问题背景
1、开发反馈 trs 的 stg 环境开启 zstd 解压缩后,内存有明显持续上涨趋势,最终导致 OOM
![]()
如图,内存频繁申请释放,当时分析导致 OOM 的原因是因为 stg 的 CPU 不够,导致 GC 不及时,调整 CPU 资源后确实 OOM 没有了。并未怀疑程序本身的性能问题
2、infra 同学发现 adx 的服务存在 zstd 压缩导致 CPU 资源消耗异常的问题,发现是压缩对象的 init 操作非常重导致。
问题分析
结合上面两次问题,想到 Redis 压缩降本时提交的 go 的 zstd 代码有很大优化空间的。可将 zstd.NewWriter 、zstd.NewReader 等重对象使用 sync.Pool 缓存起来,每次使用时从池中取,用完在放回去,避免频繁 New 对象造成内存申请多从而造成 GC 压力大,CPU 资源消耗高的问题。
预期关键结果(收益)
总的来说应该可以提高性能,降低资源消耗,可降本增效。
解决
原来的 zstd 压缩代码
// Deprecated
// 该方法已废弃,请使用 CompressWithZstd 代替
func CompressWithZstdOld(data []byte) ([]byte, error) {
if len(data) == 0 {
return data, errors.New("data is empty")
}
var compressedData bytes.Buffer
enc, err := zstd.NewWriter(&compressedData)
if err != nil {
return nil, err
}
_, err = enc.Write(data)
if err != nil {
err := enc.Close()
if err != nil {
