向量数据库的劲敌来了?又有一批赛道创业公司要倒下?
……
这是 OpenAI 上线 Assistant 检索功能后,技术圈传出的部分声音。原因在于,此功能可以为用户提供基于知识库问答的 RAG(检索增强生成) 能力。而此前,大家更倾向于将向量数据库作为 RAG 方案的重要组件,以达到减少大模型出现“幻觉”的效果。
那么,问题来了,OpenAI 自带的 Assistant 检索功能 V.S. 基于向量数据库构建的开源 RAG 方案相比,谁更胜一筹?
本着严谨的求证精神,我们对这个问题进行了定量测评,结果很有意思:
OpenAI 表现不错!不过,在基于向量数据库的开源 RAG 方案面前仍有差距!
接下来,我将还原整个测评过程。需要强调的是,要完成这些测评并不容易,少量的测试样本根本无法有效衡量 RAG 应用的各方面效果。因此,需要采用一个公平、客观的 RAG 效果测评工具,在一个合适的数据集上进行测评,进行定量的评估和分析,并保证结果的可复现性。
话不多说,上过程!
01.评测工具
Ragas 是一个致力于测评 RAG 应用效果的开源框架。用户只需要提供 RAG 过程中的部分信息,如 question、 contexts、 answer 等,它就能使用这些信息来定量评估多个指标。通过 pip 安装 Ragas,只需几行代码,即可进行评估,过程如下:
from ragas import evaluate
from datasets import Dataset
# prepare your huggingface dataset in the format
# dataset = Dataset({
# features: ['question', 'contexts', 'answer', 'ground_truths'],
# num_rows: 25
# })
results = evaluate(dataset)
# {'ragas_score': 0.860, 'context_precision': 0.817,
# 'faithfulness': 0.892, 'answer_relevancy': 0.874}
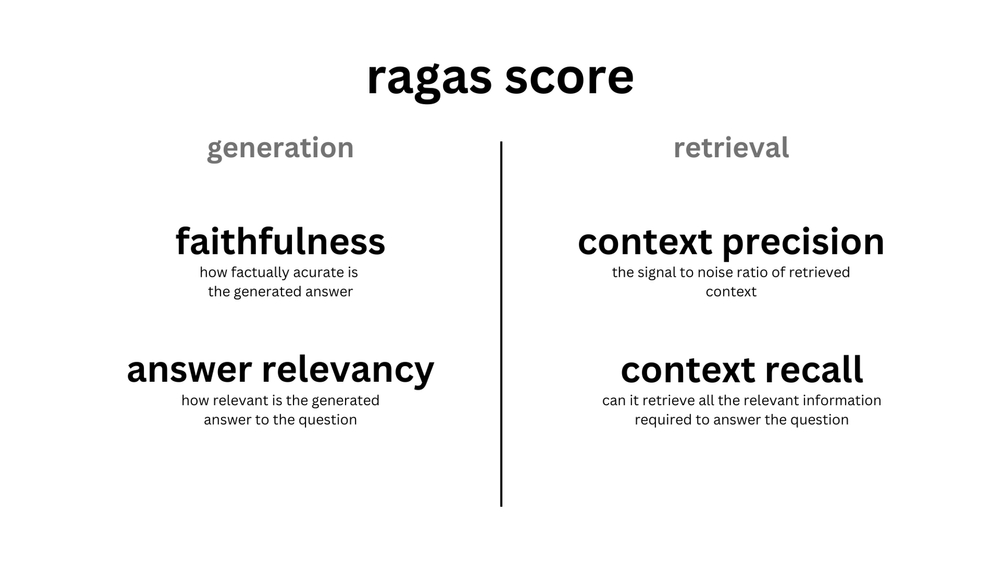
Ragas 有许多评测的得分指标子类别,比如:
-
从 generation 角度出发,有描述回答可信度的 Faithfulness,回答和问题相关度的 Answer relevancy
-
从 retrieval 角度出发,有衡量知识召回精度的 Context precision,知识召回率的 Context recall,召回内容相关性的 Context Relevancy
-
从 answer 与 ground truth 比较角度出发,有描述回答相关性的 Answer semantic similarity,回答正确性的 Answer Correctness
-
从 answer 本身出发,有各种 Aspect Critique
![]()
这些指标各自衡量的角度不同,举个例子,比如指标 answer correctness,它是结果导向,直接衡量 RAG 应用回答的正确性。下面是一个 answer correctness 高分与低分的对比例子:
Ground truth: Einstein was born in 1879 at Germany .
High answer correctness: In 1879, in Germany, Einstein was born.
Low answer correctness: In Spain, Einstein was born in 1879.
