编者按:我们如何才能更好地控制大模型的输出?
本文将介绍几个关键参数,帮助读者更好地理解和运用 temperature、top-p、top-k、frequency penalty 和 presence penalty 等常见参数,以优化语言模型的生成效果。
文章详细解释了这些参数的作用机制以及如何在质量与多样性之间进行权衡。提高 temperature 可以增加多样性但会降低质量。top-p 和 top-k 可以在不损失多样性的前提下提高质量。frequency penalty 和 presence penalty 可以增加回复的词汇多样性和话题多样性。
最后,文章提供了参数配置的具体建议和技巧,供读者参考使用。选择合适的参数能显著提高语言模型的表现,更是进行 prompt engineering 的重要一环。
以下是译文,enjoy!
作者 | Samuel Montgomery
编译 | 岳扬
🚢🚢🚢欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
当我们通过 Playground 或 API 使用语言模型时,可能会被要求选择一些推理参数。但是对大多数人来说,这些参数的含义(以及使用它们的正确方法)可能不为大多数人所熟悉。
![]()
典型模型推理界面参数选择的截图。图片由作者提供
本文将介绍如何使用这些参数来控制大模型的幻觉(hallucinations),为模型的输出注入创造力,并进行其他细粒度的调整,主要目的是为了优化模型的输出。就像提示工程(prompt engineering)一样,对推理参数进行调优可以使模型发挥出最佳效果。
通过学习本文,我相信各位读者能够充分理解这五个关键的推理参数——temperature、top-p、top-k、frequency penalty 和 presence penalty。还可以明白这些参数对生成内容的质量和多样性产生的影响。
所以,泡好咖啡了吗?现在开始吧!
目录
01 背景信息 Background
02 质量、多样性和Temperature
03 Top-k和Top-p
04 频率惩罚和存在惩罚 Frequency and Presence Penalties
05 参数调整备忘单
06 总结
01 背景信息 Background
在选择推理参数之前,我们需要了解一些背景信息。让我们来谈谈这些模型是如何选择要生成哪些单词的。
要阅读一份文档,语言模型会将其分解为一系列的tokens。token只是模型能够轻松理解的一小段文本:可以是一个单词(word)、一个音节(syllable)或一个字符(character)。例如,“Megaputer Intelligence Inc.” 可以被分解为五个token:[“Mega”, “puter”, “Intelligence”, “Inc”, “.”]。
我们熟悉的大多数语言模型都是通过重复生成token序列(sequence)中的下一个token来运作的。每次模型想要生成另一个token时,会重新阅读整个token序列并预测接下来应该出现的token。 这种策略被称为自回归生成(autoregressive generation)。
![]()
token的自回归生成。
GIF由Echo Lu[1]制作,其中包含了 Annie Surla[2]的一张图片(来自 NVIDIA[3],经过修改)。
本次修改已获得版权所有者的许可。
这解释了为什么ChatGPT会逐个地输出单词:它在生成内容时就以逐词输出的方式。
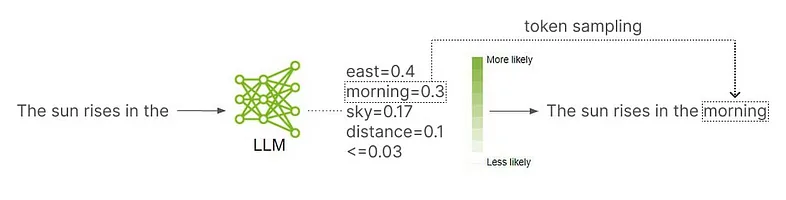
如果要选择序列中的下一个token,语言模型首先要为其词汇表中的每个token分配一个可能性分数(likelihood score)。经过模型的评估,如果某个token能够让文本得到合理的延续,就能够获得较高的可能性分数。如果某个token无法自然延续文本内容,就将获得较低的可能性分数。
![]()
语言模型分配可能性分数,以预测序列中的下一个token。