return nil, err
}
return nil, err
}
err = enc.Close()
if err != nil {
return nil, err
}
return compressedData.Bytes(), nil
}
优化后的 zstd 压缩代码
var encoderPool = sync.Pool{
New: func() interface{} {
enc, err := zstd.NewWriter(nil)
if err != nil {
log.Fatalf("Failed to create new Zstd Encoder: %v", err)
}
return enc
},
}
// CompressWithZstd zstd 压缩,空字符串返回空字符串
func CompressWithZstd(data []byte) ([]byte, error) {
if len(data) == 0 {
return data, errors.New("data is empty")
}
enc := encoderPool.Get().(*zstd.Encoder)
defer encoderPool.Put(enc)
var compressedData bytes.Buffer
enc.Reset(&compressedData)
_, err := enc.Write(data)
if err != nil {
err := enc.Close()
return nil, err
}
return compressedData.Bytes(), nil
}
原来的 zstd 解压缩代码
// Deprecated
// 该方法已废弃,请使用 DeCompressWithZstd 代替
func DeCompressWithZstdOld(compressedData []byte) ([]byte, error) {
if len(compressedData) == 0 {
return compressedData, errors.New("compressedData is empty")
}
var decompressedData bytes.Buffer
dec, err := zstd.NewReader(bytes.NewReader(compressedData))
if err != nil {
return nil, err
}
_, err = io.Copy(&decompressedData, dec)
if err != nil {
dec.Close()
return nil, err
}
return decompressedData.Bytes(), nil
}
优化后的 zstd 解压缩代码
var decoderPool = sync.Pool{
New: func() interface{} {
dec, err := zstd.NewReader(nil)
if err != nil {
log.Fatalf("Failed to create new Zstd Decoder: %v", err)
}
return dec
},
}
// DeCompressWithZstd zstd 解压,空字符串返回空字符串
func DeCompressWithZstd(compressedData []byte) ([]byte, error) {
if len(compressedData) == 0 {
return compressedData, errors.New("compressedData is empty")
