前言
日常Bug排查系列都是一些简单Bug排查。笔者将在这里介绍一些排查Bug的简单技巧,同时顺便积累素材
Bug现场
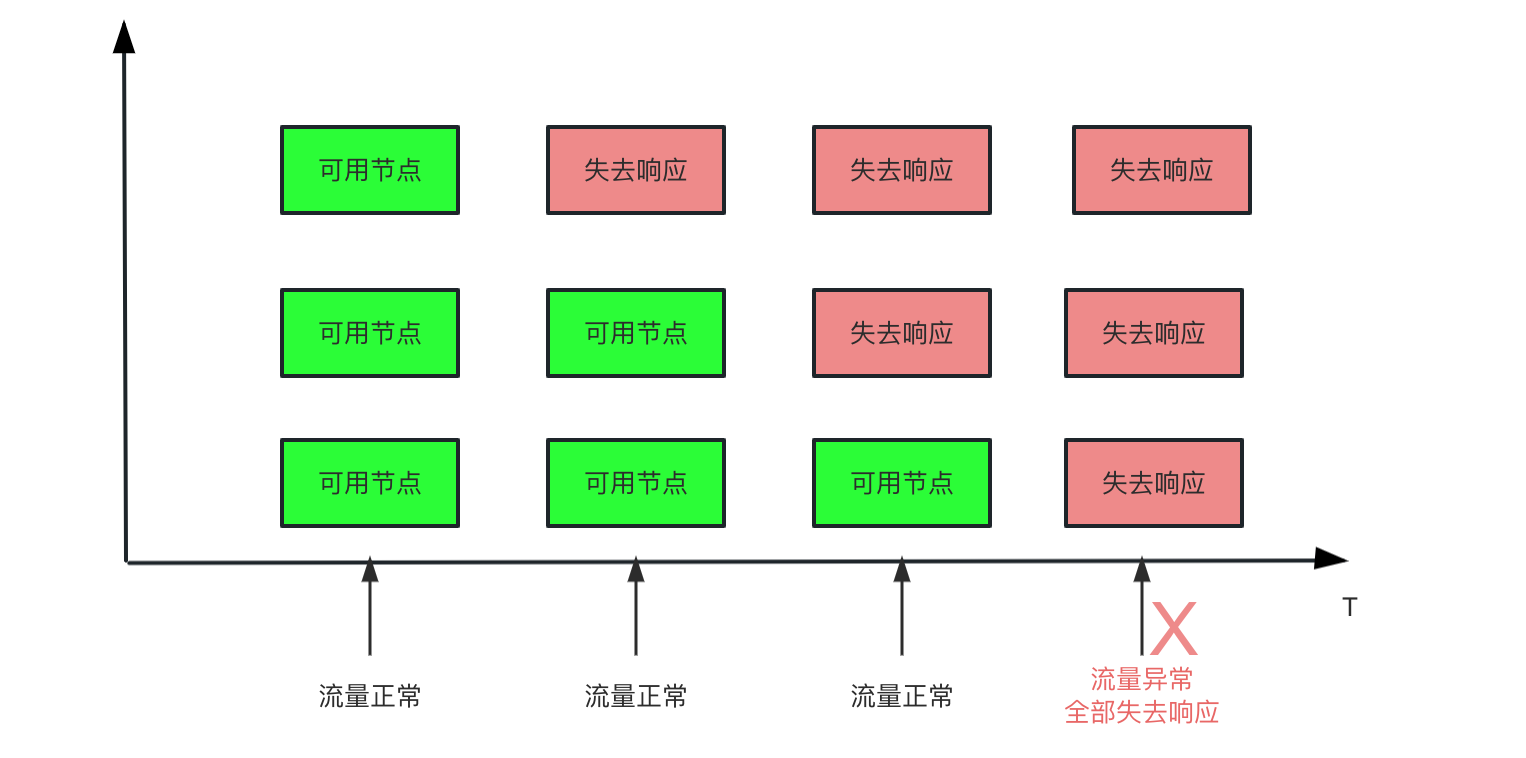
最近碰到一个产线问题,表现为某个应用集群所有的节点全部下线了。导致上游调用全部报错。而且从时间线分析来看。这个应用的节点是逐步失去响应的。因为请求量较小,直到最后一台也失去响应后,才发现这个集群有问题。 ![]()
线程逐步耗尽
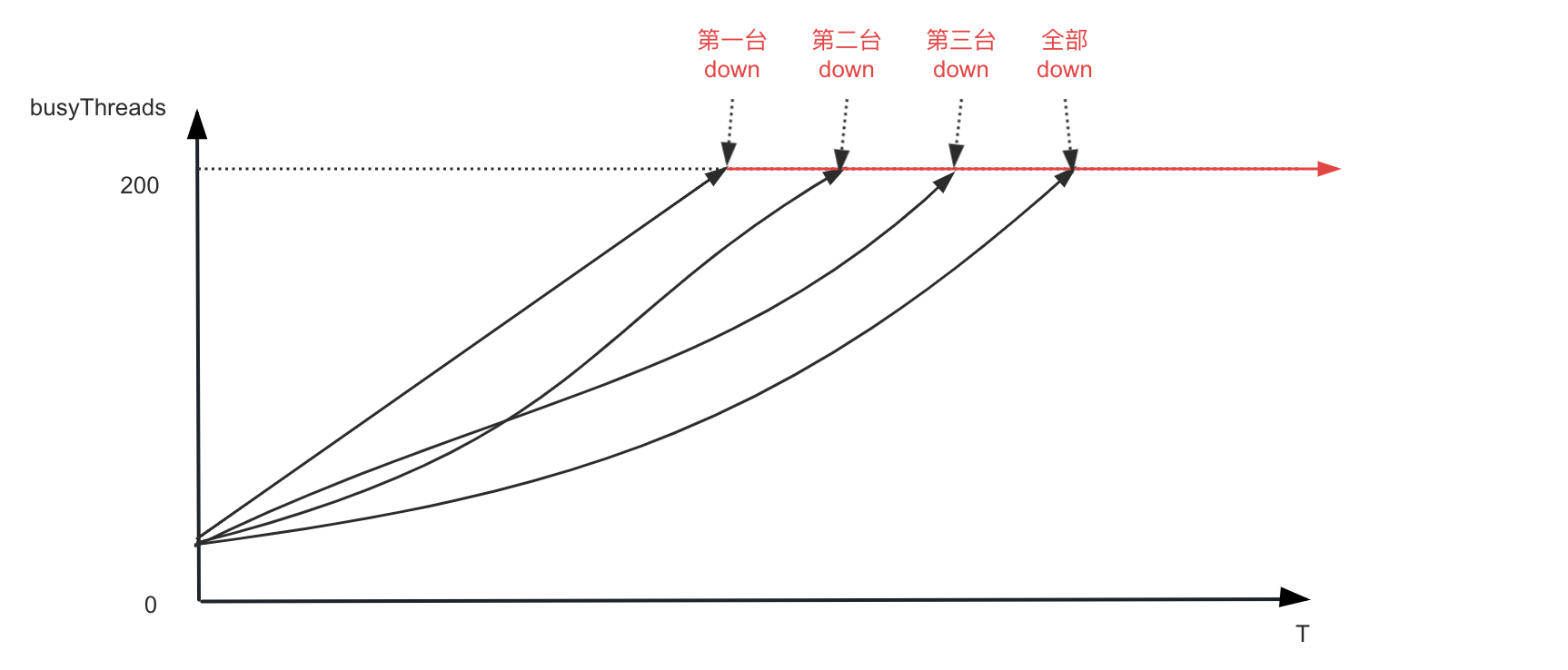
笔者观察了下监控,发现每台机器的BusyThread从上次发布开始就逐步增长,一直到BusyThread线程数达到200才停止,而这个时间和每台机器从注册中心中摘除的时间相同。看了下代码,其配置的最大处理请求线程数就是200。 ![]()
查看线程栈
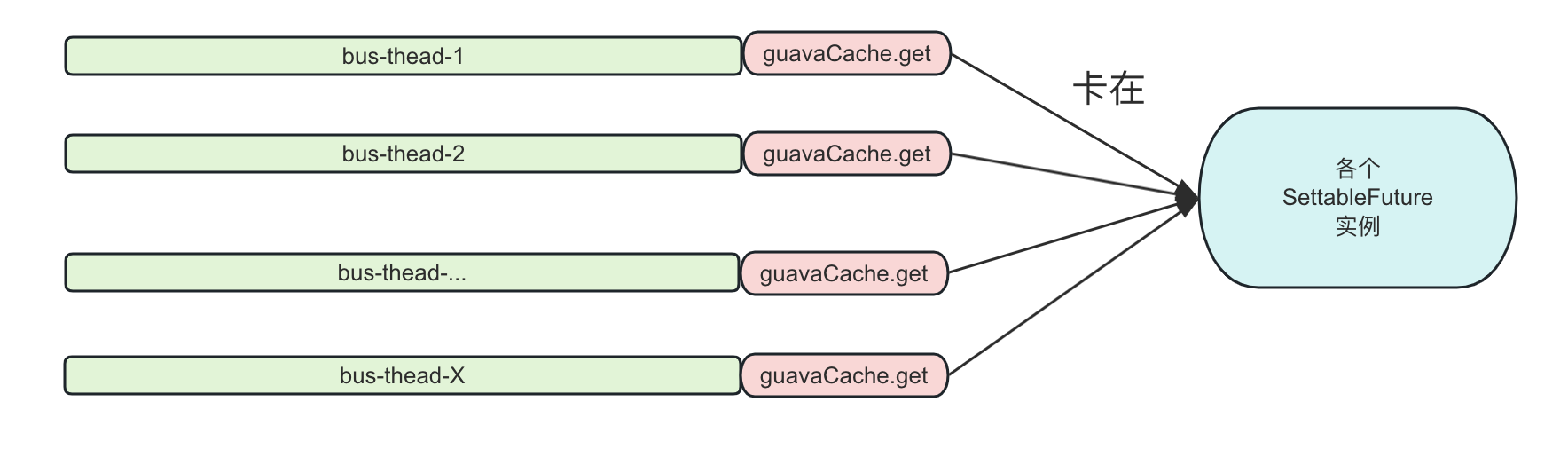
很容易的,我们就想到去观察相关机器的线程栈。发现其所有的的请求处理线程全部Block在com.google.common.util.concurrent.SettableFuture的不同实例上。卡住的堆栈如下所示:
at sun.misc.Unsafe.park (Native Method: )
at java.util.concurrent.locks.LockSupport.park (LockSupport.java: 175)
at com.google.common.util.concurrent.AbstractFuture.get (AbstractFuture.java: 469)
at com.google.common.util.concurrent.AbstractFuture$TrustedFuture.get (AbstractFuture.java: 76)