原始图片由 NVIDIA[3] 的 Annie Surla[2] 创建,经过版权所有者 Echo Lu[1] 的许可进行修改。
在分配完可能性分数(likelihood score)之后,就会使用一种将可能性分数考虑在内的token抽样选择方案(token sampling scheme)来选择token。token抽样选择方案包含一定的随机性,这样语言模型就不会每次都以相同的方式回答相同的问题。这种随机性可以成为聊天机器人或其他应用程序中的一个不错的特性。
简而言之:语言模型将文本分解为token,预测序列中的下一个token,并引入一些随机性。根据需要重复这个过程,来输出内容。
02 质量、多样性和Temperature
但是,为什么我们会想要选择第二好的token、第三好的token,或者除了最好的token以外的其他token呢?难道我们不希望每次都选择最好的token(及具有最高可能性分数的token)吗?通常情况下,我们确实会这样进行。但是,如果我们每次都选择生成最好的回复,那么我们每次都将得到相同的回复。如果我们想要得到多种多样的回复,我们可能不得不放弃一些回复内容的质量来获得回复的多样性。这种为了多样性而牺牲质量的做法被称为质量与多样性的权衡(quality-diversity tradeoff)。
在这种情况下,temperature这个参数可以告诉机器如何在质量和多样性之间进行权衡。较低的 temperature 意味着更高的质量,而较高的 temperature 意味着更高的多样性。当 temperature 设置为零时,模型总是会选择具有最高可能性分数的token,从而导致模型生成的回复缺乏多样性,但却能确保总是选择模型评估出的最高质量的token来生成回复。
很多时候,我们都希望将 temperature 设置为零。原则上,对于只需要向模型传递一次的任何提示语,都应该将 temperature 设置为零,因为这样最有可能得到一个高质量的回复。在我进行的数据分析工作中,对于实体提取(entity extraction)、事实提取(fact extraction)、情感分析(sentiment analysis)和大多数其他标准任务都设置temperature 为零。
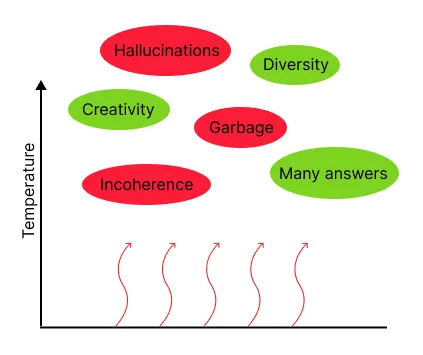
在较高的 temperature 下,通常会看到更多的垃圾内容和幻觉内容,连贯性较差,生成的回复质量可能会降低,但同时也会看到更多具有创造性和多样性的回复。我们建议仅在需要获得多个不同答案的情况下,才使用非零的 temperature。
![]()
较高的 temperature 带来了回答的多样性和创造性,但也会增加垃圾内容、不连贯和幻觉。
图片由Echo Lu[1]创建。
为什么我们会希望对同一个提示语(prompt)获得两个不同的回答呢?在某些情况下,对同一个提示语生成多个回复并仅保留最佳回复可能是比较好的。例如,有一种技术可以让我们对一个提示语生成多个回复,并只保留最好的回复,这通常会比在 temperature 为零时的单个查询产生更好的结果。另一个使用场景是生成人工合成的数据:我们会希望有许多不同的合成数据点(synthetic data points),而不仅是只有一个非常好的数据点(data point)。可能会在以后的文章中讨论这种情况(以及其他情况),但更常见的情况是,我们只希望每个提示语有一个回复。当你不确定应该如何选择 temperature 时,选择 temperature 为零通常是一个安全的选择。
需要注意的是,虽然理论上 temperature 为零应该每次产生相同的答案,但在实践中可能并非如此! 这是因为模型运行在 GPU 上,可能容易出现微小的计算错误,例如四舍五入产生的误差。即使在 temperature 为零的情况下,这些误差会在计算中引入低水平的随机性。由于更改文本中的一个token可能会大大改变文本的含义,一个微小的错误可能会导致文本后序的token选择发生级联变化,从而导致几乎完全不同的输出结果。但请放心,这通常对质量的影响微乎其微。我们提到这一点,只是以免让你在 temperature 为零时输出结果出现一些随机性而感到惊讶。
