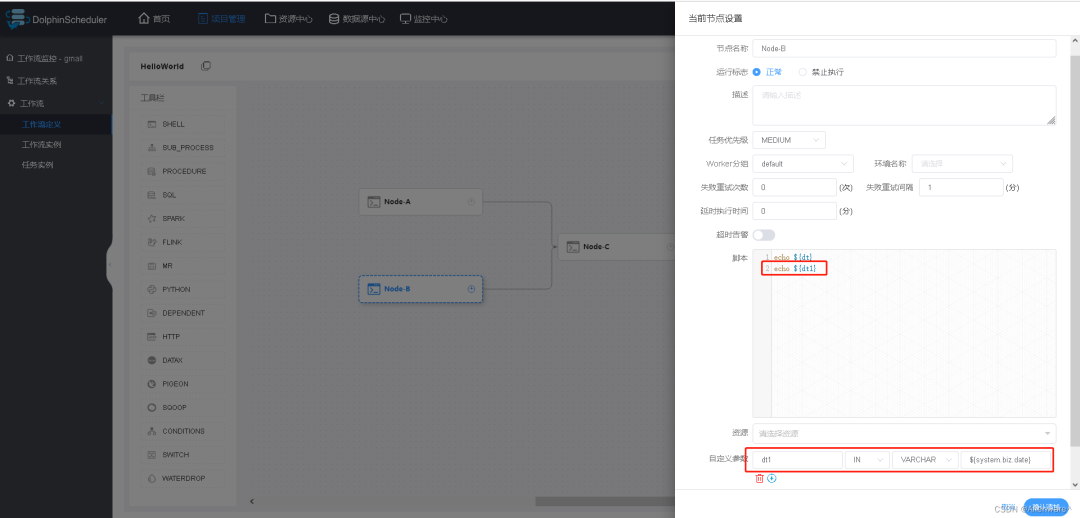
3)配置示例
若执行的脚本需要一个格式为 yyyy-MM-dd 的前一天日期的参数,进行如下配置即可
${system.biz.date}
![file]()
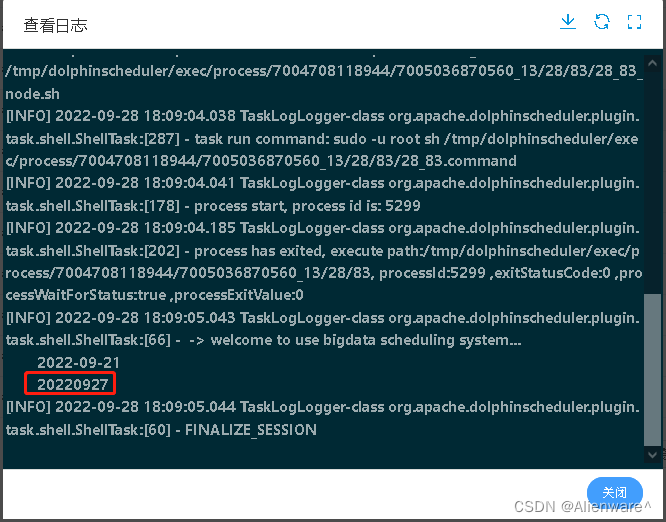
日志结果如下
![file]()
引用依赖资源
有些任务需要引用一些额外的资源,例如 MR、Spark 等任务须引用 jar 包,Shell 任务需要引用其他脚本等。DolphinScheduler 提供了资源中心来对这些资源进行统一管理。资源中心存储系统可选择本地文件系统或者 HDFS 等。资源中心除了提供文件资源管理功能,还提供了 Hive 自定义函数管理的功能。
下面以 Shell 任务为例,演示如何引用资源中心的其他脚本。
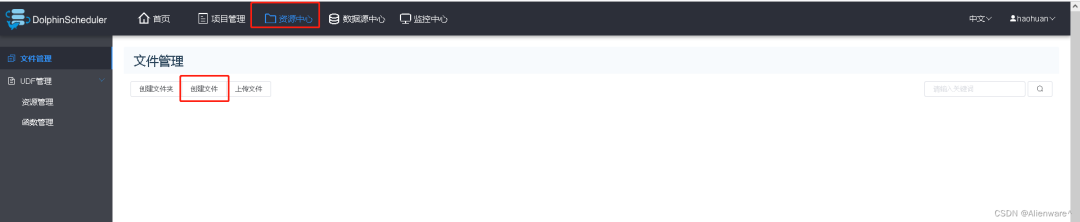
1)点击资源中心,点击创建文件