at com.google.common.util.concurrent.Uninterruptibles.getUninterruptibly (Uninterruptibles.java: 142)
at com.google.common.cache.LocalCache$LoadingValueReference.waitForValue (LocalCache.java: 3661)
at com.google.common.cache.LocalCache$Segment.waitForLoadingValue (LocalCache.java: 2315)
at com.google.common.cache.LocalCache$Segment.get (LocalCache.java: 2202)
at com.google.common.cache.LocalCache.get (LocalCache.java: 4053)
at com.google.common.cache.LocalCache.getOrLoad (LocalCache.java: 4057)
at com.google.common.cache.LocalCache$LocalLoadingCache.get (LocalCache.java: 4986)
at com.google.common.cache.ForwardingLoadingCache.get (ForwardingLoadingCache.java: 45)
at com.google.common.cache.ForwardingLoadingCache.get (ForwardingLoadingCache.java: 45)
at com.google.common.cache.ForwardingLoadingCache.get
......
at com.XXX.business.getCache
......
![]()
从GuavaCache获取缓存为什么会被卡住
GuavaCache是一个非常成熟的组件了,为什么会卡住呢?使用的姿势不对?于是,笔者翻了翻使用GuavaCache的源代码。其简化如下:
private void initCache() {
ExecutorService executor = new ThreadPoolExecutor(1, 1,
60, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(50), // 注意这个QueueSize
new NamedThreadFactory(String.format("cache-reload-%s")),
(r, e) -> {
log.warn("cache reload rejected by threadpool!"); // 注意这个reject策略
});
this.executorService = MoreExecutors.listeningDecorator(executor);
cache = CacheBuilder.newBuilder().maximumSize(100) // 注意这个最大值
.refreshAfterWrite(1, TimeUnit.DAYS).build(new CacheLoader<K, V>() {
@Override
public V load(K key) throws Exception {
return innerLoad(key);
}
@Override
public ListenableFuture<V> reload(K key, V oldValue) throws Exception {
