上海人工智能实验室(上海AI实验室)与香港中文大学(深圳)联合团队推出 AI 音频生成平台安菲翁(Amphion)。现已开源并提供免费商用。
其不仅具备语音及歌声合成转换、音效及音乐生成等多种能力,更可实现转换过程可视化,有效地降低了应用门槛,助力更广泛的开发者进行AI音频研发。
Amphion为古希腊神话中的传奇音乐家,传说其弹奏的优美琴声可让顽石感灵。上海AI实验室联合团队借此为AI音频生成平台命名,希望通过AI技术的创新为音频领域注入全新的研究思路,开源开放,“声”生不息。
![]()
集成经典模型架构,实现多项生成任务
为帮助初级开发者入门AI音频生成研究并使研究过程可复现,Amphion将当前多个经典模型架构集中于统一平台,使其可实现多项音频生成任务。
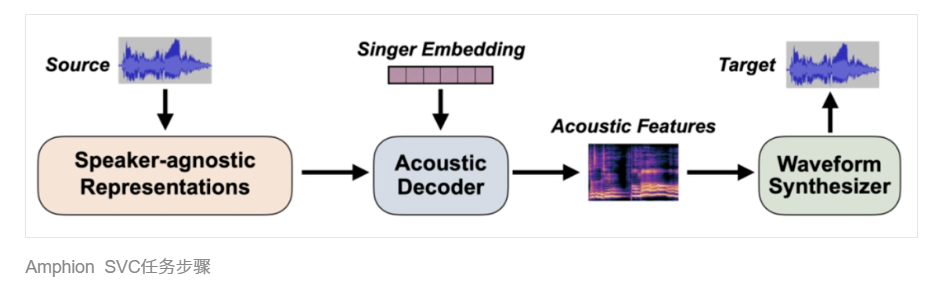
歌声转换 (SVC, Singing Voice Conversion)
歌声转换是指通过 AI 技术,将一位演唱者的音色转变为另一位演唱者。该技术涉及信号处理、机器学习、深度学习等领域。
Amphion系统集成了经典的特征提取模型用于SVC任务,包括经典的扩散模型、VITS模型及OpenAI的Whisper模型等。基于扩散的架构使用双向扩张 CNN作为后端,并支持DDPM、DDIM、PNDM等多种采样算法。此外,Amphion还支持基于一致性模型的单步推理。
目前,Amphion的特征设计已被当前业内流行的音频生成项目So-VITS-SVC 5.0借鉴。
![]()
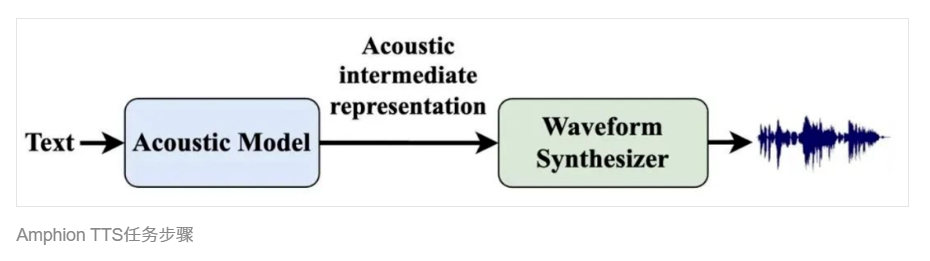
文生语音(TTS, Text To Speech)