![file]()
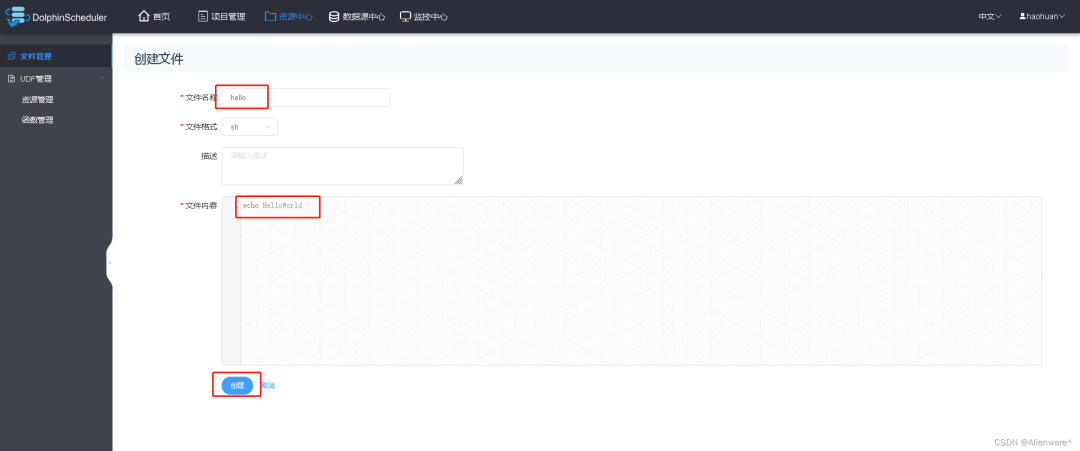
2)创建文件
![file]()
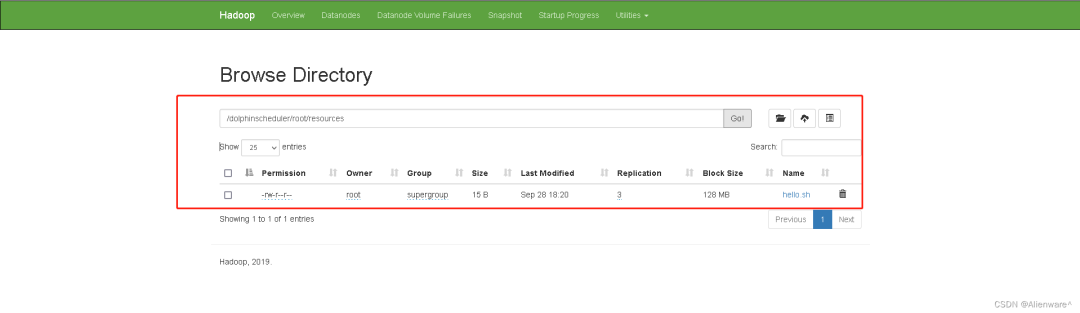
3)确保HDFS可以查询到 hello.sh 脚本
![file]()
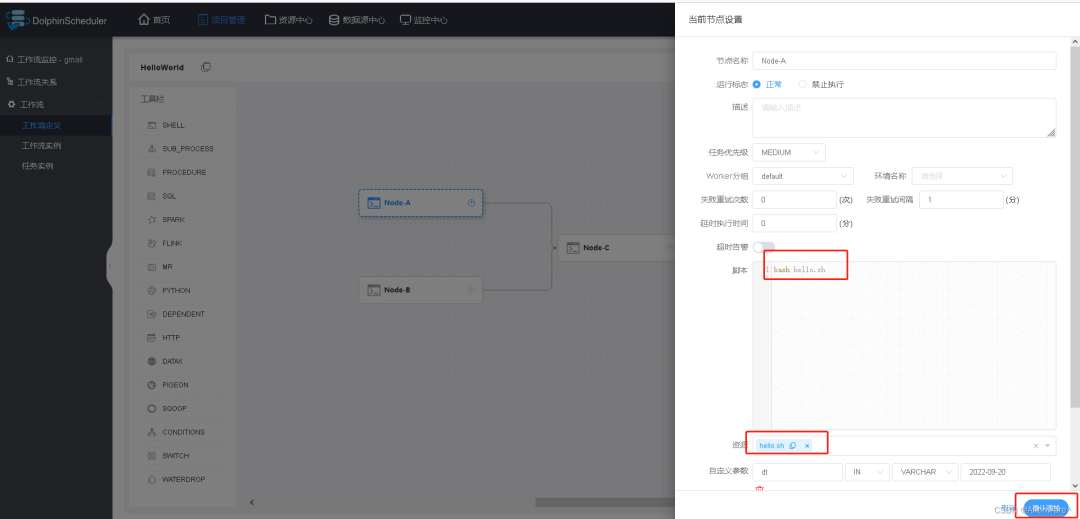
4)编辑Node-A中的内容,保存并执行
![file]()
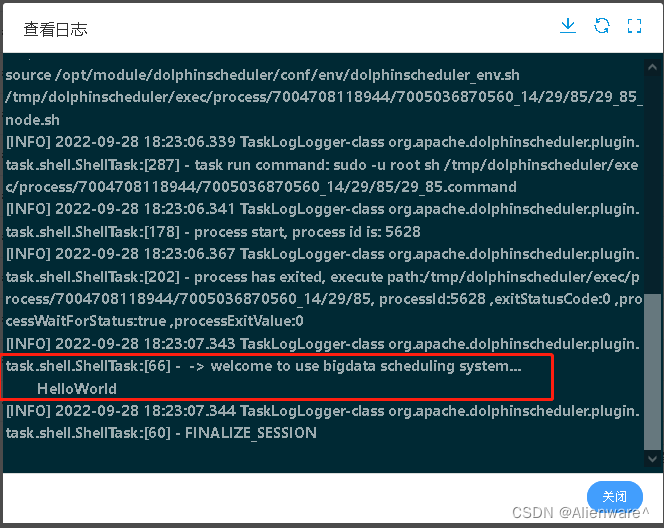
5)查看任务实例中Node-A结果
![file]()
Apache DolphinScheduler 作为一个高效的任务调度和管理平台,通过其强大的内置参数和资源中心,为用户提供了灵活的时间调度和资源管理功能。通过掌握这些功能,用户可以更加高效地管理和执行各种计算任务,从而提高整体的工作效率和准确性。
本文由 白鲸开源科技 提供发布支持!