llama.cpp 是开发者 Georgi Gerganov 用纯 C/C++ 代码实现的 LLaMA 模型推理开源项目。所谓推理,即是「给输入-跑模型-得输出」的模型运行过程。
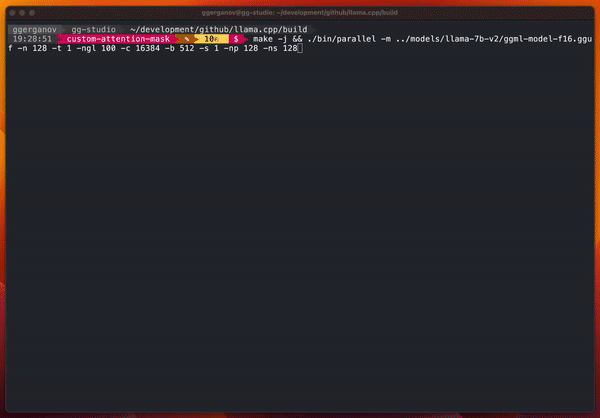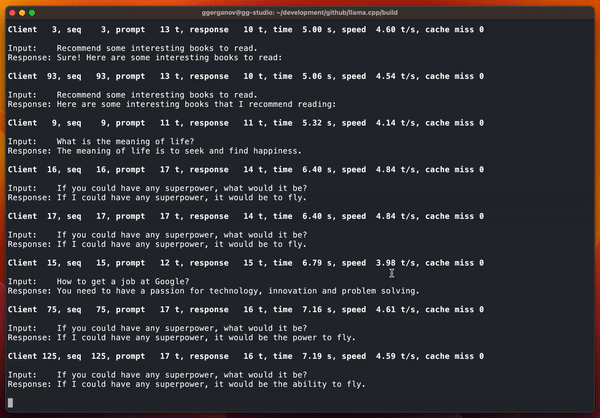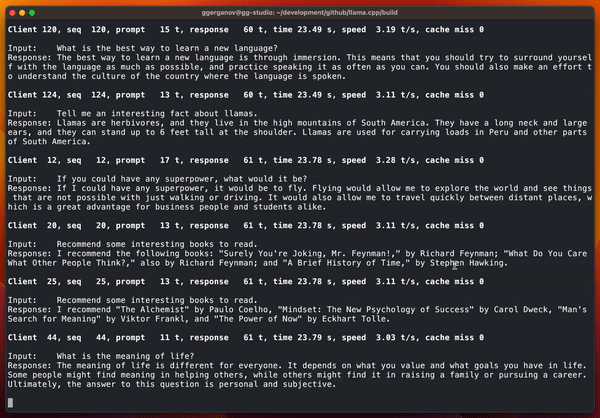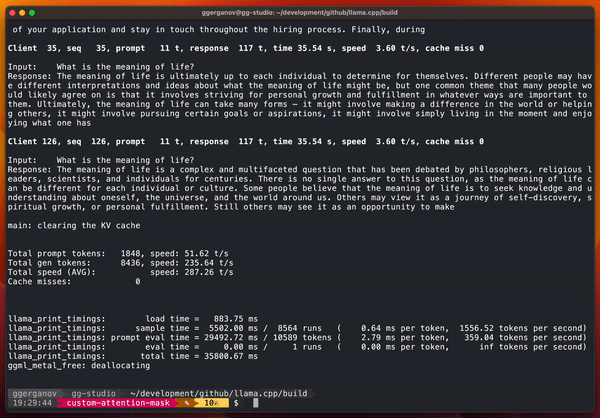
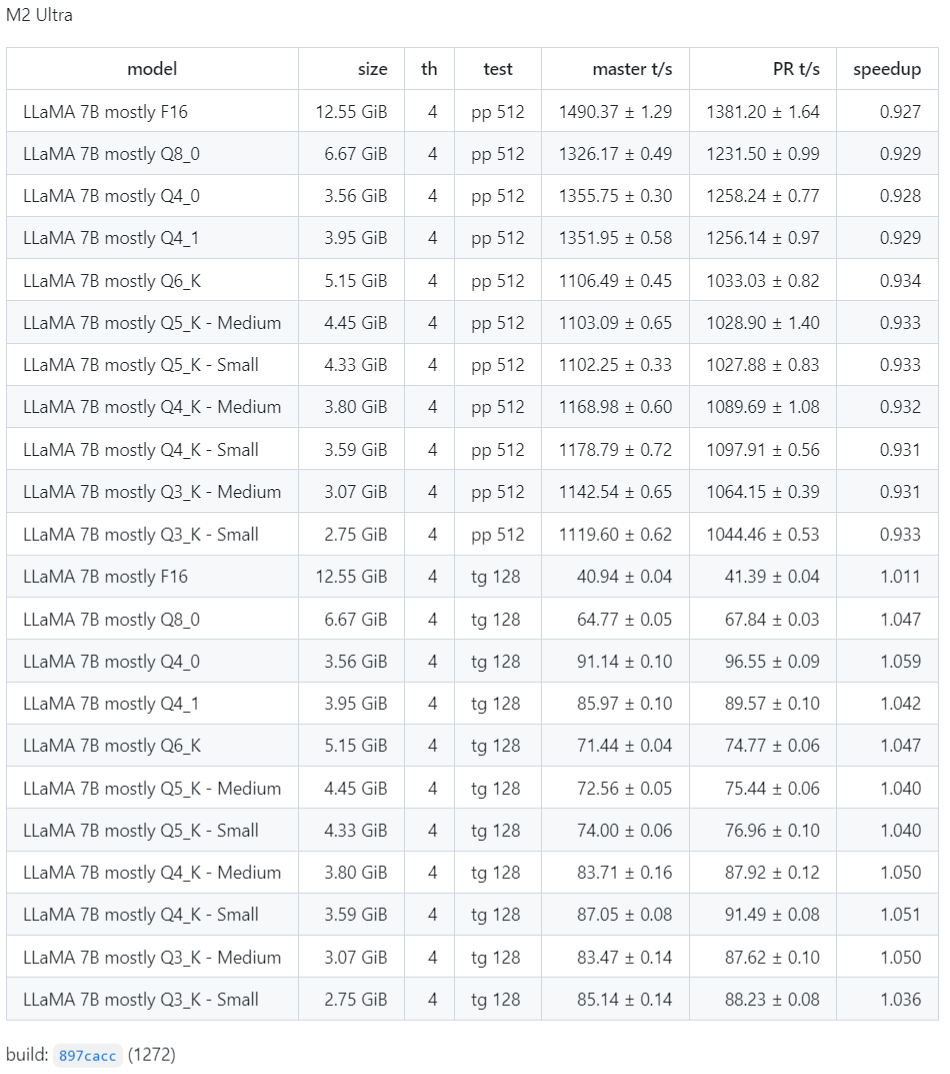
最近 Georgi Gerganov 用搭载苹果 M2 Ultra 处理器的设备运行了一系列测试,其中包括并行运行 128 个 Llama 2 7B 流。
![]()
具体结果如下:
![]()
via https://github.com/ggerganov/llama.cpp/pull/3228
对于 M2 Ultra 的这番表现,有人给出了解释,M2 Ultra 或 M1 和 M2 系列 CPU 的速度之所以如此快,是因为执行推理任务的主要瓶颈是内存带宽,而不是计算能力。
![]()
而 M2 Ultra 的带宽为 800 GB/s,是普通现代台式机 CPU(双通道 DDR4-6400 带宽为 102 GB/s)的 8 倍。
如此高的带宽是苹果为 M1 和 M2 芯片设计了统一内存架构的结果。通常在笔记本电脑或台式机上,CPU 和 GPU 拥有不同的内存系统:高带宽(但容量相对较低)的显存和相对低带宽(但容量较高)的 CPU 内存。
苹果公司简化了这种方案,转而采用 CPU 和 GPU 共享的单一高带宽内存系统。这样做的唯一缺点是,这种高带宽内存必须紧密集成在 M2 封装中,因此最大容量受到限制。
例如,无论你花费 5,600 美元(最便宜的 Mac Studio 机型,配备 M2 Utra 和 192 GB 内存),还是 10,000 美元以上(最顶配 Mac Pro),都只能获得最大 192 GB 内存。但另一方面,如果你的工作负载(如推理)不需要超过 192 GB 的内存,那就再好不过了。
如此看来,苹果在这方面做出了正确的权衡。通常来说,在通用 CPU 的单插槽上实现 800 GB/s 的内存带宽,这在以前从未实现过。