文生语音即输入文字转成相应语音的技术。当前,该模块主要采用了深度学习技术,将文本转换成自然流畅的高拟真度语音。在TTS任务模块,Amphion 系统集成了经典 FastSpeech2 模型、VITS 模型以及zero-shot 语音合成技术,即 Vall-E,NaturalSpeech2。
![]()
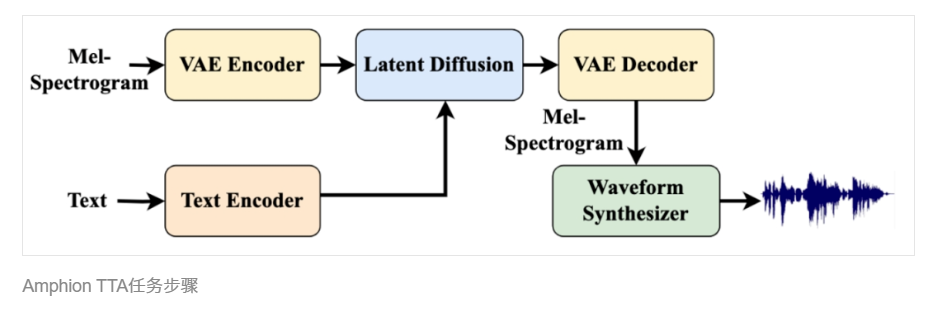
文生音频(TTA, Text To Audio)
文生音频指将文字输入转为音乐、场景音效等特定音频的技术。Amphion 集成了当下主流的文本驱动音频生成模型架构,即基于 VAE Encoder、Decoder 和 Latent Diffusion 的文本驱动的音频生成算法。在该架构下,Latent Diffusion 扩散模型以 T5 编码后的文本为输入,根据文本的指引生成对应的音频效果。
文生音频模型或将对文化创作产生积极深远的影响,从业者或可利用此项技术,根据特定需求生成场景音效,省去从头采集环节,提升生产效率。
![]()
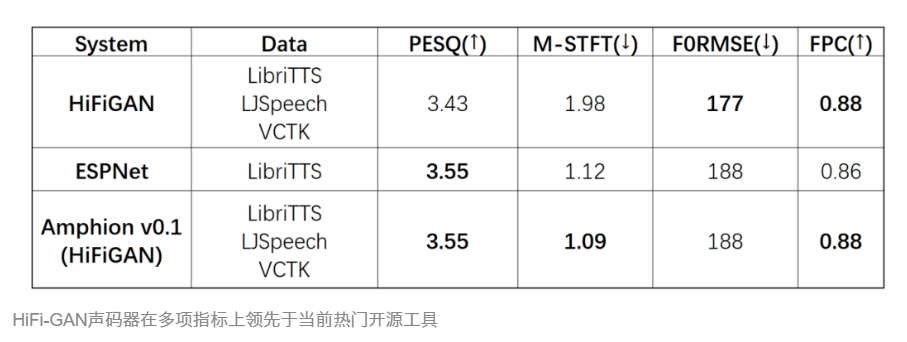
声码器(Vocoder)是产生高质量音频信号的重要模块。为确保所生成音频的高音质输出,Amphion集成了目前广泛使用的神经声码器(Neural Vocoders),包括BigVGAN、HiFi-GAN、DiffWave等主流声码器。
技术报告显示,Amphion中的HiFi-GAN声码器在多项指标上领先于当前热门开源工具。
![]()
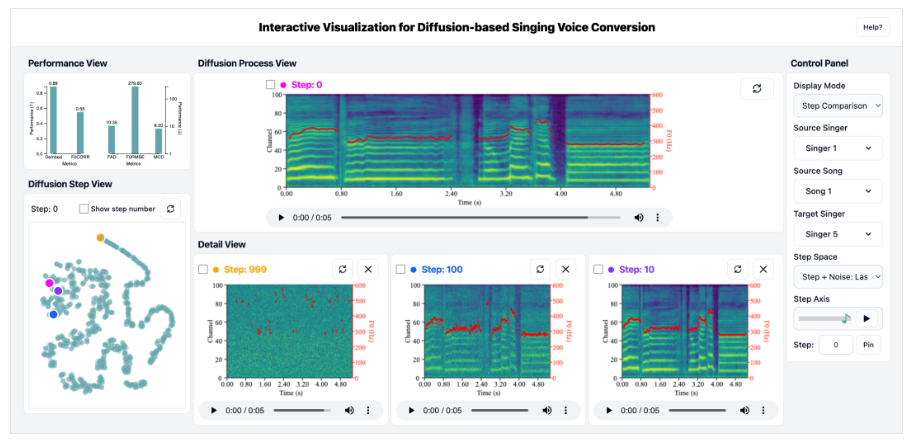
可视化功能
与传统的音频开源工具不同,Amphion提供了生成过程可视化及音频可视化功能。联合团队旨在通过可视化,使初级开发者者更好地理解模型的原理和细节。下图为在扩散模型中的SVC任务,形象地呈现出由一位歌手音色转换为另外一位歌手音色的渐变过程。
![]()