有很多方法可以让模型在质量和多样性之间进行权衡,而不是仅受 temperature 的影响。在下一节中,我们将讨论对 temperature 选择技术的一些修改。但是,如果您对将 temperature 设置为 0 很满意,可以暂时跳过这部分内容。在 temperature 为零时这些参数不会影响模型的回复,您可以放心地设置。
简而言之:增加 temperature 可以增加模型输出的随机性,从而提高了回复的多样性,但降低了质量。
03 Top-k和Top-p
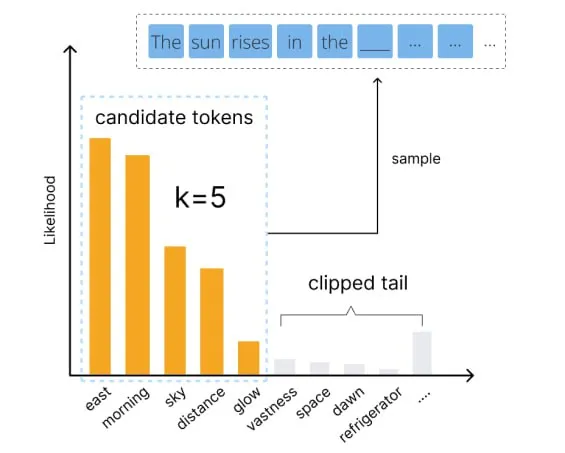
一种常见的调整token选择公式的方法称为 top-k sampling 。top-k sampling 与普通的 temperature sampling 非常相似,只是排除了可能性最低的token:只考虑“前k个”最佳选择,这也是该方法的名称来源。这种方法的优点是防止我们选择到真正糟糕的token。
例如,假设我们要补全 “The sun rises in the…(太阳升起在…)” 这个句子。那么,在没有 top-k sampling 的情况下,模型会将词汇表中的每个token都视为可以放置在序列之后的可能结果。然后,就会有一定的概率写出一些荒谬的内容,比如“The sun rises in the refrigerator.(太阳升起在冰箱里)”。通过进行 top-k sampling ,模型会筛选这些真正糟糕的选择,只考虑前k个最佳token。通过截断大部分糟糕的token,我们会失去一些内容多样性,但是内容的质量会大幅提高。
![]()
Top-k sampling 只保留 k 个最佳候选token,而丢弃其他token,从而提高内容质量。图片由 Echo Lu 提供[1]。
top-p sampling是一种既能保证输出内容多样性,又能在保持内容质量的成本上比单纯使用 temperature 更加低的方法。由于这种技术非常有效,因此激发了许多方法变体的出现。
有一种常见的 top-k sampling 变体被称为 top-p sampling ,也被称为 nucleus sampling 。top-p sampling 与 top-k sampling 非常相似,只是它使用可能性分数(likelihood scores)而不是token排名(token ranks)来决定应保留哪些token。更具体地说,它只考虑那些可能性分数超过阈值p的排名靠前的token,而将其余的token丢弃。
与 top-k sampling 相比,top-p sampling 的优势在有许多较差或平庸的序列后续词时就会显现出来。 例如,假设下一个token只有几个比较好的选择,却有几十个只是隐约挨边的选择。如果我们使用 k=25 的 top-k sampling(译者注:k代表的是保留的token数量) ,我们将考虑许多较差的token选择。相比之下,如果我们使用 top-p sampling 来过滤掉概率分布中最底层的 10%(译者注:将token的可能性概率从大到小排序,只保留从概率最大开始、累积概率之和达到90%为止的tokens),那么我们可能只需要考虑那些分数较高的token,同时过滤掉其他的token。
在实际应用中,与 top-k sampling 相比,top-p sampling 往往能够获得更好的效果。 它能够更加适应输入的上下文,并提供更灵活的筛选。因此,总的来说,top-p和top-k sampling 都可以在非零的 temperature 下使用,以较低的质量成本获取输出内容的多样性,但 top-p sampling 通常效果更好。
小贴士: 对于这两种设置(top-p和top-k sampling),数值越低表示过滤得越多。当设置值为零时,它们将过滤掉除排名靠前的token之外的所有token,这与将 temperature 设置为零具有相同的效果。因此,请在使用这些参数时注意,将这些参数设置得过低可能会减少模型输出内容的多样性。