ListenableFuture<V> task = executorService.submit(() -> {
try {
return innerLoad(key);
} catch (Exception e) {
LogUtils.printErrorLog(e, String.format("重新加载缓存失败,key:%s", key));
return oldValue;
}
});
return task;
}
});
}
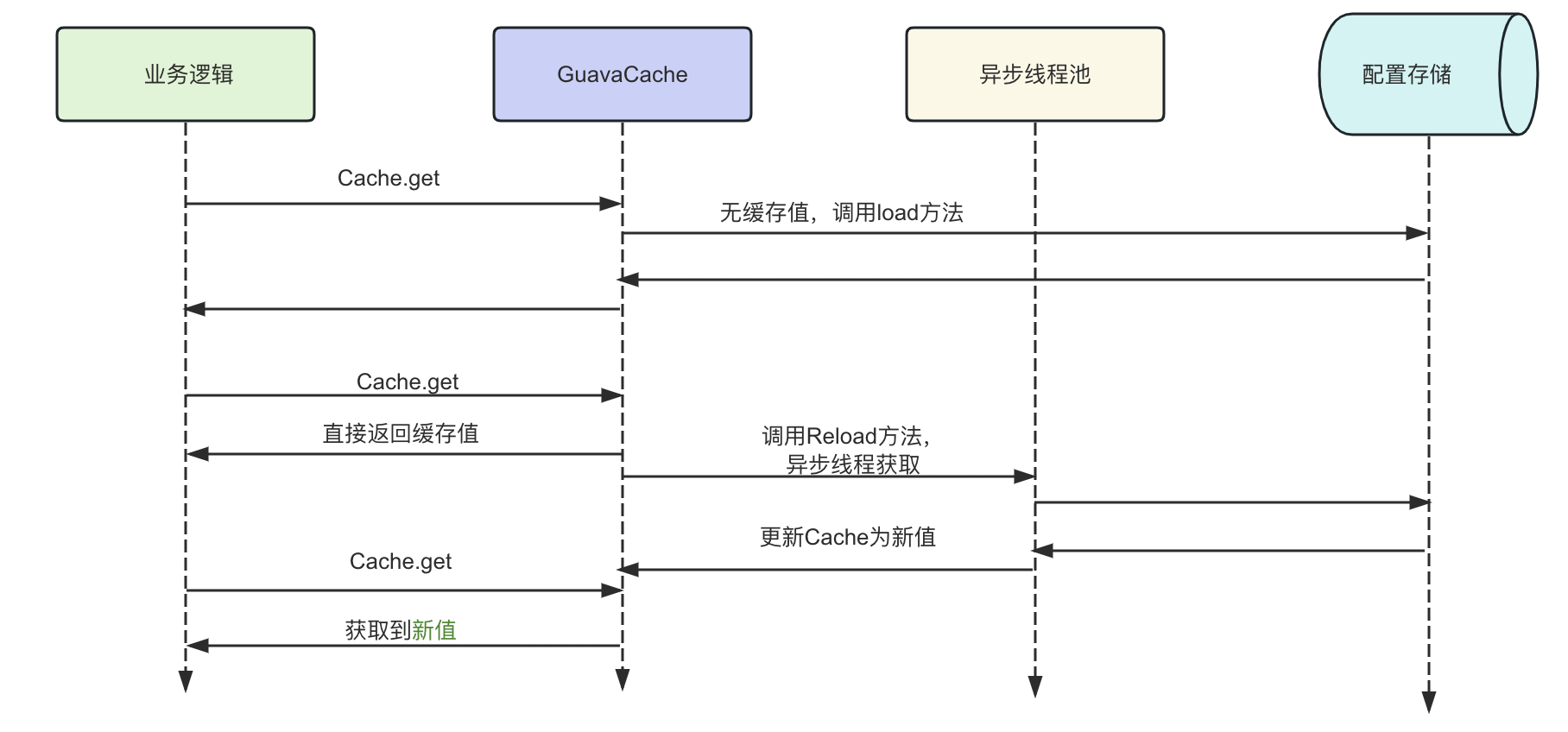
这段代码事实上写的还是不错的,其通过重载reload方法并在加载后段缓存出问题的时候使用old Value。保证了即使获取缓存的后段存储出问题了,依旧不会影响到我们缓存的获取。逻辑如下所示:
![]()
那么为什么会卡住呢?一时间看不出什么问题。那么我们就可以从系统的日志中去寻找蛛丝马迹。
日志
对应时间点日志空空如也
对于这种逐渐失去响应的,我们寻找日志的时候一般去寻找源头。也就是第一次出现卡在SettableFuture的时候发生了什么。由于我们做了定时的线程栈采集,那么很容易的,笔者挑了一台机器找到了3天之前第一次发生线程卡住的时候,grep下对应的线程名,只发现了一个请求过来到了这个线程然后卡住了,后面就什么日志都不输出了。
异步缓存的日志
继续回顾上面的代码,代码中缓存的刷新是异步执行的,很有可能是异步执行的时候出错了。再grep异步执行的相关关键词“重新加载缓存失败”,依旧什么都没有。线索又断了。
继续往前追溯
当所有线索都断了的情况下,我们可以翻看时间点前后的整体日志,看下有没有异常的点以获取灵感。往前多翻了一天的日志,然后一条线程池请求被拒绝的日志进入了笔者的视野。
cache reload rejected by threadpool!