}
dec := decoderPool.Get().(*zstd.Decoder)
defer decoderPool.Put(dec)
var decompressedData bytes.Buffer
dec.Reset(bytes.NewReader(compressedData))
_, err := io.Copy(&decompressedData, dec)
if err != nil {
return nil, err
}
return decompressedData.Bytes(), nil
}
benchmark
测试在本地开发机进行,测试字符串保持一致
goos: darwin
goarch: amd64
pkg: git.gametaptap.com/tapad/go-utils/utils
cpu: Intel(R) Core(TM) i9-9880H CPU @ 2.30GHz
BenchmarkCompressWithNewGzip-16 25621 45620 ns/op 4145 B/op 6 allocs/op
BenchmarkCompressWithNewGzipOld-16 6871 186002 ns/op 817830 B/op 23 allocs/op
BenchmarkCompressWithZstd-16 231540 5177 ns/op 3456 B/op 2 allocs/op
BenchmarkCompressWithZstdOld-16 530 1994072 ns/op 23740092 B/op 60 allocs/op
BenchmarkDeCompressWithZstd-16 2183894 538.2 ns/op 1418 B/op 1 allocs/op
BenchmarkDeCompressWithZstdOld-16 76734 15489 ns/op 11662 B/op 36 allocs/op
PASS
性能测试结果解析:从两个维度解析,RT 性能和内存分配都有非常大的提升
-
zstd 压缩:RT 优化前一次压缩需要 1994072 ns, 优化后只需要 5177 ns 。内存更甚,优化前一次压缩需要分配 60次内存,优化后只需要 2次(实际多协程下不只一次)
-
zstd 解压缩:RT 优化前一次解压缩需要 15489 ns, 优化后只需要 538.2 ns 。 内存优化前一次解压缩需要分配 36次内存,优化后也只需要分配1次。(实际多协程下不止一次)
从结果看应该是一次性价比很高的优化。
关键结果回收
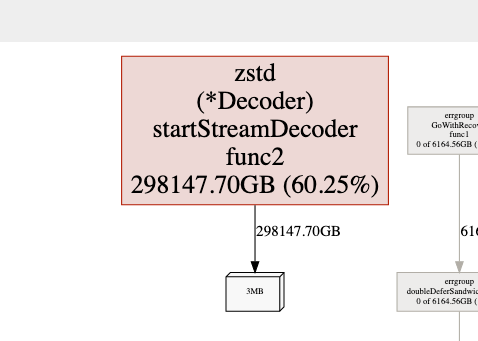
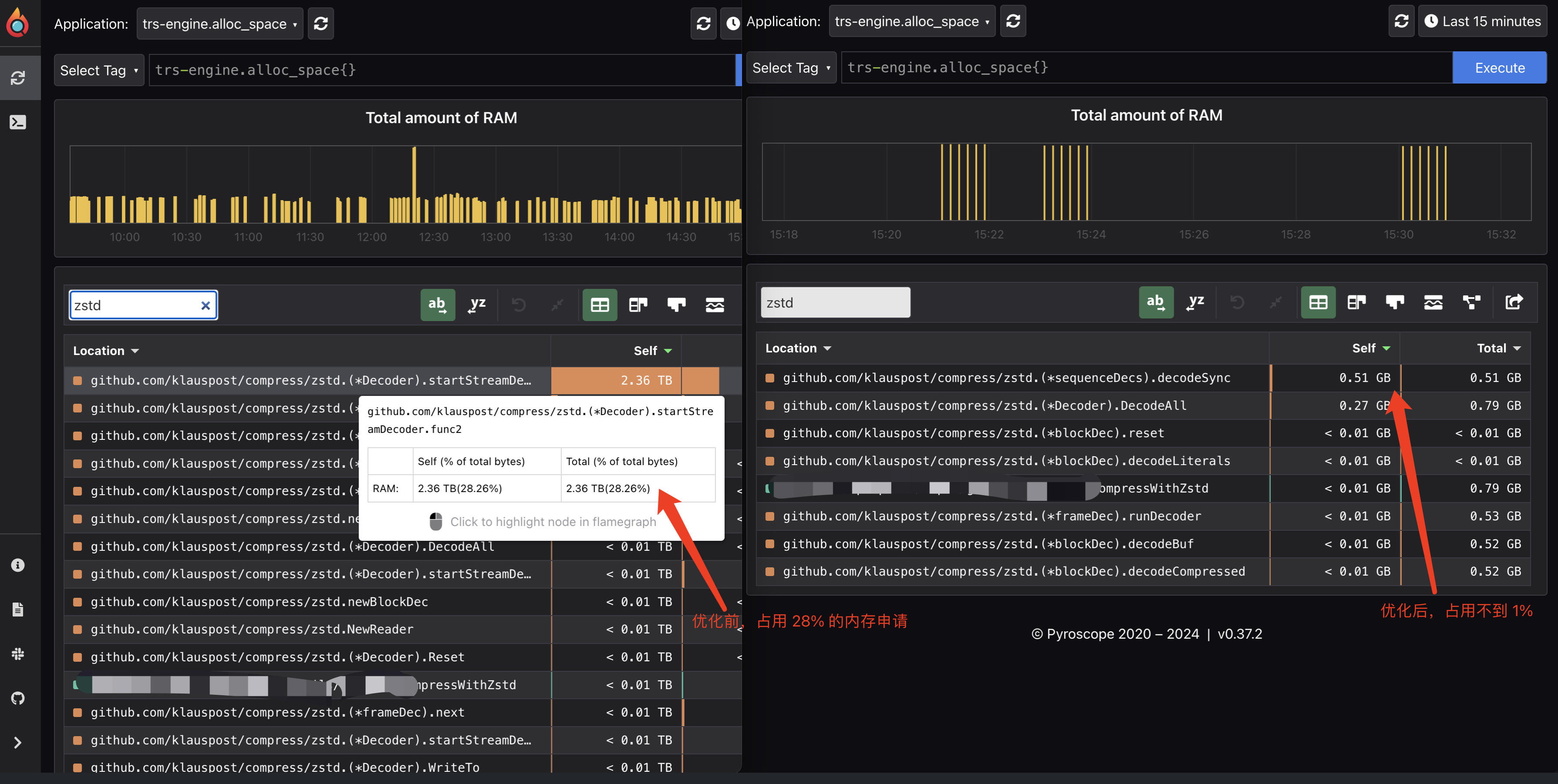
内存申请数据
- 优化前 zstd 的内存申请量占到了整个应用的 28%,优化后占用 1% 都不到
![]()
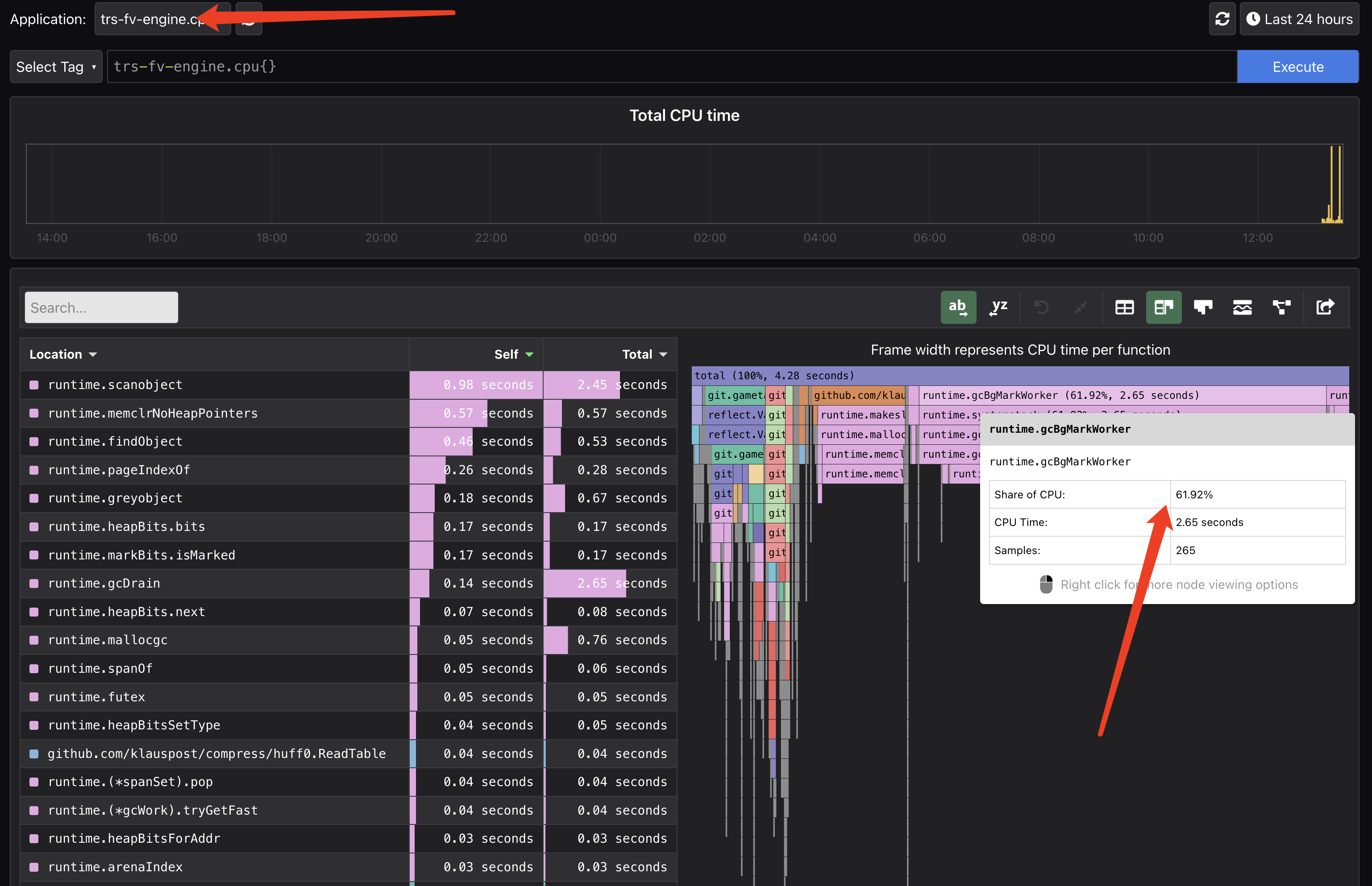
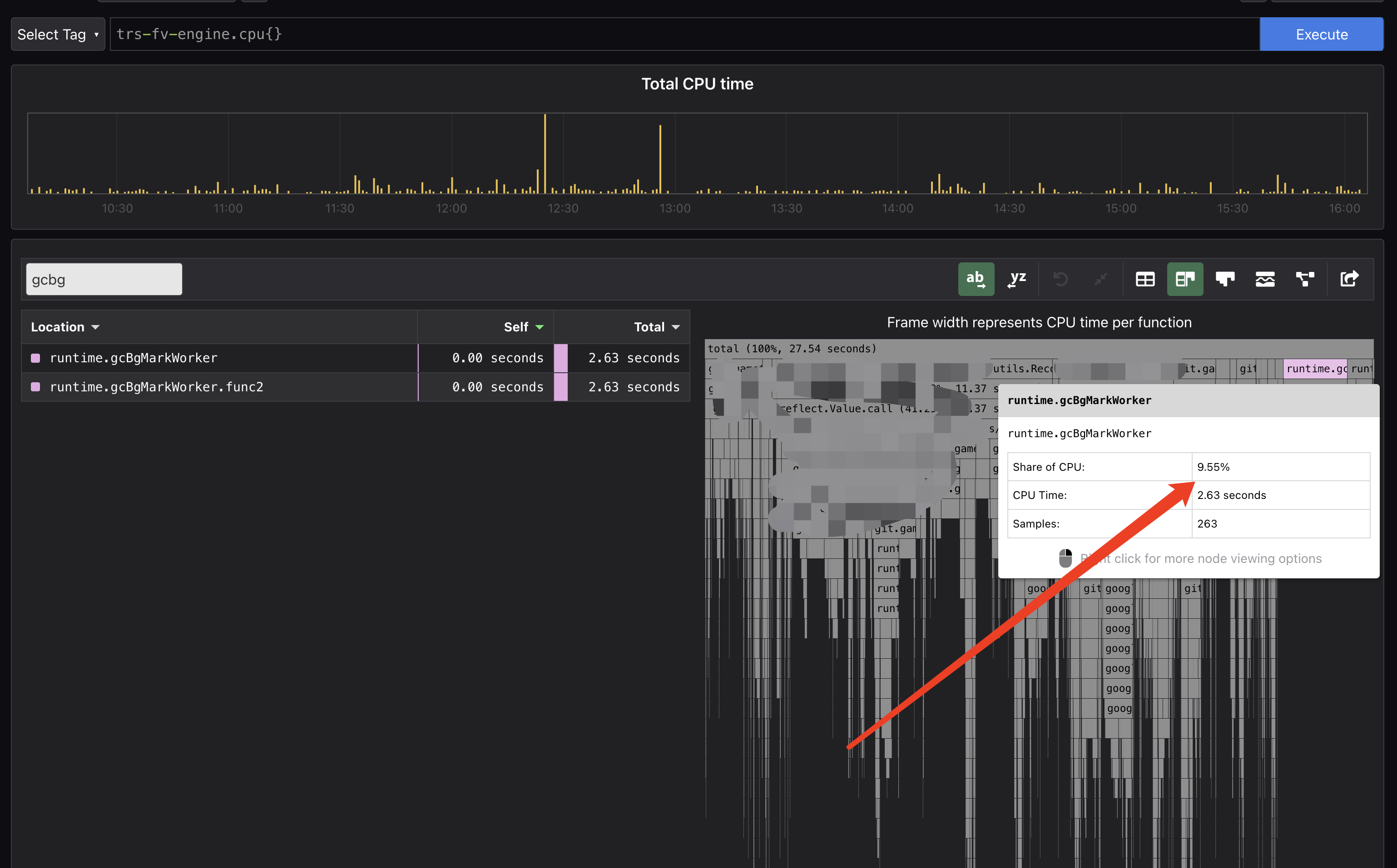
GC 数据
- 优化前,因为频繁申请内存,GC 压力很大,GC 占用了 CPU 的 61.92%的时间。
![]()
- 优化后,GC 占用了 CPU 的时间不到 10%。
![]()
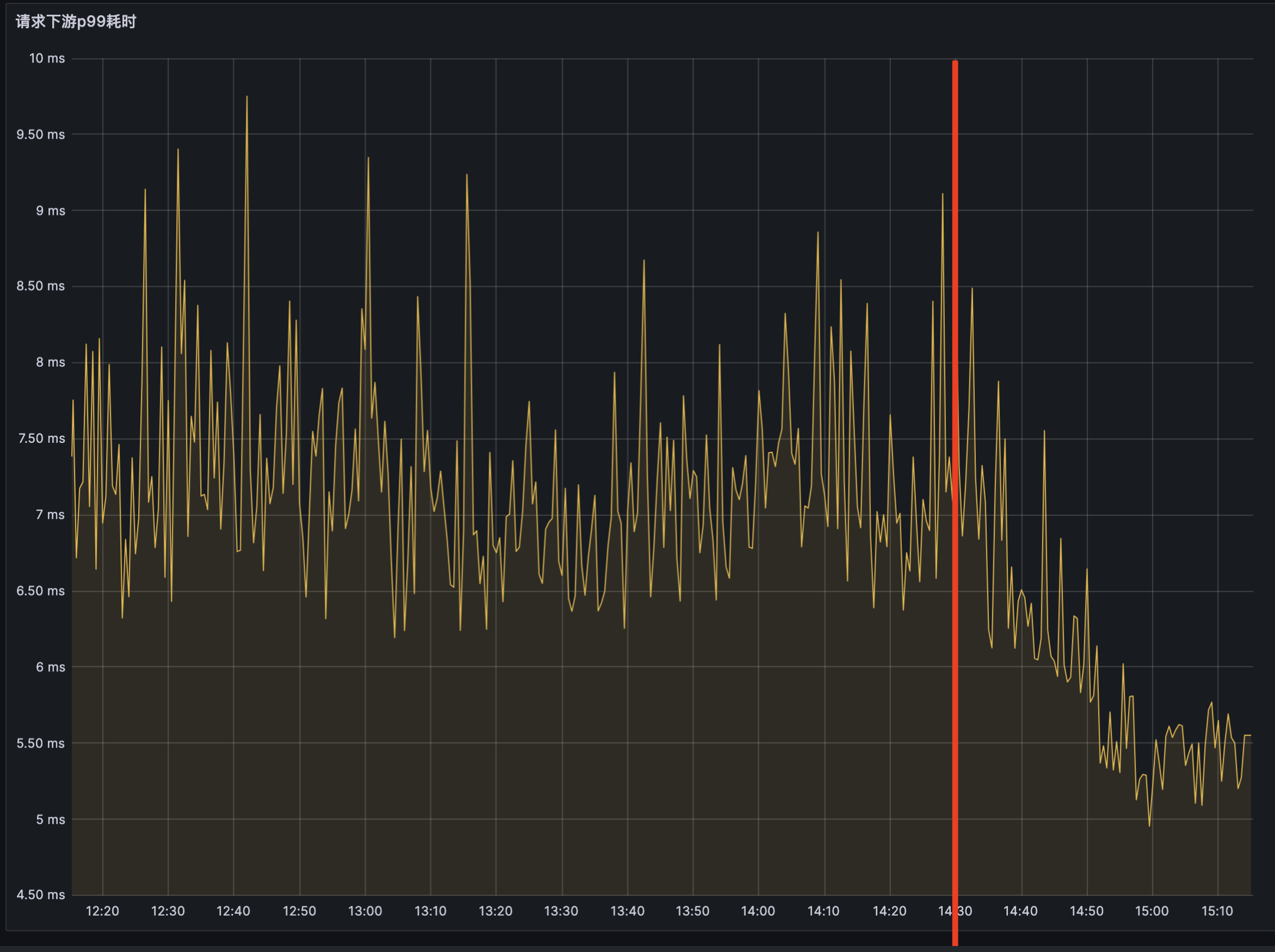
接口 RT 数据
优化后 RT 减少 1~3ms ,且 RT 非常稳定,消除了毛刺现象(可能是GC 压力大影响的)
![]()
CPU 资源数据
不完全统计,多个服务优化后,总计释放了 542C CPU 的资源。