简而言之:top-k和top-p在几乎不损失输出内容多样性的情况下提高了输出内容的质量。它们通过在随机抽样前去除最差的token选择来实现这一目的。
04 频率惩罚和存在惩罚
Frequency and Presence Penalties
最后,让我们来讨论本文中的最后两个参数:频率惩罚和存在惩罚(frequency and presence penalties)。令人惊讶的是,这些参数是另一种让模型在质量和多样性之间进行权衡的方法。然而,temperature 参数通过在token选择(token sampling)过程中添加随机性来实现输出内容的多样性,而频率惩罚和存在惩罚则通过对已在文本中出现的token施加惩罚以增加输出内容的多样性。这使得对旧的和过度使用的token进行选择变得不太可能,从而让模型选择更新颖的token。
频率惩罚(frequency penalty)让token每次在文本中出现都受到惩罚。这可以阻止重复使用相同的token/单词/短语,同时也会使模型讨论的主题更加多样化,更频繁地更换主题。另一方面,存在惩罚(presence penalty)是一种固定的惩罚,如果一个token已经在文本中出现过,就会受到惩罚。这会导致模型引入更多新的token/单词/短语,从而使其讨论的主题更加多样化,话题变化更加频繁,而不会明显抑制常用词的重复。
就像 temperature 一样,频率惩罚和存在惩罚(frequency and presence penalties)会引导我们远离“最佳的”可能回复,朝着更有创意的方向前进。 然而,它们不像 temperature 那样通过引入随机性,而是通过精心计算的针对性惩罚,为模型生成内容增添多样性在一些罕见的、需要非零 temperature 的任务中(需要对同一个提示语给出多个答案时),可能还需要考虑将小的频率惩罚或存在惩罚加入其中,以提高创造性。但是,对于只有一个正确答案且您希望一次性找到合理回复的提示语,当您将所有这些参数设为零时,成功的几率就会最高。
一般来说,如果只存在一个正确答案,并且您只想问一次时,就应该将频率惩罚和存在惩罚的数值设为零。但如果存在多个正确答案(比如在文本摘要中),在这些参数上就可以进行灵活处理。如果您发现模型的输出乏味、缺乏创意、内容重复或内容范围有限,谨慎地应用频率惩罚或存在惩罚可能是一种激发活力的好方法。但对于这些参数的最终建议与 temperature 的建议相同:在不确定的情况下,将它们设置为零是一个最安全的选择!
需要注意的是,尽管 temperature 和频率惩罚/存在惩罚都能增加模型回复内容的多样性,但它们所增加的多样性并不相同。频率惩罚/存在惩罚增加了单个回复内的多样性,这意味着一个回复会包含比没有这些惩罚时更多不同的词语、短语、主题和话题。但当你两次输入相同的提示语时,并不意味着会更可能得到两个不同的答案。这与 temperature 不同, temperature 增加了不同查询下回复的差异性:在较高的 temperature 下,当多次输入相同的提示语给模型时,会得到更多不同的回复。
我喜欢将这种区别称为回复内多样性(within-response diversity)与回复间多样性(between-response diversity)。temperature 参数同时增加了回复内和回复间的多样性,而频率惩罚/存在惩罚只增加了回复内的多样性。因此,当我们需要增加回复内容的多样性时,参数的选择应取决于我们需要增加哪种多样性。
简而言之:频率惩罚和存在惩罚增加了模型所讨论主题的多样性,并使模型能够更频繁地更换话题。频率惩罚还可以通过减少词语和短语的重复来增加词语选择的多样性。
05 参数调整备忘单
本节旨在为选择模型推理参数提供一份实用指南。首先,该节会提供一些明确的规则,决定将哪些值设为零。然后,会提供了一些tips,帮助读者找到当参数应当为非零时的正确值。
强烈建议您在选择推理参数时使用这张备忘单。现在就将此页面保存为书签,或者收藏本文章~ 以免丢失!