其它指标细节可参考官方文档。重要的是,每个指标衡量角度不同,这样用户就可以全方位,多角度地评估 RAG 应用的好坏。
02.测评数据集
我们使用 Financial Opinion Mining and Question Answering (fiqa) Dataset 作为测试数据集。主要有以下几方面的原因:
该数据集是属于金融专业领域的数据集,它的语料来源非常多样化,并包含了人工回答内容。里面涵盖非常冷门的金融专业知识,大概率不会出现在 ChatGPT 的训练数据集。这样就比较适合用来当作外挂的知识库,以和没见过这些知识的 LLM 形成对比。
该数据集原本就是用来评估 Information Retrieval (IR) 能力的,因此它有标注好了的知识片段,这些片段可以直接当做召回的标准答案(ground truth)。
Ragas 官方也把它视作一个标准的入门测试数据集,并提供了构建它的脚本 (https://github.com/explodinggradients/ragas/blob/main/experiments/baselines/fiqa/dataset-exploration-and-baseline.ipynb)。因此有一定的社区基础,可以得到一致的认可,也比较合适用来做 baseline。
我们先使用转换脚本来将最原始的 fiqa 数据集转换构建成 Ragas 方便处理的格式。可以先看一眼该评测数据集的内容,它有 647 个金融相关的 query 问题,每个问题对应的知识原文内容列表就是 ground_truths,它一般包含 1 到 4 条知识内容片段。
![]()
进行到这一步,测试数据就准备好了。我们只需要将 question 这一列,拿去提问 RAG 应用,然后将 RAG 应用的回答和召回,合并上 ground truths,将所有这些信息,用 Ragas 评测打分。
03.RAG 对照设置
接下来就是搭建我们要对比的两个 RAG 应用,来对比跑分。下面开始搭建两套 RAG 应用:OpenAI assistant 和基于向量数据库自定义的 RAG pipeline。
OpenAI assistant
我们采用 OpenAI 官方的 assistant retrieval 方式介绍,构建 assistant 和上传知识,并且使用 OpenAI 官方给出的方式拿到 answer 和召回的 contexts,其它都采用默认设置。
基于向量数据库的 RAG pipeline
紧接着我们打造一条基于向量召回的 RAG pipeline,用 Milvus 向量数据库存储知识,用 HuggingFaceEmbeddings 中的 BAAI/bge-base-en 模型构建 embedding,用 LangChain 的组件进行文档导入和 Agent 构建。
下面列出了两套方案的对比:
![]()
这里注意到,我们用的 LLM model 都是 gpt-4-1106-preview,其它的策略由于 OpenAI 是闭源的,所以应该和它有许多差别。篇幅所限具体实现细节在此不作展开,可以参考我们的实现代码。
04 结果和分析
实验结果
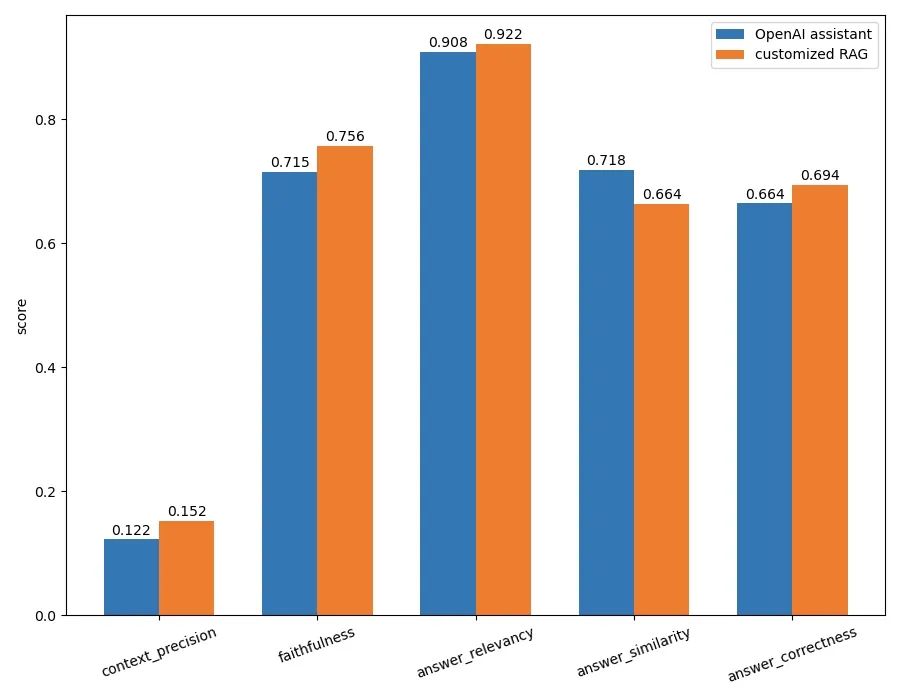
我们使用 Ragas 里的多个指标对它们进行打分,得到下面每个指标的对比结果:
![]()
可以看到,在我们统计的 5 项指标中,OpenAI assistant 除了在 answer_similarity 这项超过自定义的 RAG pipeline 之外,其它指标都略低于自定义的 RAG pipeline。
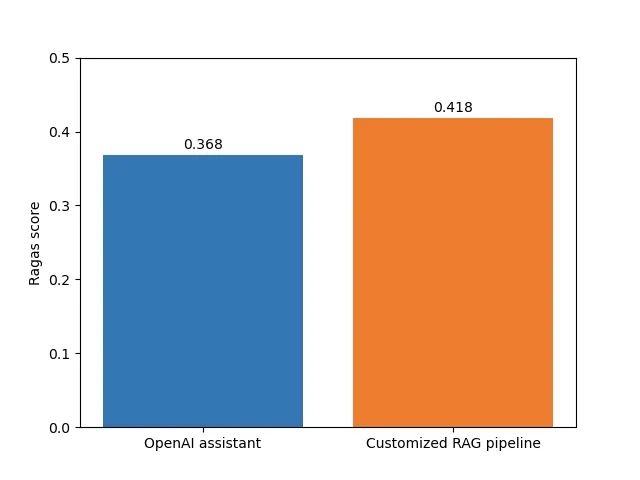
另外,Ragas 也可以通过计算各项指标的调和平均数,来得到一个总体平均的得分,叫作 Ragas score。调和平均数的作用在于惩罚低分项。从总体上看,OpenAI assistant 的 Ragas score 也是低于自定义的 RAG pipeline。