看到这条日志的一瞬间,笔者立马就想明白了。GuavaCache的reload请求不是出错了,而是被线程池给丢了。在reload请求完成之后,GuavaCache会对相应的SettableFuture做done的动作以唤醒等待的线程。而由于我们的Reject策略只打印了日志,并没有做done的动作,导致我们请求Cache的线程一直在卡waitForValue上面。如下图所示,左边的是正常情况,右边的是异常情况。 ![]()
为什么会触发线程池拒绝策略
注意我们初始化线程池的源代码
ExecutorService executor = new ThreadPoolExecutor(1, 1,
60, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(50), // 注意这个QueueSize
new NamedThreadFactory(String.format("cache-reload-%s")),
(r, e) -> {
log.warn("cache reload rejected by threadpool!"); // 注意这个reject策略
});
这个线程池是个单线程线程池,而且Queue只有50,一旦遇到同时过来的请求大于50个,就很容易触发拒绝策略。
源码分析
好了,这时候我们就可以上一下GuavaCache的源代码了。
V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
checkNotNull(key);
checkNotNull(loader);
try {
if (count != 0) { // read-volatile
// don't call getLiveEntry, which would ignore loading values
ReferenceEntry<K, V> e = getEntry(key, hash);
if (e != null) {
long now = map.ticker.read();
V value = getLiveValue(e, now);
if (value != null) {
recordRead(e, now);
statsCounter.recordHits(1);
// scheduleRefresh中一旦Value不为null,就直接返回旧值
return scheduleRefresh(e, key, hash, value, now, loader);
}
ValueReference<K, V> valueReference = e.getValueReference();
// 如果当前Value还在loading,则等loading完毕
if (valueReference.isLoading()) {
// 这次的Bug就一直卡在loadingValue上
return waitForLoadingValue(e, key, valueReference);
}
}
}
// at this point e is either null or expired;
return lockedGetOrLoad(key, hash, loader);
} catch (ExecutionException ee) {
......
}
为什么没有直接返回oldValue而是卡住
等等,在上面的GuavaCache源代码里面。一旦缓存有值之后,肯定是立马返回了。对应这段代码。
if (value != null) {
recordRead(e, now);
statsCounter.recordHits(1);
// scheduleRefresh中一旦Value不为null,就直接返回旧值
return scheduleRefresh(e, key, hash, value, now, loader);
}
所以就算异步刷新请求被线程池Reject掉了。它也不会讲原来缓存中的值给删掉。业务线程也不应该卡住。那么这个卡住是什么原因呢?为什么缓存中没值没有触发load而是等待valueReference有没有加载完毕呢。
稍加思索之后,笔者就找到了原因,因为上述那段代码中设置了缓存的maxSize。一旦超过maxSize,一部分数据就被驱逐掉了,而如果这部分数据恰好就是线程池Reject掉请求的数据,那么就会进值为空同时需要等待valueReference loading的代码分支,从而造成卡住的现象。让我们看一下源代码:
localCache.put //
|->evictEntries
|->removeEntry
|->removeValueFromChain
ReferenceEntry<K,V> removeValueFromChain(...) {
......
if(valueReference.isLoading()){
// 设置原值为null
valueReference.notifyNewValue(null);
return first;
}else {
removeEntryFromChain(first,entry)
}
}
我们看到,代码中valueReference.isLoading()的判断,一旦当前value还处于加载状态中,那么驱逐的时候只会将对应的entry(key)项设置为null而不会删掉。这样,在下次这个key的缓存被访问的时候自然就走到了value为null的分支,然后就看到当前的valueReference还处于loading状态,最后就会等待那个由于被线程reject而永远不会done的future,最后就会导致这个线程卡住。逻辑如下图所示: ![]()
什么是逐渐失去响应
因为业务的实际缓存key的项目是大于maxSize的。而一开始系统启动后加载的时候缓存的cache并没有达到最大值,所以这时候被线程池reject掉相应的刷新请求依旧能够返回旧值。但一旦出现了大于缓存cache最大Size的数据导致一些项被驱逐后,只要是一个请求去访问这些缓存项都会被卡住。但很明显的,能够被驱逐出去的旧缓存肯定是不常用的缓存(默认LRU缓存策略),那么就看这个不常用的数据的流量到底是在哪台机器上最多,那么哪台机器就是最先失去响应的了。
总结
虽然这是个较简单的问题,排查的时候也是需要一定的思路的,尤其是发生问题的时间点并往前追溯到第一个不同寻常的日志这个点,这个往往是我们破局的手段。GuavaCache虽然是个使用非常广泛的缓存工具,但不合理的配置依旧会导致灾难性的后果。 ![]()