将参数设为零的规则:
temperature:
- 对于每个提示语只需要单个答案:零。
- 对于每个提示语需要多个答案:非零。
频率惩罚和存在惩罚:
- 当问题仅存在一个正确答案时:零。
- 当问题存在多个正确答案时:可自由选择。
Top-p/Top-k:
- 在 temperature 为零的情况下:输出不受影响。
- 在 temperature 不为零的情况下:非零。
如果您使用的语言模型具有此处未列出的其他参数,将其保留为默认值始终是可以的。
当参数非0时,参数调整的技巧:
先列出那些应该设置为非零值的参数,然后去 playground 尝试一些用于测试的提示语,看看哪些效果好。但是,如果上述规则说要将参数值保持为零,则应当将其保持为零!
调整temperature/top-p/top-k的技巧:
- 为了使模型输入内容拥有更多的多样性或随机性,应当增加temperature。
- 在 temperature 非零的情况下,从 0.95 左右的 top-p(或 250 左右的 top-k )开始,根据需要降低 temperature。
Troubleshooting:
- 如果有太多无意义的内容、垃圾内容或产生幻觉,应当降低 temperature 和 降低top-p/top-k。
- 如果 temperature 很高而模型输出内容的多样性却很低,应当增加top-p/top-k。
Tip:虽然有些模型能够让我们同时调整 top-p 和 top-k ,但我更倾向于只调整其中一个参数。top-k 更容易使用和理解,但 top-p 通常更有效。
调整频率惩罚和存在惩罚的技巧:
- 为了获得更多样化的主题,应当增加存在惩罚值。
- 为了获得更多样化且更少重复内容的模型输出,应当增加频率惩罚。
Troubleshooting:
- 如果模型输出的内容看起来零散并且话题变化太快,应当降低存在惩罚。
- 如果有太多新奇和不寻常的词语,或者存在惩罚设置为零但仍然存在很多话题变化,应当降低频率惩罚。
简而言之:可以将本节作为调整语言模型参数的备忘单。您肯定会忘记这些规则,所以立即将此页面加为浏览器书签或加入社区收藏夹,以便以后作为参考。
06 总结
尽管定义token选择策略(token sampling strategy)的方式多种多样,但本文讨论的参数——temperature、top-k、top-p、频率惩罚和存在惩罚——是最为常用的。这些参数在诸如 Claude、Llama 和 GPT 系列等模型中被广泛采用。在本文中,已经说明了,这些参数实际上都是为了帮助我们在模型输出的质量和多样性之间取得平衡。
在结束之前,还有一个推理参数需要提及:最大token长度(maximum token length)。最大token长度即为模型停止输出回复的截止点,即使模型的回复尚未完成。在经历了前文对其他参数进行复杂的讨论后,我希望对这个参数的介绍不言自明。🙂
简而言之:如果对参数的设置有疑问,将temperature、频率惩罚和存在惩罚这些参数的数值设为零。若不起作用,请参考上述速查表。
END
参考资料
[1]https://www.linkedin.com/in/echoxlu/
[2]https://developer.nvidia.com/blog/author/anniesurla/
[3]https://developer.nvidia.com/blog/how-to-get-better-outputs-from-your-large-language-model/
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://towardsdatascience.com/mastering-language-models-32e1d891511a