![]()
那么,为什么会有这样的结果呢?通过大量的单条结果对比,我们发现,基于向量数据库搭建的 RAG pipeline 与OpenAI assistant 相比,有如下优势:
- OpenAI assistant 更倾向于用自己的知识回答,而少用召回的知识。
这可能是由于其内部的 Agent 设定导致,当遇到 GPT 可能知道的事实时,它更自信,选择使用自己训练时的知识,而不去使用召回的知识,但也许这时的知识就是正好和它训练的相悖。举个例子:
提问:
Are personal finance / money management classes taught in high school, anywhere?
OpenAI assistant 回答:
![]()
这个回答对不对呢?只从回答来看是没什么问题,但我们注意到标亮的地方,强调的是其没有联网获取最新知识,这就说明它没有用到上传上去的知识文档内容。
再看看 ground truth,也就是数据集里标注的正确答案:
![]()
可以看到,文档里举例了许多回答这个问题的具体场景,而 OpenAI 的回答确实没有用到它们。它认为这个问题过于简单,足以直接回答,而忽略了知识库里可能需要的信息。
接下来我们看看基于向量数据库的 RAG 的回答:
![]()
高亮出了 RAG 回答中引用 ground truth 的内容,它很好地把知识内容融入到回答中去,这才是用户需要的。
- OpenAI 对知识的切分和召回有待优化,开源自定义方案更胜一筹。
我们可以通过查看 assistant 的中间召回的知识,来分析它对知识文档的切分策略,或者反推其 embedding 模型的效果。举个例子:
提问:
Pros / cons of being more involved with IRA investments [duplicate]
OpenAI assistant 的中间召回片段:
['PROS: CONS']
这显然是一个错误的召回片段,而且它只召回了这一条片段。首先片段的切分不太合理,把后面的内容切掉了。其次 embedding 模型并没有把更重要的、可以回答这个问题的片段召回,只是召回了提问词相似的片段。
自定义 RAG pipeline 的召回片段:
![]()
可以看到,自行搭建的 RAG pipeline 把许多 IRA 投资的信息片段都召回出来了,这些内容也是有效地结合到最后 LLM 的回答中去。
此外,可以注意到,向量召回也有类似 BM25 这种分词召回的效果,召回的关键词确实都是需要的词“IRA”,因此向量召回不仅在整体语义上有效,在微观词汇上召回效果也不逊色于词频召回。
其它方面
除实验效果分析之外,对比更加灵活的自定义开源 RAG 方案,OpenAI assistant 还有一些较为明显的劣势:
-
OpenAI assistant 无法调整 RAG 流程中的参数,内部是个黑盒,这也导致了没法对其优化。而自定义 RAG 方案可以调整 top_k、chunk size、embedding 模型等组件或参数,这样也可以在特定数据上进行优化。
-
OpenAI 存储文件量有限,而向量数据库可以存储海量知识。OpenAI 单文件上传有上限 512 MB 并不能超过 2,000,000 个 token。
因此,OpenAI 无法完成业务更复杂,数据量更大或更加定制化的 RAG 服务。
05 总结
我们基于 Ragas 测评工具,将 OpenAI assistant 和基于向量数据库的开源 RAG 方案做了详尽的比较和分析。可以发现,虽然 OpenAI assistant 的确在检索方面表现尚佳,但在回答效果,召回表现等方面却逊色于向量 RAG 检索方案,Ragas 的各项指标也定量地反应出该结论。
因此,对于构建更加强大、效果更好的 RAG 应用,开发者可以考虑基于 Milvus 或 Zilliz Cloud 等向量数据库,构建定义检索功能,从而带来更好的效果和灵活的选择。